
python自动获取微信公众号最新文章的实现代码
微信公众号获取思路
常用的微信公众号文章获取方法有搜狐、微信公众号主页获取和api接口等多个方法。
听说搜狐最近不怎么好用了,之前用的api接口也频繁维护,所以用了微信公众平台来进行数据爬取。
首先登陆自己的微信公众平台,没有账号的可以注册一个。进来之后找“图文信息”,就是写公众号的地方
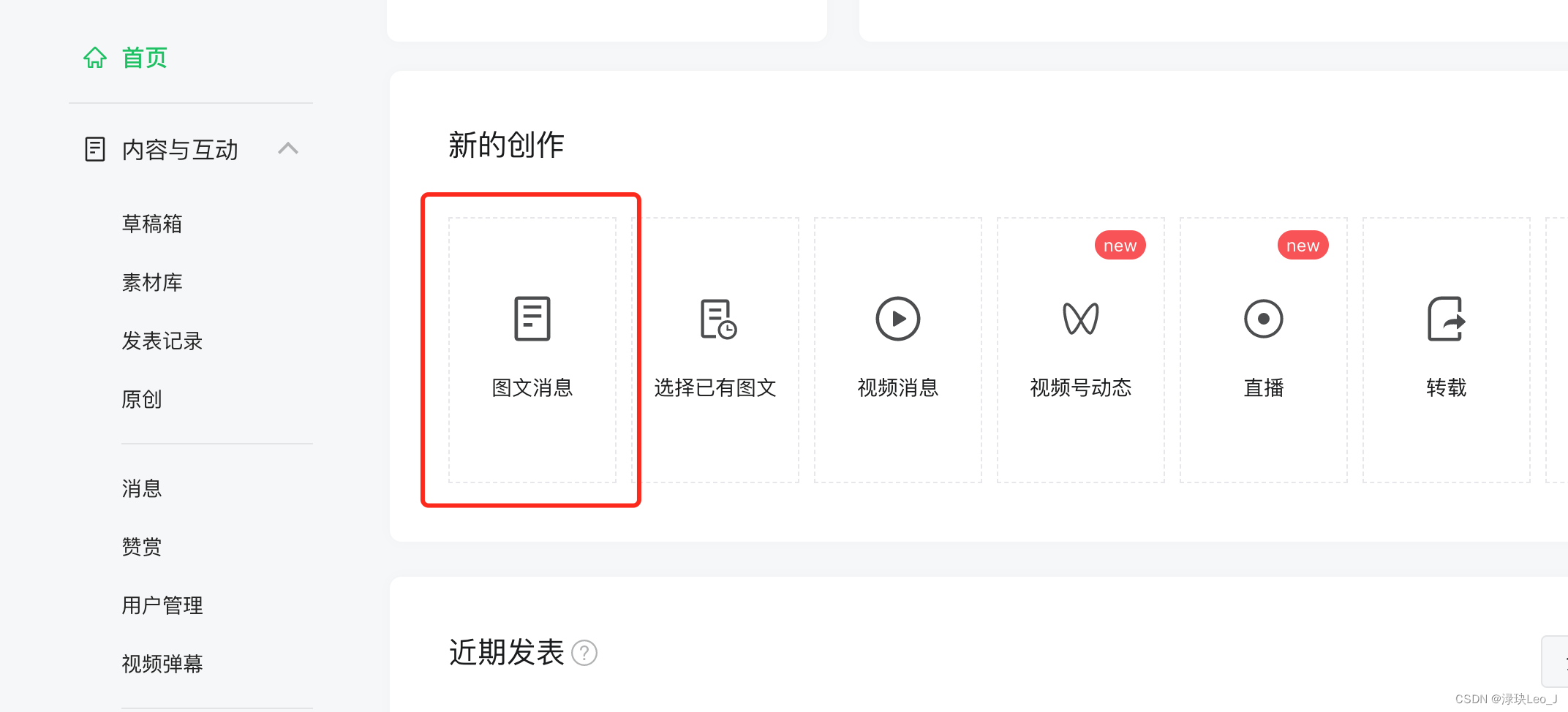
点进去后就是写公众号文章的界面,在界面中找到“超链接” 的字段,在这里就可以对其他的公众号进行检索。
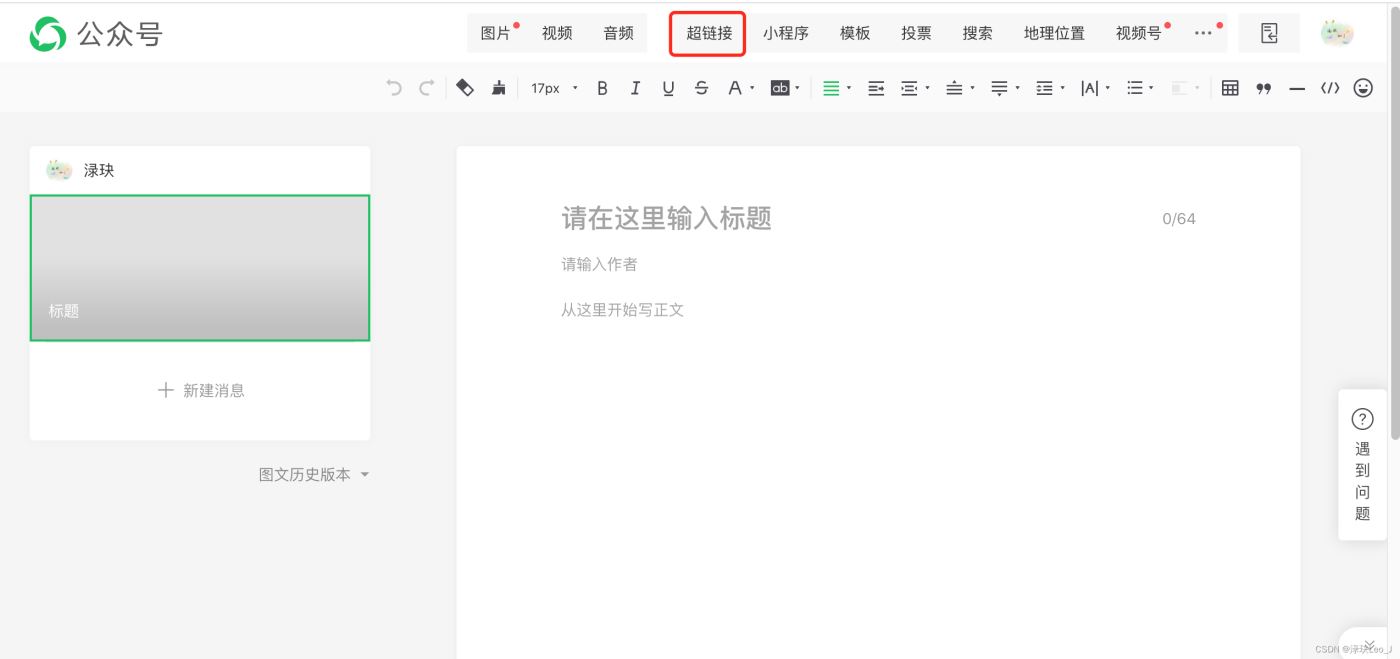
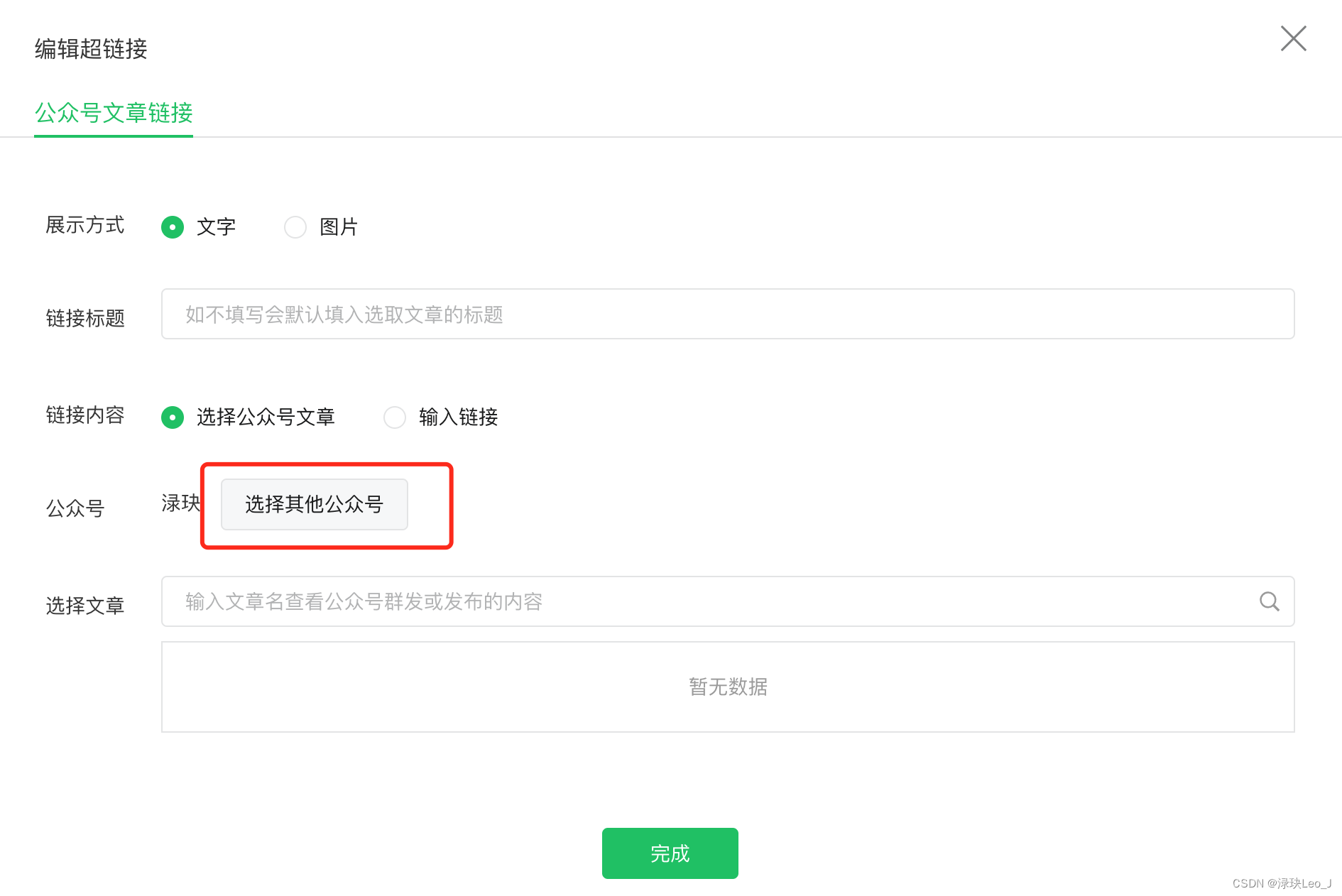
以“python”为例,输入要检索的公众号名称,在显示的公众号中选择要采集的公众号
点开浏览器的检查,找到network中,下图里的这个链接,而右边的Request URL才是存储公众号数据的真实链接。说明这是个json网页。

采集实例
以公众号“python”的 链接 为例对网址进行分析。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接 "token": "163455614", #需要定期修改的token "lang": "zh_CN", #语言 "f": "json", "ajax": "1", #显示几天的文章 "action": "list_ex" "begin": "0", #起始页面 "count": "1", #计数 "query": "", "fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码 "type": "9",
既然发现了fakeid是代表公众号的唯一编码,那接下来只需要把需要的公众号的fakeid找到就行,我随意找了三个公众号的进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg=='] #若增加公众号需要增加fakeid
那接下来就是对网址的请求
首先导入需要的库
import time import requests from lxml import etree import pandas as pd import json import numpy as np import datetime import urllib3 from urllib3.exceptions import InsecureRequestWarning urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookie避开登陆,对文章求情前需要找到网页的cookie和User-Agent,由于微信公众号回定期刷新,这个cookie和上面的token都要定期更换。
