
Python爬虫之批量下载喜马拉雅音频
更新时间:2021年05月18日 11:34:14 作者:wangzirui32
今天教大家如何利用Python爬虫批量下载喜马拉雅音频,文中有非常详细的代码示例,对正在学习python的小伙伴们很有帮助,需要的朋友可以参考下
一、解析网站
1.1 获取音频地址
在喜马拉雅网站上,随便点开一个音频,打开“开发者工具”,再点击播放按钮,可以看到出现了多个请求:
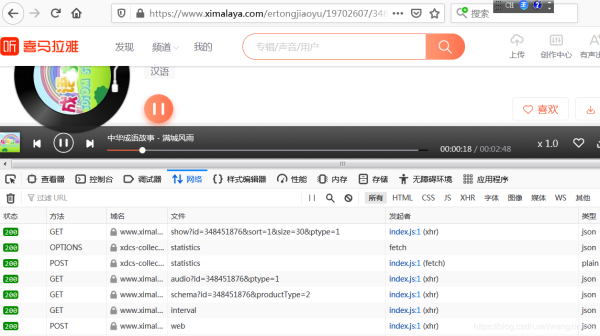
经过排查,发现可疑url:

查看它的响应信息,发现音频地址就在里面:
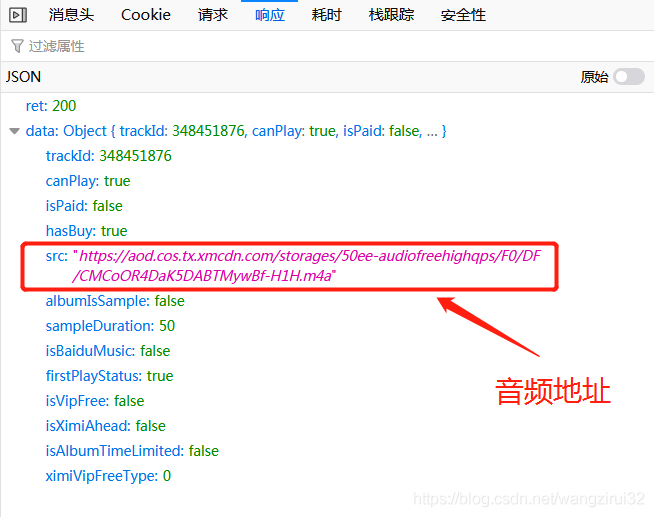
接下来,解析这个返回音频地址的url:
https://www.ximalaya.com/revision/play/v1/audio?id=348451879&ptype=1
发现url中的id参数就决定了返回的音频地址,而id参数是音频的id号。
1.2 解析专栏网页
我们已经知道了获取音频url的网址,接下来要获取一个专栏内的音频id和名称,打开一个专栏,发现:
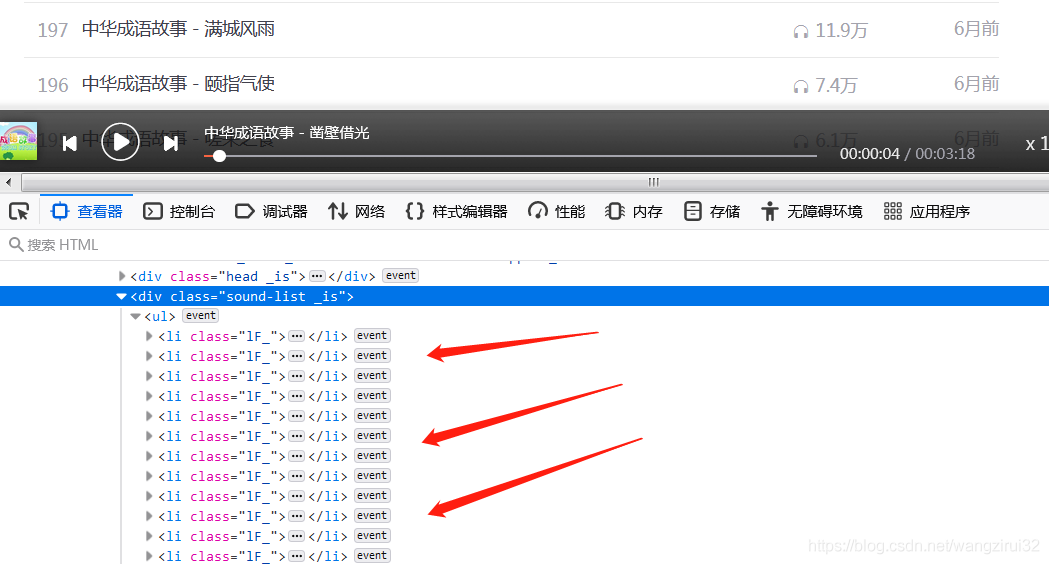
所有的音频存放在class为1F_的li标签中,再来解析li标签:
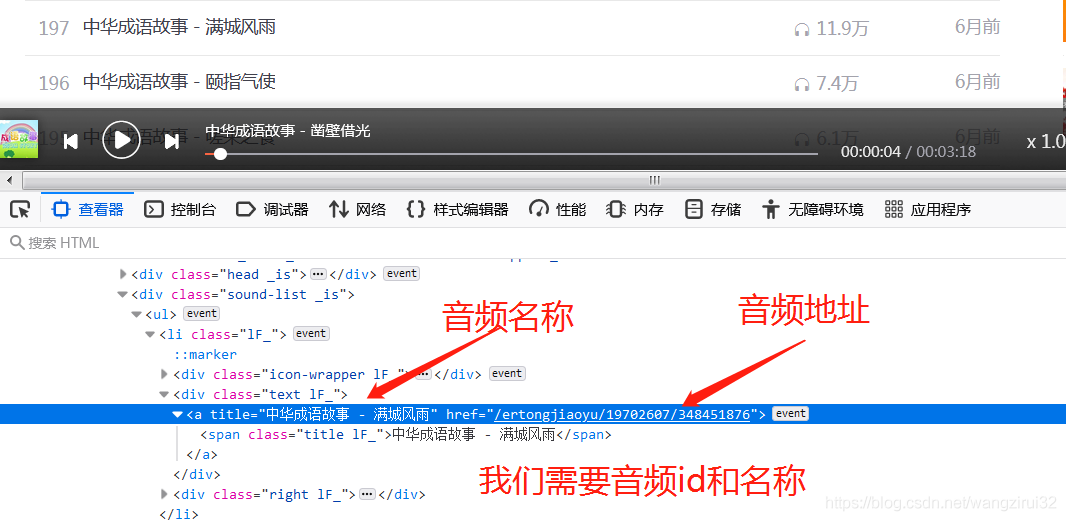
在li标签中的第一个a标签存储着我们所有需要的数据,妙~啊!
1.3 整理亿下思路
思路:
1.获取专栏内的li标签
2.获取li标签里的第一个a标签
3.读取a标签的title和href属性
4.将href解析成音频id
5.将id带入url请求音频源地址
6.提取音频源地址
7.请求音频源地址
8.保存音频(文件名为a的title属性)
思路整理完了,开始编写代码。
二、编写爬取代码
代码奉上——
import requests
from fake_useragent import UserAgent as ua
from bs4 import BeautifulSoup as bs
# 专栏地址
music_list_url = 'https://www.ximalaya.com/ertongjiaoyu/19702607/'
# 获取音频地址的url
get_link_url = "https://www.ximalaya.com/revision/play/v1/audio"
# UA伪装
headers = {
"User-Agent": ua().random
}
# 参数
params = {
"id": None, # id先设为None
"ptype": "1",
}
# 获取专栏HTML源码
music_list_r = requests.get(music_list_url, headers=headers)
# 解析 获取所有li标签
soup = bs(music_list_r.text, "lxml")
li = soup.find_all("li", {"class": "lF_"})
# for循序遍历处理
for i in li:
a = i.find("a") # 找到a标签
# 获取href属性
# split("/")将字符串以"/"作为分隔符 从右往左数第一项是id号
music_id = a.get("href").split("/")[-1]
# 获取title属性 和“.m4a”拼接成文件名
music_name = a.get("title") + ".m4a"
# 修改请求参数id
params['id'] = music_id
# 获得音频源地址
r = requests.get(get_link_url, headers=headers, params=params)
link = r.json()['data']['src']
# 获取音频文件并保存
music_file = requests.get(link).content
with open(music_name, "wb") as f:
f.write(music_file)
print("下载完毕!")
