
Python实现数据透视表详解
更新时间:2021年10月28日 11:06:47 作者:weixin_12162011
今天小编就为大家分享一篇用Python实现数据的透视表的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
用Python里的Pandas可以实现,虽然感觉Excel更方便
1.groupby + agg
不够直观,不好看
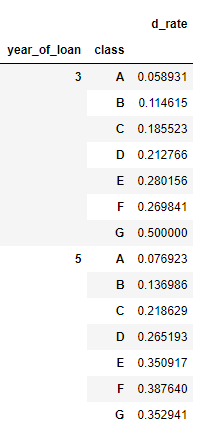
对贷款年份,贷款种类创建数据透视
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))
2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的参数:
index:选哪个变量做数据透视表的行
columns:选哪个变量做数据透视表的列
values:要聚合的值
aggfunc:使用的聚合函数
margins:是否添加汇总列/行
margins_name:汇总行/列的名字
例子
对贷款年份,贷款种类创建数据透视
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合计')

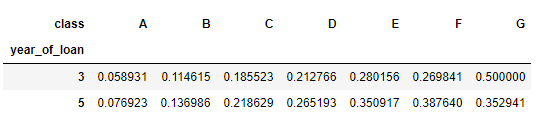
可以直接看出交叉组合之后违约比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')

3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用参数与crosstab一致
例子
实现同样的数据透视表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)

pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!
相关文章

Python数据可视化 pyecharts实现各种统计图表过程详解
这篇文章主要介绍了Python数据可视化 pyecharts实现各种统计图表过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08 这篇文章主要介绍了10招!看骨灰级Pythoner如何玩转Python,需要的朋友可以参考下2019-04-04
这篇文章主要介绍了10招!看骨灰级Pythoner如何玩转Python,需要的朋友可以参考下2019-04-04 这篇文章主要介绍了Python程序的执行原理,简要地描述了其中的步骤,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python程序的执行原理,简要地描述了其中的步骤,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了python Django增删改查快速体验,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-02-02
这篇文章主要介绍了python Django增删改查快速体验,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-02-02 这篇文章主要介绍了编写Python的web框架中的Model的教程,示例代码基于Python2.x版本,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了编写Python的web框架中的Model的教程,示例代码基于Python2.x版本,需要的朋友可以参考下2015-04-04
PyCharm配置KBEngine快速处理代码提示冲突、配置命令问题
这篇文章主要介绍了PyCharm配置KBEngine,解决代码提示冲突、配置命令,本文通过图文并茂的形式给大家介绍的超详细,需要的朋友可以参考下2021-04-04 这篇文章主要介绍了利用Python PyQT5制作一个手绘图片生成器,可以将导入的彩色图片通过python分析光源、灰度等操作生成手绘图片。感兴趣的可以跟随小编一起了解一下2022-02-02
这篇文章主要介绍了利用Python PyQT5制作一个手绘图片生成器,可以将导入的彩色图片通过python分析光源、灰度等操作生成手绘图片。感兴趣的可以跟随小编一起了解一下2022-02-02 这篇文章主要为大家介绍了详解Python如何与java高效的交互的方法示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-06-06
这篇文章主要为大家介绍了详解Python如何与java高效的交互的方法示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-06-06 这篇文章主要为大家详细介绍了python正则的常用方法,覆盖范围70%以上,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
这篇文章主要为大家详细介绍了python正则的常用方法,覆盖范围70%以上,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
django-xadmin根据当前登录用户动态设置表单字段默认值方式
这篇文章主要介绍了django-xadmin根据当前登录用户动态设置表单字段默认值方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03










最新评论