为避免反扒最好也找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来就可以对页面进行爬取,获取页面中的文章标题与文章链接,以及文章的时间,对网页的信息进行分析发现网页的所有信息都保存在’app_msg_list’这个字段中,所以对这个字段中的数据进行提取。
代码如下:
获取到的数据包存在df中,这里的数据还不是微信公众号的最新文章数据,而是微信公众号这最近一天发出的文章数据。所以还需要对发文的时间进行筛选。注意到这里的时间格式为时间戳,所以需要对时间数据进行转换
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd这样就可以把微信公众号的时间戳数据转换为时间数据,之后,根据当前天的日期对数据集中的内容进行提取与存储就OK啦
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")这样就可以把需要的微信公众号最新文章采集下来了,需要多个微信公众号在fakeid中添加公众号的识别码就OK啦~
到此这篇关于python自动获取微信公众号最新文章的文章就介绍到这了,更多相关python自动获取微信公众号文章内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

python3.9实现pyinstaller打包python文件成exe
这篇文章主要介绍了python3.9实现pyinstaller打包python文件成exe,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12 这篇文章主要介绍了python之os路径被转义的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02
这篇文章主要介绍了python之os路径被转义的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02 Celery是Python开发的分布式任务调度模块,这篇文章主要给大家介绍了关于Django中如何使用celery异步发送短信验证码的相关资料,主要内容包括基础介绍、工作原理、完整代码等方面,需要的朋友可以参考下2021-09-09
