
python爬虫之bs4数据解析
更新时间:2021年04月26日 10:45:09 作者:世界的隐喻
这篇文章主要介绍了python爬虫之bs4数据解析,文中有非常详细的代码示例,对正在学习python爬虫的小伙伴们有非常好的帮助,需要的朋友可以参考下
一、实现数据解析
因为正则表达式本身有难度,所以在这里为大家介绍一下 bs4 实现数据解析。除此之外还有 xpath 解析。因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义)。以后的重点会在 xpath 上。
二、安装库
闲话少说,我们先来安装 bs4 相关的外来库。比较简单。
1.首先打开 cmd 命令面板,依次安装bs4 和 lxml。
2. 命令分别是 pip install bs4 和 pip install lxml 。
3. 安装完成后我们可以试着调用他们,看看会不会报错。
因为本人水平有限,所以如果出现报错,兄弟们还是百度一下好啦。(总不至于 cmd 命令打错了吧 ~~)
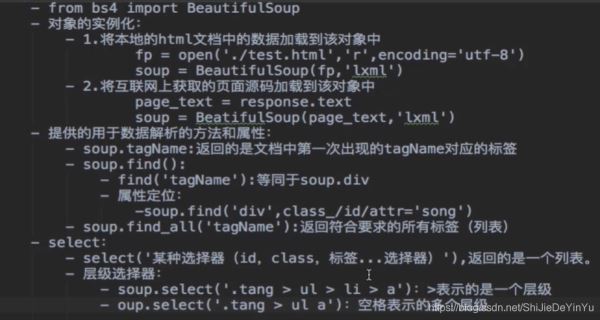
三、bs4 的用法
闲话少说,先简单介绍一下 bs4 的用法。

四、爬取图片
import requests
from bs4 import BeautifulSoup
import os
if __name__ == "__main__":
# 创建文件夹
if not os.path.exists("./糗图(bs4)"):
os.mkdir("./糗图(bs4)")
# UA伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
for i in range(1, 3): # 翻两页
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(i)
# 获取源码数据
page = requests.get(url = url, headers = header).text
# 数据解析
soup = BeautifulSoup(page, "lxml")
data_list = soup.select(".thumb > a")
for data in data_list:
url = data.img["src"]
title = url.split("/")[-1]
new_url = "https:" + url
photo = requests.get(url = new_url, headers = header).content
# 存储
with open("./糗图(bs4)/" + title, "wb") as fp:
fp.write(photo)
print(title, "下载完成!!!")
print("over!!!")
五、爬取三国演义
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# UA 伪装
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# URL
url = "http://sanguo.5000yan.com/"
# 请求命令
page_text = requests.get(url = url, headers = header)
page_text.encoding = "utf-8"
page_text = page_text.text
soup = BeautifulSoup(page_text, "lxml")
# bs4 解析
li_list = soup.select(".sidamingzhu-list-mulu > ul > li")
for li in li_list:
print(li)
new_url = li.a["href"]
title = li.a.text
# 新的请求命令
response = requests.get(url = new_url, headers = header)
response.encoding = "utf-8"
new_page_text = response.text
new_soup = BeautifulSoup(new_page_text, "lxml")
page = new_soup.find("div", class_ = "grap").text
with open("./三国演义.txt", "a", encoding = "utf-8") as fp:
fp.write("\n" + title + ":" + "\n" + "\n" + page)
print(title + "下载完成!!!")
到此这篇关于python爬虫之bs4数据解析的文章就介绍到这了,更多相关python bs4数据解析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 isalnum()函数是Python中的一个内置函数,用于判断字符串是否只由数字和字母组成,其内部实现原理比较简单,只需遍历字符串中的每一个字符即可,这篇文章主要介绍了Python函数isalnum用法介绍,需要的朋友可以参考下2024-01-01
isalnum()函数是Python中的一个内置函数,用于判断字符串是否只由数字和字母组成,其内部实现原理比较简单,只需遍历字符串中的每一个字符即可,这篇文章主要介绍了Python函数isalnum用法介绍,需要的朋友可以参考下2024-01-01 这篇文章主要为大家详细介绍了python爬虫爬取网页表格数据,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
这篇文章主要为大家详细介绍了python爬虫爬取网页表格数据,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03 这篇文章主要为大家详细介绍了Python3实现汉语转换为汉语拼音,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-07-07
这篇文章主要为大家详细介绍了Python3实现汉语转换为汉语拼音,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-07-07 这篇文章主要介绍了Pycharm中的Python Console用法解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01
这篇文章主要介绍了Pycharm中的Python Console用法解读,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-01-01 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。但目前pymysql支持python3.x而后者不支持3.x版本。2019-08-08
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。但目前pymysql支持python3.x而后者不支持3.x版本。2019-08-08 这篇文章主要介绍了Python实现常见的回文字符串算法,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-11-11
这篇文章主要介绍了Python实现常见的回文字符串算法,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-11-11 Python中的字典和集合是非常相似的数据类型,字典是无序的键值对。集合中的数据是不重复的,并且不能通过索引去修改集合中的值,我们可以往集合中新增或者修改数据。集合是无序的,并且支持数学中的集合运算,例如并集和交集等。2021-06-06
Python中的字典和集合是非常相似的数据类型,字典是无序的键值对。集合中的数据是不重复的,并且不能通过索引去修改集合中的值,我们可以往集合中新增或者修改数据。集合是无序的,并且支持数学中的集合运算,例如并集和交集等。2021-06-06 这篇文章主要介绍了Django查找网站项目根目录和对正则表达式的支持,仅供参考,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了Django查找网站项目根目录和对正则表达式的支持,仅供参考,需要的朋友可以参考下2015-07-07
python 截取XML中bndbox的坐标中的图像,另存为jpg的实例
这篇文章主要介绍了python 截取XML中bndbox的坐标中的图像,另存为jpg的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03![详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据](//img.jbzj.com/images/xgimg/bcimg9.png)
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
这篇文章主要介绍了pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12









![详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据](http://img.jbzj.com/images/xgimg/bcimg9.png)
最新评论