
Python用requests库爬取返回为空的解决办法
更新时间:2021年02月21日 14:38:46 作者:qq_38796636
这篇文章主要介绍了Python用requests库爬取返回为空的解决办法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
首先介紹一下我們用360搜索派取城市排名前20。
我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html
我们要爬取的内容:
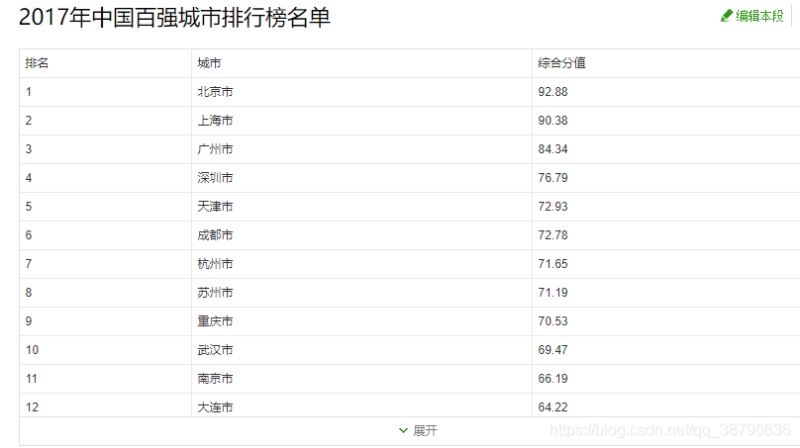
html字段:

