
pytorch简单实现神经网络功能
更新时间:2022年09月15日 08:25:19 作者:那小子真混蛋
这篇文章主要介绍了pytorch简单实现神经网络,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
一、基本
(1)利用pytorch建好的层进行搭建
import torch
from torch import nn
from torch.nn import functional as F
#定义一个MLP网络
class MLP(nn.Module):
'''
网络里面主要是要定义__init__()、forward()
'''
def __init__(self):
'''
这里定义网络有哪些层(比如nn.Linear,Conv2d……)[可不含激活函数]
'''
super().__init__()#调用Module(父)初始化
self.hidden = nn.Linear(5,10)
self.out = nn.Linear(10,2)
def forward(self,x):
'''
这里定义前向传播的顺序,即__init__()中定义的层是按怎样的顺序进行连接以及传播的[在这里加上激活函数,以构造复杂函数,提高拟合能力]
'''
return self.out(F.relu(self.hidden(x)))上面的3层感知器可以用于解决一个简单的现实问题:给定5个特征,输出0-1类别概率值,是一个简单的2分类解决方案。
搭建一些简单的网络时,可以用nn.Sequence(层1,层2,……,层n)一步到位:
import torch from torch import nn from torch.nn import functional as F net = nn.Sequential(nn.Linear(5,10),nn.ReLU(),nn.Linear(10,2))
但是nn.Sequence仅局限于简单的网络搭建,而自定义网络可以实现复杂网络结构。
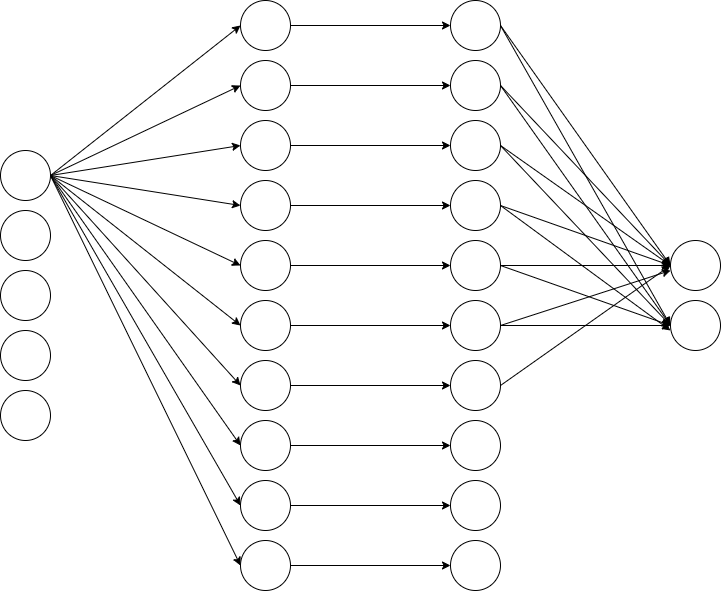
(1)中定义的MLP大致如上(5个输入->全连接->ReLU()->输出)
(2)使用网络
import torch from torch import nn from torch.nn import functional as F net = MLP() x = torch.randn((15,5))#15个samples,5个输入属性 out = net(x) #也可调用forward->"out = net.forward(x)" print(out) #print(out.shape)
tensor([[-0.0760, -0.1026],
[-0.3277, -0.2332],
[-0.0314, -0.1921],
[ 0.0131, -0.1473],
[-0.0650, -0.2310],
[ 0.3009, -0.5510],
[ 0.1491, -0.0928],
[-0.1438, -0.1304],
[-0.1945, -0.1944],
[ 0.1088, -0.2249],
[ 0.0016, -0.2334],
[ 0.1401, -0.3709],
[-0.1864, -0.1764],
[ 0.0775, -0.0160],
[ 0.0150, -0.3198]], grad_fn=<AddmmBackward>)二、进阶
(1)构建较复杂的网络结构
a. Sequence、net套娃
import torch
from torch import nn
from torch.nn import functional as F
class MLP2(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(5,10),nn.ReLU(),nn.Linear(10,5))
self.out = nn.Linear(5,4)
def forward(self,x):
return self.out(F.relu(self.net(x)))
net2 = nn.Sequential(MLP2(),nn.ReLU(),nn.Linear(4,2))
net2.eval()
# eval()等价print(net2)Sequential(
(0): MLP2(
(net): Sequential(
(0): Linear(in_features=5, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=5, bias=True)
)
(out): Linear(in_features=5, out_features=4, bias=True)
)
(1): ReLU()
(2): Linear(in_features=4, out_features=2, bias=True)
)(2) 参数
a. 权重、偏差的访问
#访问权重和偏差 print(net2[2].weight)#注意weight是parameter类型,.data访问数值 print(net2[2].bias.data) #输出所有权重、偏差 print(*[(name,param) for name,param in net2[2].parameters()])
b. 不同网络之间共享参数
shared = nn.Linear(8,8) net = nn.Sequential(nn.Linear(5,8),nn.ReLU(),shared,nn.ReLU(),shared) print(net[2].weight.data[0]) net[2].weight.data[0][0] = 100 print(net[2].weight.data[0][0]) print(net[2].weight.data[0] == net[4].weight.data[0]) net.eval()
c. 参数初始化
def init_Linear(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,mean = 0,std = 0.01) #将权重按照均值为0,标准差为0.01的正态分布进行初始化
nn.init.zeros_(m.bias) #将偏差置为0
def init_const(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight,42) #将权重全部置为42
def my_init(m):
if type(m) == nn.Linear:
'''
对weight和bias自定义初始化
'''
pass
#如何调用?