运行代码,等待亿会(真的要等亿会),可以看到当前目录下已经出现了音频文件,如图:
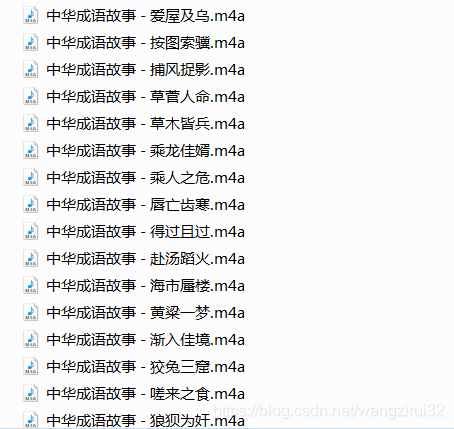
到此这篇关于Python爬虫之批量下载喜马拉雅音频的文章就介绍到这了,更多相关Python下载喜马拉雅音频内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了django之用户、用户组及权限设置方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了django之用户、用户组及权限设置方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05 在本篇文章里小编给大家分享了关于python把转列表为集合的方法以及相关实例内容,有兴趣的朋友们学习下。2019-06-06
在本篇文章里小编给大家分享了关于python把转列表为集合的方法以及相关实例内容,有兴趣的朋友们学习下。2019-06-06 这篇文章主要介绍了Python中变量的拷贝和作用域问题,包括一些赋值、引用问题,以及相关函数在Python2和3版本之间的不同,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了Python中变量的拷贝和作用域问题,包括一些赋值、引用问题,以及相关函数在Python2和3版本之间的不同,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了Python正则表达式急速入门(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12
这篇文章主要介绍了Python正则表达式急速入门(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12 Lock类是threading中用于锁定当前线程的锁定类,本文给大家介绍了Python threading中lock的使用,需要的朋友可以参考下2022-11-11
Lock类是threading中用于锁定当前线程的锁定类,本文给大家介绍了Python threading中lock的使用,需要的朋友可以参考下2022-11-11 这篇文章主要给大家介绍了关于Python如何正确重载运算符的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们参考借鉴,下面随着小编来一起学习学习吧。2017-08-08
这篇文章主要给大家介绍了关于Python如何正确重载运算符的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们参考借鉴,下面随着小编来一起学习学习吧。2017-08-08 这篇文章主要介绍了python 实现多线程下载视频的代码,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了python 实现多线程下载视频的代码,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11 这篇文章主要介绍了Python对接六大主流数据库(只需三步),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
这篇文章主要介绍了Python对接六大主流数据库(只需三步),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07 在本文里小编给各位分享了一篇关于python怎么读出当前时间精度到秒的内容,对此有需要的朋友们可以学习参考下。2019-07-07
在本文里小编给各位分享了一篇关于python怎么读出当前时间精度到秒的内容,对此有需要的朋友们可以学习参考下。2019-07-07
简介Python的collections模块中defaultdict类型的用法
这里我们来简介Python的collections模块中defaultdict类型的用法,与内置的字典类最大的不同在于初始化上,一起来看一下:2016-07-07










最新评论