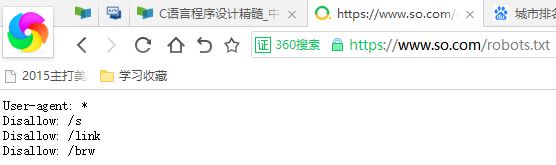
robots协议:
现在我们开始用python IDLE 爬取

import requests
r = requests.get("https://baike.so.com/doc/24368318-25185095.html")
r.status_code
r.text
结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。
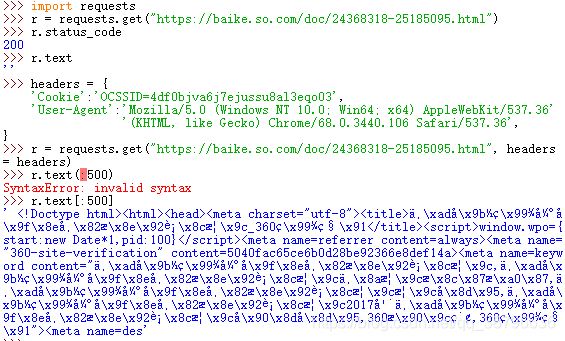
输出有个小插曲,网页内容很多,我是想将前500个字符输出,第一次格式错了
import requests
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.text
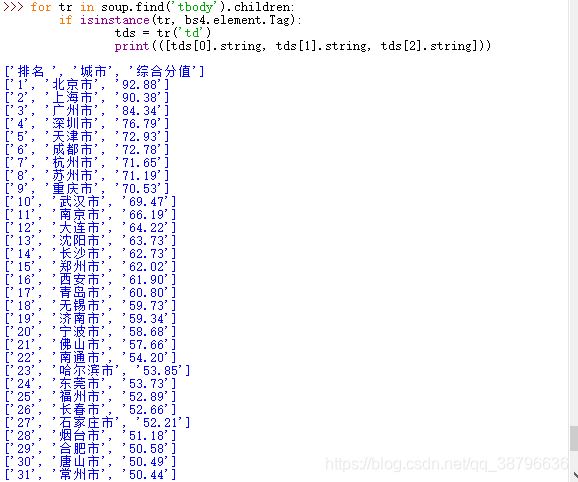
接着我们对需要的内容进行爬取,用(.find)方法找到我们内容位置,用(.children)下行遍历的方法对内容进行爬取,用(isinstance)方法对内容进行筛选:
import requests
from bs4 import BeautifulSoup
import bs4
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
print([tds[0].string, tds[1].string, tds[2].string])
得到结果如下:
修改输出的数目,我们用Clist列表来存取所有城市的排名,将前20个输出代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
Clist = list() #存所有城市的列表
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.encoding = r.apparent_encoding #将html的编码解码为utf-8格式
soup = BeautifulSoup(r.text, "html.parser") #重新排版
for tr in soup.find('tbody').children: #将tbody标签的子列全部读取
if isinstance(tr, bs4.element.Tag): #筛选tb列表,将有内容的筛选出啦
tds = tr('td')
Clist.append([tds[0].string, tds[1].string, tds[2].string])
for i in range(21):
print(Clist[i])
最终结果:
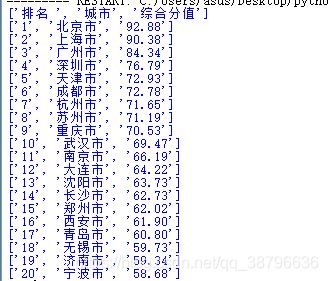
到此这篇关于Python用requests库爬取返回为空的解决办法的文章就介绍到这了,更多相关Python requests返回为空内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家介绍了Python中最强大的重试库Tenacity使用探索,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12
这篇文章主要为大家介绍了Python中最强大的重试库Tenacity使用探索,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12 这篇文章主要介绍了Python运行错误异常代码含义对照表,需要的朋友可以参考下2021-04-04
这篇文章主要介绍了Python运行错误异常代码含义对照表,需要的朋友可以参考下2021-04-04
Keras 数据增强ImageDataGenerator多输入多输出实例
这篇文章主要介绍了Keras 数据增强ImageDataGenerator多输入多输出实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-07-07 这篇文章主要介绍了python 实现format进制转换与删除进制前缀的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03
这篇文章主要介绍了python 实现format进制转换与删除进制前缀的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03 字典由多个键和其对应的值构成的键—值对组成,键和值中间以冒号:隔开,项之间用逗号隔开,整个字典是由大括号{}括起来的,下面这篇文章主要给大家介绍了关于如何利用For循环遍历Python字典的三种方法,需要的朋友可以参考下2022-03-03
字典由多个键和其对应的值构成的键—值对组成,键和值中间以冒号:隔开,项之间用逗号隔开,整个字典是由大括号{}括起来的,下面这篇文章主要给大家介绍了关于如何利用For循环遍历Python字典的三种方法,需要的朋友可以参考下2022-03-03 今天小编就为大家分享一篇解决python3 urllib 链接中有中文的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07
今天小编就为大家分享一篇解决python3 urllib 链接中有中文的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07 在传统的工作中,发送会议纪要是一个比较繁琐的任务,需要手动输入邮件内容、收件人、抄送人等信息,每次发送都需要重复操作,不仅费时费力,而且容易出现疏漏和错误。本文就来用Python代码实现这一功能吧2023-05-05
在传统的工作中,发送会议纪要是一个比较繁琐的任务,需要手动输入邮件内容、收件人、抄送人等信息,每次发送都需要重复操作,不仅费时费力,而且容易出现疏漏和错误。本文就来用Python代码实现这一功能吧2023-05-05 这篇文章主要介绍了基于python图书馆管理系统设计实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了基于python图书馆管理系统设计实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08 这篇文章主要介绍了Python复数属性和方法运算操作,结合实例形式分析了Python复数运算相关操作技巧,代码注释备有详尽说明,需要的朋友可以参考下2017-07-07
这篇文章主要介绍了Python复数属性和方法运算操作,结合实例形式分析了Python复数运算相关操作技巧,代码注释备有详尽说明,需要的朋友可以参考下2017-07-07 这篇文章主要为大家详细介绍了python实现图片数据增强的相关知识,文中的示例代码讲解详细,具有一定的学习价值,感兴趣的小伙伴可以跟随小编一起了解一下2023-10-10
这篇文章主要为大家详细介绍了python实现图片数据增强的相关知识,文中的示例代码讲解详细,具有一定的学习价值,感兴趣的小伙伴可以跟随小编一起了解一下2023-10-10










最新评论