net2.apply(init_const) #在net2中进行遍历,对每个Linear执行初始化(3)自定义层(__init__()中可含输入输出层)
a. 不带输入输出的自定义层(输入输出一致,x数进,x数出,对每个值进行相同的操作,类似激活函数)
b. 带输入输出的自定义层
import torch
from torch import nn
from torch.nn import functional as F
#a
class decentralized(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
return x-x.mean()
#b
class my_Linear(nn.Module):
def __init__(self,dim_in,dim_out):
super().__init__()
self.weight = nn.Parameter(torch.ones(dim_in,dim_out)) #由于x行数为dim_out,列数为dim_in,要做乘法,权重行列互换
self.bias = nn.Parameter(torch.randn(dim_out))
def forward(self,x):
return F.relu(torch.matmul(x,self.weight.data)+self.bias.data)
tmp = my_Linear(5,3)
print(tmp.weight)(4)读写
#存取任意torch类型变量
x = torch.randn((20,20))
torch.save(x,'X') #存
y = torch.load('X') #取
#存储网络
torch.save(net2.state_dict(),'Past_parameters') #把所有参数全部存储
clone = nn.Sequential(MLP2(),nn.ReLU(),nn.Linear(4,2)) #存储时同时存储网络定义(网络结构)
clone.load_state_dict(torch.load('Past_parameters'))
clone.eval()到此这篇关于pytorch简单实现神经网络的文章就介绍到这了,更多相关pytorch神经网络内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家详细介绍了python实现拼接图片,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03
这篇文章主要为大家详细介绍了python实现拼接图片,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-03-03
在Python中使用filter去除列表中值为假及空字符串的例子
今天小编就为大家分享一篇在Python中使用filter去除列表中值为假及空字符串的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-11-11
读取json格式为DataFrame(可转为.csv)的实例讲解
今天小编就为大家分享一篇读取json格式为DataFrame(可转为.csv)的实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 这篇文章主要介绍了python 基于opencv操作摄像头的方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12
这篇文章主要介绍了python 基于opencv操作摄像头的方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12 这篇文章主要介绍了python使用hdfs3模块对hdfs进行操作详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06
这篇文章主要介绍了python使用hdfs3模块对hdfs进行操作详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要为大家详细介绍了PyQt5实现拖放功能,拖放一个按钮的实现方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-04-04
这篇文章主要为大家详细介绍了PyQt5实现拖放功能,拖放一个按钮的实现方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-04-04 这篇文章主要介绍了python基础之停用词过滤详解,文中有非常详细的代码示例,对正在学习python基础的小伙伴们有很好地帮助,需要的朋友可以参考下2021-04-04
这篇文章主要介绍了python基础之停用词过滤详解,文中有非常详细的代码示例,对正在学习python基础的小伙伴们有很好地帮助,需要的朋友可以参考下2021-04-04
Python sklearn库实现PCA教程(以鸢尾花分类为例)
今天小编就为大家分享一篇Python sklearn库实现PCA教程(以鸢尾花分类为例),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
python opencv 图像处理之图像算数运算及修改颜色空间
这篇文章主要介绍了python opencv 图像处理之图像算数运算及修改颜色空间,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-08-08 这篇文章主要介绍了Python面向对象之继承代码详解,分享了相关代码示例,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-01-01
这篇文章主要介绍了Python面向对象之继承代码详解,分享了相关代码示例,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-01-01










最新评论