
python3中requests库重定向获取URL
更新时间:2022年09月27日 10:34:05 作者:阿常呓语
这篇文章主要介绍了python3中requests库重定向获取URL,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下
前言:
有时候 我们抓取一些页面,发现一些url 有重定向, 返回 301 ,或者302 这种情况。 那么我们如何获取真实的URL呢? 或者跳转后的URL呢?
这里我使用 requests 作为演示
假设我们要访问 某东的电子商务网站,我只记得网站好像是 http://jd.com
import requests
def request_jd():
url = 'http://jd.com/'
#allow_redirects= False 这里设置不允许跳转
response = requests.get(url=url, allow_redirects=False)
print(response.headers)
print(response.status_code)
看结果 返回response header 中有一个属性 Location ,代表重定向了 'Location': 'https://www.jd.com'

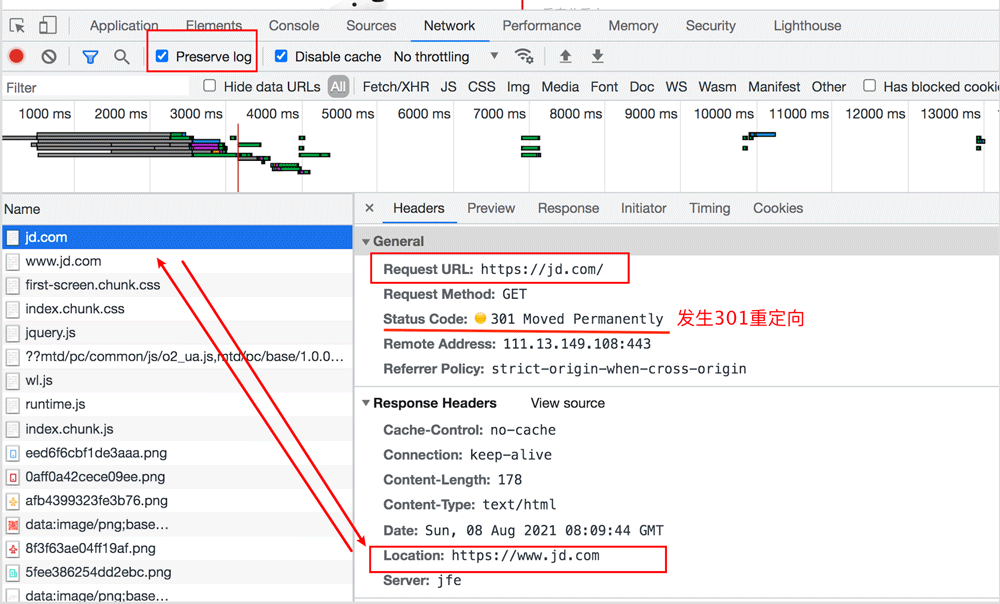
我们在浏览器中 chrome network 面板 ,抓包观察。 注意把 preserve log 这个选项勾选上。
从 浏览器的response header 中 我们可以看到 Location, 从 General 我们可以看到 status code 301 ,发生了跳转。
方法1:
你现在知道如何获取跳转后的URL了吗,直接从response header,获取 Location 即可。
在request.header 中 返回header 的key是不区分大小写的, 所以全小写也是可以正确取值的。
import requests
def request_jd():
url = 'http://jd.com/'
response = requests.get(url=url, allow_redirects=False)
#return response.headers.get('location')
return response.headers.get('Location')方法2:
其实默认情况下, requests 会自动跳转,如果发生了重定向,会自动跳到location 指定的URL,我们只需要访问URL, 获取response, 然后 response.url 就可以获取到真实的URL啦。
import requests
def request_jd():
url = 'http://jd.com/'
response = requests.get(url=url)
return response.url到此这篇关于python3中requests库重定向获取URL的文章就介绍到这了,更多相关python获取URL 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇python flask搭建web应用教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-11-11
今天小编就为大家分享一篇python flask搭建web应用教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-11-11 这篇文章主要介绍了python如何调用百度识图api,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-09-09
这篇文章主要介绍了python如何调用百度识图api,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-09-09 这篇文章主要介绍了判断Threading.start新线程是否执行完毕的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
这篇文章主要介绍了判断Threading.start新线程是否执行完毕的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05 在本篇文章里小编给大家整理的是一篇关于python中%格式表达式实例用法的相关内容,有兴趣的朋友们可以跟着学习下。2021-06-06
在本篇文章里小编给大家整理的是一篇关于python中%格式表达式实例用法的相关内容,有兴趣的朋友们可以跟着学习下。2021-06-06
使用Python手工计算x的算数平方根,来自中国古人的数学智慧
本篇采用的计算方法既非二分法也非牛顿迭代法,而是把中国古代的手工计算平方根的方法转成代码来完成。代码有点烦杂,算是抛砖引玉吧,期待高手们写出更好的代码来2021-09-09 这篇文章主要介绍了python的import 机制是怎么实现的,import有Python运行时的全局模块池的维护和搜索、解析与搜索模块路径的树状结构等作用,下文具体相关介绍需要的小伙伴可以参考一下2022-05-05
这篇文章主要介绍了python的import 机制是怎么实现的,import有Python运行时的全局模块池的维护和搜索、解析与搜索模块路径的树状结构等作用,下文具体相关介绍需要的小伙伴可以参考一下2022-05-05 在本篇文章中小编给各位整理了一篇关于python中翻译功能translate模块实现方法,有需要的朋友们可以参考下。2020-12-12
在本篇文章中小编给各位整理了一篇关于python中翻译功能translate模块实现方法,有需要的朋友们可以参考下。2020-12-12
Python使用everything库构建文件搜索和管理工具
在这篇博客中,我将分享如何使用 Python 的 everytools库构建一个简单的文件搜索和管理工具,这个工具允许用户搜索文件、查看文件路径、导出文件信息到 Excel,以及生成配置文件,文中有相关的代码示例供大家参考,需要的朋友可以参考下2024-08-08 这篇文章主要为大家介绍了python库matplotlib绘制坐标图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10
这篇文章主要为大家介绍了python库matplotlib绘制坐标图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-10-10 这篇文章介绍了Python字节串类型bytes及用法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05
这篇文章介绍了Python字节串类型bytes及用法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05










最新评论