
MySQL 用 limit 为什么会影响性能
首先说明一下MySQL的版本:
mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.17 | +-----------+ 1 row in set (0.00 sec)
表结构:
mysql> desc test; +--------+---------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+---------------------+------+-----+---------+----------------+ | id | bigint(20) unsigned | NO | PRI | NULL | auto_increment | | val | int(10) unsigned | NO | MUL | 0 | | | source | int(10) unsigned | NO | | 0 | | +--------+---------------------+------+-----+---------+----------------+ 3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test; +----------+ | count(*) | +----------+ | 5242882 | +----------+ 1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5; +---------+-----+--------+ | id | val | source | +---------+-----+--------+ | 3327622 | 4 | 4 | | 3327632 | 4 | 4 | | 3327642 | 4 | 4 | | 3327652 | 4 | 4 | | 3327662 | 4 | 4 | +---------+-----+--------+ 5 rows in set (15.98 sec)
为了达到相同的目的,我们一般会改写成如下语句:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id; +---------+-----+--------+---------+ | id | val | source | id | +---------+-----+--------+---------+ | 3327622 | 4 | 4 | 3327622 | | 3327632 | 4 | 4 | 3327632 | | 3327642 | 4 | 4 | 3327642 | | 3327652 | 4 | 4 | 3327652 | | 3327662 | 4 | 4 | 3327662 | +---------+-----+--------+---------+ 5 rows in set (0.38 sec)
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
查询到索引叶子节点数据。
根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
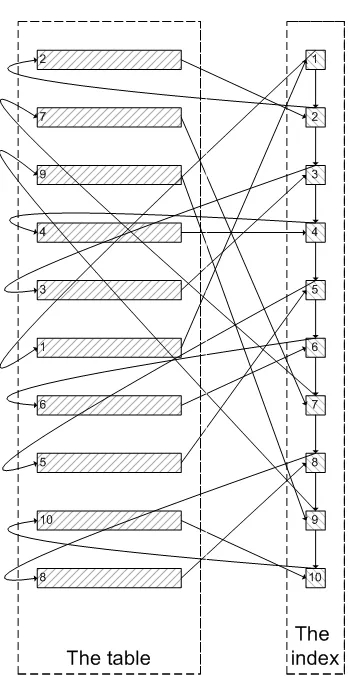
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
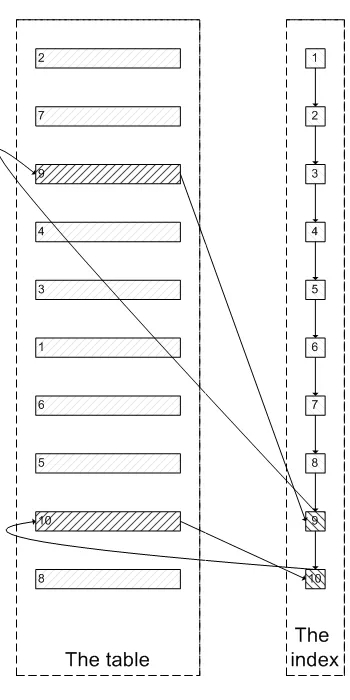
证实:
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5) b>之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) b>为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题:
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
到此这篇关于MySQL 用 limit 为什么会影响性能的文章就介绍到这了,更多相关MySQL 使用 limit的性能影响 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了一条sql语句在mysql中是如何执行的,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03
这篇文章主要介绍了一条sql语句在mysql中是如何执行的,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-03-03 这篇文章主要介绍了Linux下Mysql5.6 二进制安装过程,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了Linux下Mysql5.6 二进制安装过程,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2018-06-06 这篇文章主要介绍了MySQL 备份之 into outfile,文章围绕主题展开详细内容介绍,具有一定的参考价值需要的小伙伴可以参考一下2022-05-05
这篇文章主要介绍了MySQL 备份之 into outfile,文章围绕主题展开详细内容介绍,具有一定的参考价值需要的小伙伴可以参考一下2022-05-05 这篇文章主要详解了数据库语言中的null值,针对MySQL上的实例进行讲解,需要的朋友可以参考下2015-04-04
这篇文章主要详解了数据库语言中的null值,针对MySQL上的实例进行讲解,需要的朋友可以参考下2015-04-04 mysql数据库的负载能力除了和你机器硬件有关,还有一个重要参数就是你系统的配置有关,下面我来给大家介绍几种提高MYSQL数据库连接数负载能力方法总结,有需要的朋友可以参考一下2013-08-08
mysql数据库的负载能力除了和你机器硬件有关,还有一个重要参数就是你系统的配置有关,下面我来给大家介绍几种提高MYSQL数据库连接数负载能力方法总结,有需要的朋友可以参考一下2013-08-08 这篇文章主要介绍了MySQL中给自定义的字段查询结果添加排名的方法,只需要对counter写一个小算式,非常简单,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了MySQL中给自定义的字段查询结果添加排名的方法,只需要对counter写一个小算式,非常简单,需要的朋友可以参考下2015-06-06 这篇文章主要介绍了mysql时间格式和Java时间格式的对应方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了mysql时间格式和Java时间格式的对应方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 这篇文章主要介绍了MySQL大库搭建主从的一种思路分享,帮助大家更好的理解和学习使用MySQL数据库,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了MySQL大库搭建主从的一种思路分享,帮助大家更好的理解和学习使用MySQL数据库,感兴趣的朋友可以了解下2021-03-03 这篇文章主要介绍了详解Mysql之mysqlbackup备份与恢复实践,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-02-02
这篇文章主要介绍了详解Mysql之mysqlbackup备份与恢复实践,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-02-02 这篇文章主要分享的是超详细汇总21个值得收藏的mysql优化实践,对正在学习的同学有一定的参考价值,需要的同学可以参考一下2022-01-01
这篇文章主要分享的是超详细汇总21个值得收藏的mysql优化实践,对正在学习的同学有一定的参考价值,需要的同学可以参考一下2022-01-01










最新评论