Celery是Python开发的分布式任务调度模块,这篇文章主要给大家介绍了关于Django中如何使用celery异步发送短信验证码的相关资料,主要内容包括基础介绍、工作原理、完整代码等方面,需要的朋友可以参考下2021-09-09 这篇文章主要介绍了在Python下使用Txt2Html实现网页过滤代理的教程,来自IBM官方开发者技术文档,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了在Python下使用Txt2Html实现网页过滤代理的教程,来自IBM官方开发者技术文档,需要的朋友可以参考下2015-04-04 这篇文章主要给大家介绍了在Python中模块与包有相同名字的处理方法,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-05-05
这篇文章主要给大家介绍了在Python中模块与包有相同名字的处理方法,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-05-05 这篇文章主要为大家详细介绍了python实现朴素贝叶斯分类器,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
这篇文章主要为大家详细介绍了python实现朴素贝叶斯分类器,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03 这篇文章主要为大家详细介绍了python tkinter实现屏保程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-07-07
这篇文章主要为大家详细介绍了python tkinter实现屏保程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-07-07 这篇文章主要介绍了Django REST framework内置路由用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了Django REST framework内置路由用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-07-07 今天小编就为大家分享一篇对python 操作solr索引数据的实例详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇对python 操作solr索引数据的实例详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
探索Python数据可视化库中Plotly Express的使用方法
在数据分析和可视化领域,数据的有效呈现是至关重要的,python作为一种强大的编程语言,提供了多种数据可视化工具和库,本文将介绍Plotly Express的基本概念和使用方法,帮助读者快速入门并掌握数据可视化的技巧2023-06-06










最新评论