
Python正则表达式如何匹配中文
更新时间:2020年05月27日 10:03:01 作者:百里希文
这篇文章主要介绍了Python正则表达式如何匹配中文,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
用 '[\u4e00-\u9fa5]‘ 匹配中文
在字符串中匹配中文
示例:
匹配字符串中的第一个中文字符

匹配字符串中的第一个连续的中文片段

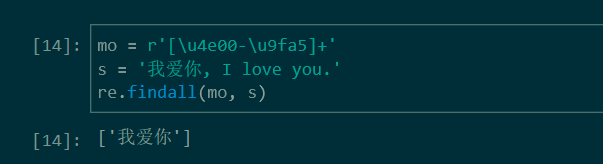
匹配字符串中的所有中文字符

注:要确保正则字符和匹配文本是 unicode 范围内的编码。
其他 扩充 范围
几个主要非英文语系字符范围: 2E80~33FFh:中日韩符号区。收容康熙字典部首、中日韩辅助部首、注音符号、日本假名、韩文音符,中日韩的符号、标点、带圈或带括符文数字、月份,以及日本的假名组合、单位、年号、月份、日期、时间等。 3400~4DFFh:中日韩认同表意文字扩充A区,总计收容6,582个中日韩汉字。 4E00~9FFFh:中日韩认同表意文字区,总计收容20,902个中日韩汉字。 A000~A4FFh:彝族文字区,收容中国南方彝族文字和字根。 AC00~D7FFh:韩文拼音组合字区,收容以韩文音符拼成的文字。 F900~FAFFh:中日韩兼容表意文字区,总计收容302个中日韩汉字。 FB00~FFFDh:文字表现形式区,收容组合拉丁文字、希伯来文、阿拉伯文、中日韩直式标点、小符号、半角符号、全角符号等。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达2021-11-11
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达2021-11-11 这篇文章主要介绍了Python实战之能监控文件变化的神器—看门狗,文中有非常详细的图文及代码示例,对正在学习python的小伙伴们有非常好的帮助,需要的朋友可以参考下2021-05-05
这篇文章主要介绍了Python实战之能监控文件变化的神器—看门狗,文中有非常详细的图文及代码示例,对正在学习python的小伙伴们有非常好的帮助,需要的朋友可以参考下2021-05-05 这篇文章主要介绍了Python中的join()方法的使用,是Python入门中的基础知识,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了Python中的join()方法的使用,是Python入门中的基础知识,需要的朋友可以参考下2015-05-05
python tkinter控件treeview的数据列表显示的实现示例
本文主要介绍了python tkinter控件treeview的数据列表显示的实现示例,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01 这篇文章主要介绍了python中的type,元类,类,对象用法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-05-05
这篇文章主要介绍了python中的type,元类,类,对象用法,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-05-05 这篇文章主要为大家详细介绍了python实现K折交叉验证,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-04-04
这篇文章主要为大家详细介绍了python实现K折交叉验证,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-04-04
Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式
这篇文章主要介绍了Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05 Python是一门独特的语言,与C语言有很大区别,初学Python很多萌新表示对变量与赋值不理解,这里就大家介绍一下,需要的朋友可以参考下2018-04-04
Python是一门独特的语言,与C语言有很大区别,初学Python很多萌新表示对变量与赋值不理解,这里就大家介绍一下,需要的朋友可以参考下2018-04-04 下面小编就为大家分享一篇python爬虫_实现校园网自动重连脚本的教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇python爬虫_实现校园网自动重连脚本的教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
Django debug为True时,css加载失败的解决方案
这篇文章主要介绍了Django debug为True时,css加载失败的解决方案,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-04-04










最新评论