
用pushplus+python监控亚马逊到货动态推送微信
xbox series和ps5发售以来,国内黄牛价格一直居高不下。虽然海外amazon上ps5补货很少而且基本撑不过一分钟,但是xbox series系列明显要好抢很多。
日亚、德亚的xbox series x/s都可以直邮中国大陆,所以我们只需要借助脚本,监控相关网页的动态,在补货的第一时刻通过微信告知我们,然后迅速人工购买即可!
需求:pushplus(需要微信关注公众号)、python3
一、pushplus相关介绍
pushplus提供了免费的微信消息推送api,具体内容可以参考他的官网:pushplus(推送加)微信推送消息直达 (hxtrip.com)
我们需要用到的东西有,登陆后的个人Token(用于精准推送消息),如图:
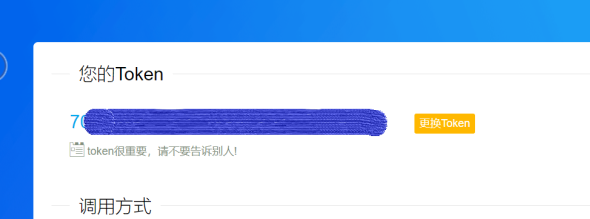
调用该接口可使用如下代码,token为上面提到的你个人的token,titile对应推送标题,content对应推送内容,此代码借鉴了官方demo
def post_push(token, title, content):
url = 'http://pushplus.hxtrip.com/send'
data = {
"token": token,
"title": title,
"content": content
}
body = json.dumps(data).encode(encoding='utf-8')
headers = {'Content-Type': 'application/json'}
requests.post(url, data=body, headers=headers)
二、整体思路
不出意外的话,你在编写代码时,amazon应该处于无货状态(有货直接就买了啊喂)!!!我们在此时打开amazon页面,可以看到如下界面:
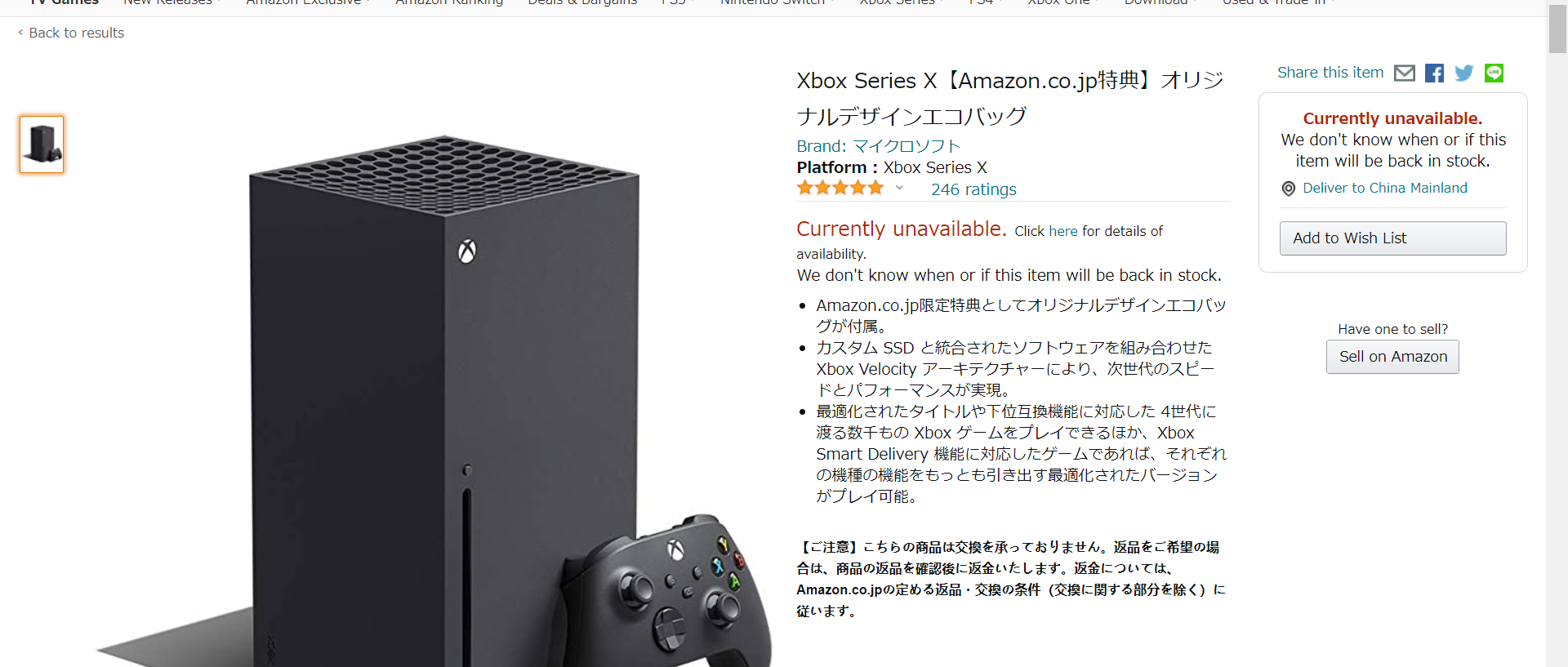
在新版Edge浏览器或者chrome下,按F12查看网页源码,选定中间Currently unavailable标识的区域(五颗星下面那个,最好覆盖范围大一点),能看到代码如下:
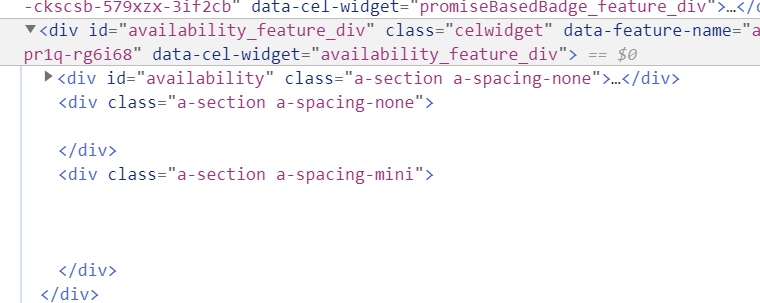
有一个比较简单的办法,判断amazon是否有补货。我们可以抓取这一部分的html源码,存进一个文件里(txt即可)。每过一定时间,重新抓取源码,如果这些源码变化了,那么基本上是网站更新了(补货了)。不过有个小瑕疵,这种补货也可能是亚马逊第三方(黄牛)补货- -
不过总归是有了一个判断上新的方法嘛;其实黄牛补货很少的,德亚上好像看不到黄牛(我个人没见过德亚上的第三方卖xsx的),日亚上基本没有啥黄牛卖xbox
好了,接下来,我们看看如何实现相关功能
三、Requests+BeautifulSoup获取相关html源码
我们使用Requests+BeautfifulSoup来抓取<div id = 'availability_feature_div> </div>这个标签内部的所有html源码
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 9; SM-A102U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36",
'Content-Type': 'application/json'
}
html = requests.get(url=self.url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
html.close()
target = str(soup.find('div', id='availability_feature_div'))
注意如果不加headers的话,amazon会检测到爬虫,不会给你返回完整html代码。第7行把requests给close掉是因为,我在监测时开了两个线程同时检测日亚和德亚,如果不加这一句的话,会被amazon认为是我在攻击网站,会拒绝我的网络访问
最终的target是被转为str格式的相应html源码,接下来只需要将其保存到文件,每隔一定时间再次爬虫比对就行了
四、完整代码
import json
import requests
from bs4 import BeautifulSoup
import filecmp
import time
import threading
class listenThread(threading.Thread):
def __init__(self, url, originFile, newFile, content):
threading.Thread.__init__(self)
self.url = url
self.originFile = originFile
self.newFile = newFile
