
Python使用read_csv读数据遇到分隔符问题的2种解决方式
用read_csv读数据遇到分隔符问题的两种解决方式
import pandas as pd
1.更改read_csv函数中的传参“sep”
1.1缺省sep参数
默认分隔符为‘,’
1.2不缺省sep参数
1.2.1要读入的文档中分隔符为一位字符
用单引号括起文本中的分隔符
例:sep = '|'
1.2.2要读入的文档中分隔符为多位字符
多位字符在python中被识别为正则式
此时可用为sep = ‘\s+’(不论多位分隔符有什么组成,比如几个空格、\r\t)
此时,python将用自己的语法分析器来对多位字符进行识别
2.利用记事本功能进行分隔符替换
因为自己在编程的时候用正则表达式出现了一些问题,故找到了另一种更改文本中分隔符,以便于设定sep参数的方法,现记录如下。
2.1利用txt中的“编辑”—>“替换”操作

当前分隔符为‘,’

替换为‘ | ’,并单击全部替换

替换后,分隔符为‘ | ’
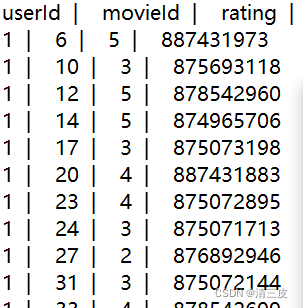
2.2小tips
选择分隔符的时候有可能面临
“这么大空挡是几个空格?”
“这个逗号是中文的还是英文的?”
…
所以建议直接用鼠标拉着两个数据之间的分割区域,复制,然后粘贴填入要替换的框中。(像我这种手残眼花的人就喜欢这种方式。。。)
补充:Python read_csv 报错:‘gbk‘ codec can‘t decode byte 0xb4 in position 8: illegal multibyte sequence
在我们使用pandas.read_csv()读取文件时 经常会遇到UnicodeDecodeError 的错误
我遇到的主要有两种:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
或者
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
尝试过改encoding="gbk",encoding="utf-8"或者GB2312、gbk、ISO-8859-1的方法,有时候能够起效果,有时候不行
介绍一种最有效的方法:
1.找到csv文件–>右键–>打开方式–>记事本
2.打开记事本之后,在右下角可以看到文件的默认编码格式为ANSI,选择头部菜单的“文件–>另存为”,
3.选择编码下拉框,选择需要的编码格式UTF-8,重新保存即可
4.使用 read_csv('./test.csv', encoding="utf-8") 即可
下面我遇到过错误可以尝试的解决办法如下(推荐使用上面的,下面的有时候也不行):
1. csvdata = pd.read_csv(file, keep_default_na=False, encoding="gbk")
报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
解决:将 encoding="gbk" 改为encoding="utf-8" 或者删掉
2. csvdata = pd.read_csv(file, keep_default_na=False)
报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
解决:加上 encoding="gbk" 试试看
总结
到此这篇关于Python使用read_csv读数据遇到分隔符问题的2种解决方式的文章就介绍到这了,更多相关Python read_csv读数据分隔符问题内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python 列表套json字典根据相同的key筛选数据,文章基于python的相关资料展开详细的内容介绍需要的小伙伴可以参考一下2022-04-04
这篇文章主要介绍了python 列表套json字典根据相同的key筛选数据,文章基于python的相关资料展开详细的内容介绍需要的小伙伴可以参考一下2022-04-04 这篇文章主要介绍了python3 kubernetes api的使用示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2021-01-01
这篇文章主要介绍了python3 kubernetes api的使用示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2021-01-01
python 利用matplotlib在3D空间中绘制平面的案例
这篇文章主要介绍了python 利用matplotlib在3D空间中绘制平面的案例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02 这篇文章主要介绍了Python中使用urllib2模块编写爬虫的简单上手示例,文中还介绍到了相关异常处理功能的添加,需要的朋友可以参考下2016-01-01
这篇文章主要介绍了Python中使用urllib2模块编写爬虫的简单上手示例,文中还介绍到了相关异常处理功能的添加,需要的朋友可以参考下2016-01-01
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
这篇文章主要介绍了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能,结合实例形式分析了scrapy框架proxy代理设置技巧与相关问题注意事项,需要的朋友可以参考下2018-08-08 这篇文章主要介绍了Python通过psd-tools解析PSD文件,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以参考一下2022-06-06
这篇文章主要介绍了Python通过psd-tools解析PSD文件,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以参考一下2022-06-06 这篇文章主要介绍了python return逻辑判断表达式实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python return逻辑判断表达式实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12
Python读取配置文件(config.ini)以及写入配置文件
这篇文章主要介绍了Python读取配置文件(config.ini)以及写入配置文件,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-04-04 这篇文章主要介绍了Python下singleton模式的实现方法,有一定的借鉴价值,需要的朋友可以参考下2014-07-07
这篇文章主要介绍了Python下singleton模式的实现方法,有一定的借鉴价值,需要的朋友可以参考下2014-07-07 这篇文章主要介绍了python cumsum函数的具体使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
这篇文章主要介绍了python cumsum函数的具体使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07










最新评论