
pycharm利用pyspark远程连接spark集群的实现
0 背景
由于工作需要,利用spark完成机器学习。因此需要对spark集群进行操作。所以利用pycharm和pyspark远程连接spark集群。这里记录下遇到的问题及方法。
主要是参照下面的文献完成相应的内容,但是具体问题要具体分析。
1 方法
1.1 软件配置
spark2.3.3, hadoop2.6, python3
1.2 spark配置
Spark集群的每个节点的Python版本必须保持一致。在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你的安装目录。
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python3
此步骤就是将python添加到spark的配置中。
此时,在服务器命令行输入pyspark时,可以正常进入spark。
1.3本地配置
1.3.1 首先将spark2.3.3从服务器拷贝到本地。
注意: 由于我集群安装的是spark-2.3.3-bin-without-hadoop。但是拷贝到本地后,总是报错Java gateway process… 。同时我将hadoop2.6,的包也从服务器拷贝到本地加载到程序中,同样报错。
最后,直接从spark的官网中,下载了spark-2.3.3-bin-hadoop2.6,这回就可以了。
pyspark的版本与spark的版本最好对应。比如pyspark2.3.3,spark2.3.3
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"(无用) os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"(有用) # os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"(无用) # os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"(无用)
1.3.2
C:\Windows\System32….\hosts(Windows机器)中加入Spark集群Master节点的IP与主机名的映射。需要管理员权限修改。

其中的spark_cluster就是对于Master的IP的映射名。(直接写IP一样可以,映射名是为了方便)
1.3.3
添加刚刚下载解压好的spark的python目录到pycharm的project structure
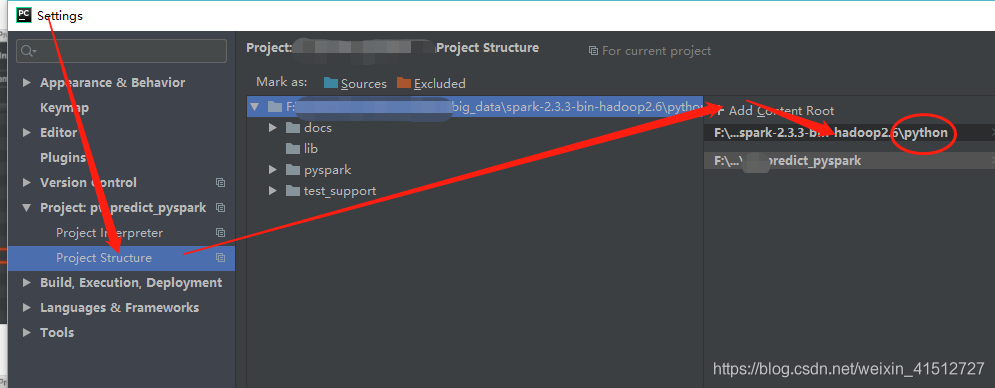
1.3.4
新建py文件,编辑Edit Configurations添加SPARK_HOME变量
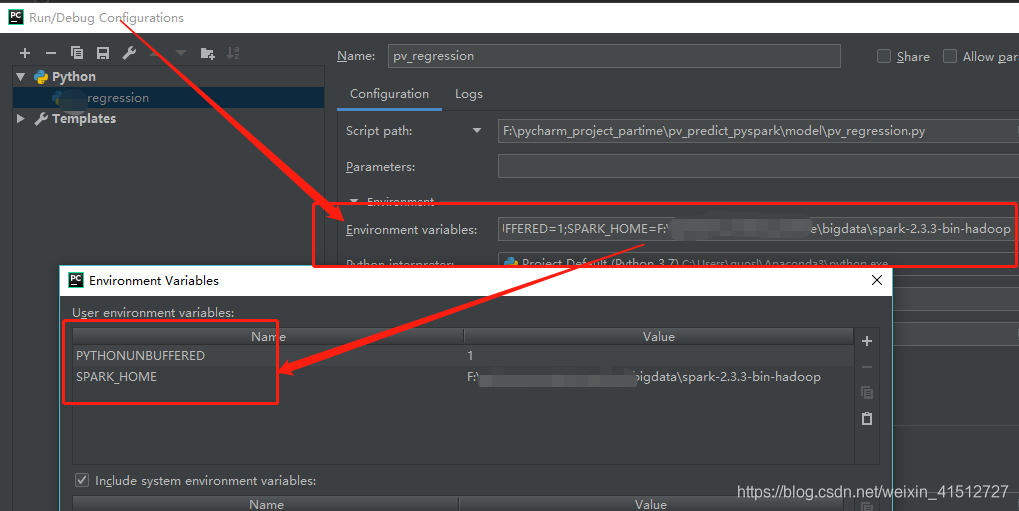
注意: 在实际中,这个不添加好像也可以。只需要在程序中加载了spark_home.比如os.envion(…spark…)
2 测试
import os
from pyspark import SparkContext
from pyspark import SparkConf
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"
print(0)
conf = SparkConf().setMaster("spark://spark_cluster:7077").setAppName("test")
sc = SparkContext(conf=conf)
print(1)
logData = sc.textFile("file:///opt/spark-2.3.3-bin-without-hadoop/README.md").cache()
print(2)
print("num of a",logData)
sc.stop()