self.content = content
def listen(self):
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 9; SM-A102U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36",
'Content-Type': 'application/json'
}
html = requests.get(url=self.url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
html.close()
target = str(soup.find('div', id='availability_feature_div'))
filetxt = open(self.originFile, 'w', encoding='utf-8')
filetxt.write(target)
filetxt.close()
while True:
target = str(soup.find('div', id='availability_feature_div'))
filetxt = open(self.newFile, 'w', encoding='utf-8')
filetxt.write(target)
filetxt.close()
if filecmp.cmp(self.originFile, self.newFile) == False:
post_push('这里输你自己的token', 'xbox update', self.content)
fileAvail = open(self.originFile, 'w')
fileAvail.write(target)
fileAvail.close()
time.sleep(30)
def run(self):
self.listen()
def post_push(token, title, content):
url = 'http://pushplus.hxtrip.com/send'
data = {
"token": token,
"title": title,
"content": content
}
body = json.dumps(data).encode(encoding='utf-8')
headers = {'Content-Type': 'application/json'}
requests.post(url, data=body, headers=headers)
if __name__ == '__main__':
detect_url = 'https://www.amazon.co.jp/-/en/dp/B08GGKZ34Z/ref=sr_1_2?dchild=1&keywords=xbox&qid=1611674118&sr=8-2'
#url_special = 'https://www.amazon.co.jp/-/en/dp/B08GG17K5G/ref=sr_1_6?dchild=1&keywords=xbox%E3%82%B7%E3%83%AA%E3%83%BC%E3%82%BAx&qid=1611722050&sr=8-6'
url_germany = 'https://www.amazon.de/Microsoft-RRT-00009-Xbox-Series-1TB/dp/B08H93ZRLL/ref=sr_1_2?__mk_de_DE=%C3%85M%C3%85%C5%BD%C3%95%C3%91&dchild=1&keywords=xbox&qid=1611742161&sr=8-2'
xbox = listenThread(url=detect_url,originFile='avail.txt',newFile='avail_now.txt',content='日亚')
#xbox_sp = listenThread(url=detect_url,originFile='avail_sp.txt',newFile='avail_now_sp.txt')
xbox_germany = listenThread(url=url_germany,originFile='avail_sp.txt',newFile='avail_now_sp.txt',content='德亚')
xbox.start()
#xbox_sp.start()
xbox_germany.start()
本代码开了两个线程分别监控日亚和德亚的xsx,detect_url是日亚链接,url_germany是德亚链接;
注意:德亚能够直接上,日亚如果你上不去自己想办法(不能说的东西,你懂的)
里面OriginFile和NewFile的文件名可以随意命名,OriginFile指的是之前爬虫的html,NewFile是新的爬虫html,如果内容不一样,就会收到微信消息推送啦
