
python 根据csv表头、列号读取数据的实现
根据csv表头、列号读取数据的实现
读取csv文件
cvs数据截图如下
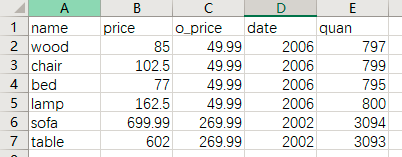
设置index_col=0,目的是设置第一列name为index(索引),方便下面示例演示
data = pandas.read_csv(input1, index_col=0)
输出结果
price o_price date quan
name
wood 85.00 49.99 2006 797
chair 102.50 49.99 2006 799
bed 77.00 49.99 2006 795
lamp 162.50 49.99 2006 800
sofa 699.99 269.99 2002 3094
table 602.00 269.99 2002 3093
根据表头获取列数据
data[['o_price', 'quan'] # 或者 data.loc[:, ['o_price', 'quan']
输出结果
o_price quan
name
wood 49.99 797
chair 49.99 799
bed 49.99 795
lamp 49.99 800
sofa 269.99 3094
table 269.99 3093
根据列号读取列数据
data.iloc[:, [3, 4]]
输出结果
date quan
name
wood 2006 797
chair 2006 799
bed 2006 795
lamp 2006 800
sofa 2002 3094
table 2002 3093
根据index名获取行数据
data.loc[['wood', 'sofa'], :]
输出结果
price o_price date quan
name
wood 85.00 49.99 2006 797
sofa 699.99 269.99 2002 3094
根据列号读取行数据
data.iloc[[0, 1], :]
输出结果
price o_price date quan
name
wood 85.0 49.99 2006 797
chair 102.5 49.99 2006 799
iloc和loc区别
loc是根据dataframe的具体标签选取列,而iloc是根据标签所在的位置,从0开始计数。
读取csv文件并输出特定列
其实,最开始好不容易输出了指定列,结果第二天不小心删了什么东西,然后就一直报错。
看上去和前一天能正常输出的没有什么差别。折腾了一天多总算是找到问题是什么了,是个很简单的问题。
其实不是错误,只是因为选用的读取方式不同,所以一直报错。
源代码如下
import csv
import pandas as pd
sheet_name = "员工信息表.csv"
#数据文件有问题数据
with open(sheet_name,encoding = "utf-8",errors = "ignore") as f:
#可通过列名读取列值,表中有空值
data= csv.DictReader(_.replace("\x00","") for _ in f)
headers = next(data)
print(headers)
for row in data:
print(row)
if row['员工状态'] == '2':
print(row)
#不可通过列名读取列值,通过第几列来读取
#data =csv.reader(_.replace("\x00","") for _ in f)
headers = next(data)
print(headers)
for row in data:
print(row)
if row[12]=='2':
print(row)读取csv文件需要采用:
with open(sheet_name,encoding = "utf-8",errors = "ignore") as f:
如果不加errors = "ignore"会报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 0: invalid start byte
通过csv.reader读取csv文件,然后使用列名row['员工状态']输出列值会报错:
“TypeError: list indices must be integers or slices, not str”
根据这个报错百度了好久,一直没有找到解决方法。
虽然现在最终效果达到了,但是并不清楚具体原因。
源数据表里面问题好多啊,感觉需要先做数据清洗。唉!好难啊!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要为大家介绍了python神经网络学习使用Keras进行简单分类,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了python神经网络学习使用Keras进行简单分类,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 这篇文章主要介绍了Python SQLAlchemy库的使用方法,帮助大家更好的利用python处理数据库,感兴趣的朋友可以了解下2020-10-10
这篇文章主要介绍了Python SQLAlchemy库的使用方法,帮助大家更好的利用python处理数据库,感兴趣的朋友可以了解下2020-10-10 这篇文章主要介绍了Python开发之pip安装及使用方法详解,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python开发之pip安装及使用方法详解,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了Python实现的将文件每一列写入列表功能,涉及Python文件读取、遍历、序列追加、赋值等相关操作技巧,需要的朋友可以参考下2018-03-03
这篇文章主要介绍了Python实现的将文件每一列写入列表功能,涉及Python文件读取、遍历、序列追加、赋值等相关操作技巧,需要的朋友可以参考下2018-03-03
解决nohup执行python程序log文件写入不及时的问题
今天小编就为大家分享一篇解决nohup执行python程序log文件写入不及时的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
Python django框架应用中实现获取访问者ip地址示例
这篇文章主要介绍了Python django框架应用中实现获取访问者ip地址,涉及Python Request模块相关函数使用技巧,需要的朋友可以参考下2019-05-05 这篇文章主要介绍了Python 模拟生成动态产生验证码图片的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-02-02
这篇文章主要介绍了Python 模拟生成动态产生验证码图片的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-02-02 这篇文章主要为大家详细介绍了Python如何利用request库打造自己的翻译接口,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-04-04
这篇文章主要为大家详细介绍了Python如何利用request库打造自己的翻译接口,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-04-04 这篇文章主要为大家详细介绍了Python实现朴素贝叶斯算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11
这篇文章主要为大家详细介绍了Python实现朴素贝叶斯算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11 在本篇内容里小编给大家整理了关于python如何表示空值的知识点内容,有兴趣的朋友们可以跟着学习参考下。2020-06-06
在本篇内容里小编给大家整理了关于python如何表示空值的知识点内容,有兴趣的朋友们可以跟着学习参考下。2020-06-06










最新评论