3 参考
PyCharm+PySpark远程调试的环境配置的方法
Spark下:Java gateway process exited before sending the driver its port number等问题
估计每个人遇到的问题不一样,但是大同小异,具体问题具体分析。
到此这篇关于pycharm利用pyspark远程连接spark集群的实现的文章就介绍到这了,更多相关pyspark远程连接spark集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 python中,json和dict非常类似,都是key-value的形式,而且json、dict也可以非常方便的通过dumps、loads互转。这篇文章主要介绍了python中的json、字典dict,需要的朋友可以参考下2018-06-06
python中,json和dict非常类似,都是key-value的形式,而且json、dict也可以非常方便的通过dumps、loads互转。这篇文章主要介绍了python中的json、字典dict,需要的朋友可以参考下2018-06-06 这篇文章主要介绍了Python实现扣除个人税后的工资计算器,涉及Python流程控制与数学运算相关操作技巧,需要的朋友可以参考下2018-03-03
这篇文章主要介绍了Python实现扣除个人税后的工资计算器,涉及Python流程控制与数学运算相关操作技巧,需要的朋友可以参考下2018-03-03
Windows下python3安装tkinter的问题及解决方法
这篇文章主要介绍了Windows下python3安装tkinter问题及解决方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01 dataframe是pandas包的重要对象,熟练掌握dataframe的基本操作是很有必要的,下面这篇文章主要给大家介绍了关于pandas中提取DataFrame某些列的一些方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06
dataframe是pandas包的重要对象,熟练掌握dataframe的基本操作是很有必要的,下面这篇文章主要给大家介绍了关于pandas中提取DataFrame某些列的一些方法,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-06-06 这篇文章主要给大家介绍了关于Python requests库参数提交的注意事项,文中通过示例代码和图片介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要给大家介绍了关于Python requests库参数提交的注意事项,文中通过示例代码和图片介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
python使用wmi模块获取windows下硬盘信息的方法
这篇文章主要介绍了python使用wmi模块获取windows下硬盘信息的方法,涉及Python获取系统硬件信息的相关技巧,需要的朋友可以参考下2015-05-05 这篇文章主要为大家介绍了python 的while循环嵌套,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12
这篇文章主要为大家介绍了python 的while循环嵌套,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12 在本篇内容里小编给大家分析了关于python和php学习哪个更有发展相关论点,有兴趣的朋友们参考下。2020-06-06
在本篇内容里小编给大家分析了关于python和php学习哪个更有发展相关论点,有兴趣的朋友们参考下。2020-06-06 PIL(Python Imaging Library)是一个非常强大的Python库,但是它支持Python2.X, 在Python3中则使用的是Pillow库,它是从PIL中fork出来的一个分支。这篇文章主要介绍了用Python搞定九宫格式的朋友圈功能内附“马云”朋友圈 ,需要的朋友可以参考下2019-05-05
PIL(Python Imaging Library)是一个非常强大的Python库,但是它支持Python2.X, 在Python3中则使用的是Pillow库,它是从PIL中fork出来的一个分支。这篇文章主要介绍了用Python搞定九宫格式的朋友圈功能内附“马云”朋友圈 ,需要的朋友可以参考下2019-05-05 QThread是Qt线程类中最核心的底层类。要使用QThrea开始一个线程,可以创建它的一个子类,然后覆盖其QThread.run()函数。这篇文章就来和大家聊聊QThread类的使用,感兴趣的可以学习一下2022-12-12
QThread是Qt线程类中最核心的底层类。要使用QThrea开始一个线程,可以创建它的一个子类,然后覆盖其QThread.run()函数。这篇文章就来和大家聊聊QThread类的使用,感兴趣的可以学习一下2022-12-12










最新评论