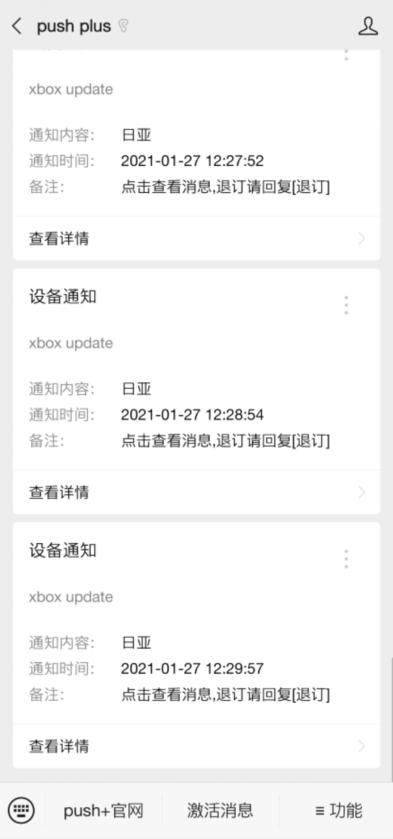
这个图只是测试用的,这个时刻日亚也没有真的补货哈哈哈
以上就是用pushplus+python监控亚马逊到货动态推送微信的详细内容,更多关于pushplus+python监控亚马逊到货动态的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了使用python实现excel的Vlookup功能,当我们想要查找的数据量较大时,这时则有请我们的主角VLookup函数出场,那么如何用python实现VLookup呢,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了使用python实现excel的Vlookup功能,当我们想要查找的数据量较大时,这时则有请我们的主角VLookup函数出场,那么如何用python实现VLookup呢,需要的朋友可以参考下2023-04-04 在本文里我们给大家分析那个了关于python三引号输出方法以及相关知识点,需要的朋友们学习下。2019-02-02
在本文里我们给大家分析那个了关于python三引号输出方法以及相关知识点,需要的朋友们学习下。2019-02-02 这篇文章主要介绍了Django框架安装及项目创建过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09
这篇文章主要介绍了Django框架安装及项目创建过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09
Python模块psycopg2连接postgresql的实现
本文主要介绍了Python模块psycopg2连接postgresql的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-07-07 本文介绍了Python实现图像和办公文档处理的方法和技巧,包括使用Pillow库处理图像、使用OpenCV库进行图像识别和处理、使用PyPDF2库处理PDF文档、使用docx和xlwt库处理Word和Excel文档等,帮助读者更好地掌握Python在图像和办公文档处理方面的应用2023-05-05
本文介绍了Python实现图像和办公文档处理的方法和技巧,包括使用Pillow库处理图像、使用OpenCV库进行图像识别和处理、使用PyPDF2库处理PDF文档、使用docx和xlwt库处理Word和Excel文档等,帮助读者更好地掌握Python在图像和办公文档处理方面的应用2023-05-05 随着业务的增长,后端技术架构会慢慢的从单体服务转向多服务或者微服务的分布式架构,本文主要为大家介绍了如何利用Py-Redis实现简单的分布式锁,需要的可以参考一下2023-08-08
随着业务的增长,后端技术架构会慢慢的从单体服务转向多服务或者微服务的分布式架构,本文主要为大家介绍了如何利用Py-Redis实现简单的分布式锁,需要的可以参考一下2023-08-08 下面小编就为大家带来一篇Python爬虫DOTA排行榜爬取实例(分享)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-06-06
下面小编就为大家带来一篇Python爬虫DOTA排行榜爬取实例(分享)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-06-06 这篇文章主要介绍了Pyqt助手安装PyQt5帮助文档过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了Pyqt助手安装PyQt5帮助文档过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11 在使用 Python 开发时,建议在开发环境和生产环境下都使用虚拟环境来管理项目的依赖,下面这篇文章主要给大家介绍了关于Python安装及建立虚拟环境的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06
在使用 Python 开发时,建议在开发环境和生产环境下都使用虚拟环境来管理项目的依赖,下面这篇文章主要给大家介绍了关于Python安装及建立虚拟环境的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06 阈值处理是一种简单、有效的将图像划分为前景和背景的方法。图像分割通常用于根据对象的某些属性(例如,颜色、边缘或直方图)从背景中提取对象。本文将为大家详细介绍OpenCV中的阈值处理,需要的可以参考一下2022-02-02
阈值处理是一种简单、有效的将图像划分为前景和背景的方法。图像分割通常用于根据对象的某些属性(例如,颜色、边缘或直方图)从背景中提取对象。本文将为大家详细介绍OpenCV中的阈值处理,需要的可以参考一下2022-02-02










最新评论