
python selenium参数详解和实现案例
更新时间:2022年10月25日 11:26:40 作者:Vergil_Zsh
这篇文章主要介绍了python selenium参数详解和实现案例,无头模式添加,可以让selenium模拟登录,进入到后台运行,本文以登录打开公司内网下载数据为例,给大家详细讲解,需要的朋友可以参考下
无头模式添加,可以让selenium模拟登录,进入到后台运行
这里以登录打开公司内网下载数据为例,因为涉及私密问题,所以有些地方我们进行覆盖,还请谅解
先不添加无头模式,进行登录,并且下载文件
因为一般selenium使用的是之前版本的浏览器,所以会出现以下情况,需要进行安全认证,所以可以进行直接忽略认证书的错误

一般是在selenium的options进行添加
options.add_argument('ignore-certificate-errors')

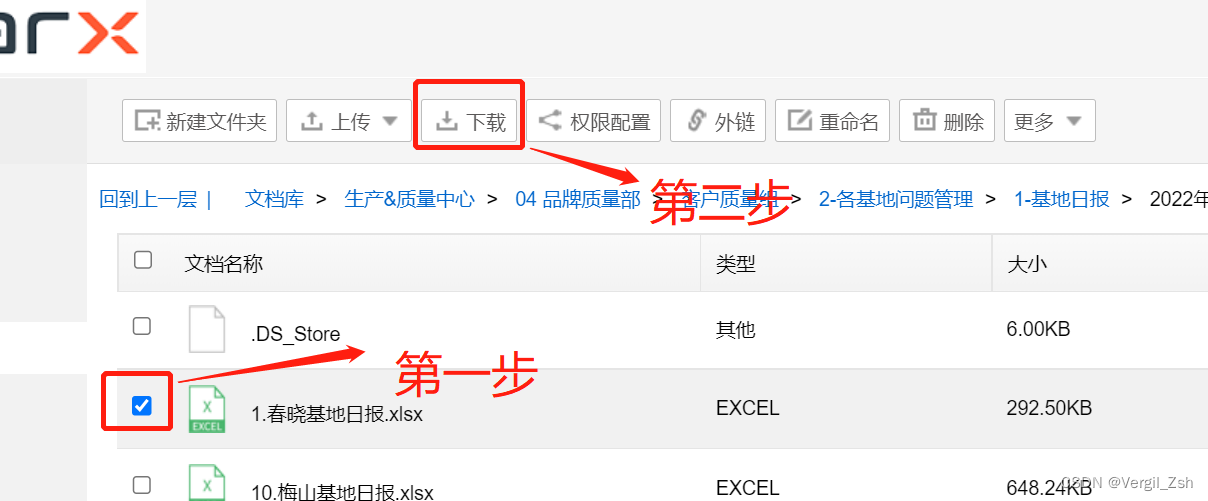
可以看到上面有很多目录点击过来的,要求下载所有的含有日报的excel,需进行小框选择后,才会出现下载按钮
下载一般是直接下载到浏览器默认的地址,这里我们可以进行自主修改,还是在options里进行配置,函数如下
# 设置默认地址
prefs = {'download.default_directory': r'D:\desktop\test_download'}
options.add_experimental_option('prefs', prefs)完整代码如下
# 导入所需要的库
import time
import json
import warnings
from selenium import webdriver
from sqlalchemy import create_engine
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 运行时terminal里面会出现好多警告,剔除警告
warnings.filterwarnings('ignore')
class Download():
def __init__(self, url, year, path, chrome, username, password, elements):
self.year = year
self.url = url
self.path = path
self.chrome = chrome
self.username = username
self.password = password
self.elements = elements
# 浏览器设置
def web_sets(self):
self.options = webdriver.ChromeOptions()
# 因为我使用的是谷歌浏览器
self.c_service = Service(f'{self.chrome}')
self.c_service.command_line_args()
# 设置后端服务器开始,因为会在后台产生好多服务,为了后面的关闭
self.c_service.start()
# 提供默认下载地址
self.prefs = {'download.default_directory': f'{self.path}'}
self.options.add_experimental_option('prefs', self.prefs)
# 设置忽略安全证书所带来的错误
self.options.add_argument('ignore-certificate-errors')
# 一些小的设置
self.options.add_experimental_option('excludeSwitches', ["enable-automation"])
self.options.add_argument('--np-sanbox')
self.options.add_argument('--disable-dev-shm-usage')
# 加属性避免bug
self.options.add_argument('disable-gpu')
# 添加无头模式
self.options.add_argument('headless')
self.br = webdriver.Chrome(f'{self.chrome}', chrome_options=self.options)
self.br.implicitly_wait(3)
def loginPage(self):
"""
因为我是将所有元素保存在json文件里面,这样就不需要因为find_element而占用好多列
也为代码节省地方
这里需要强调的时find_element(By.XPATH)是最新selenium的使用方法,之前的使用会报错
"""
self.br.get(self.url)
time.sleep(4)
self.br.find_element(By.XPATH, f'{self.elements[keys[2]]}').send_keys(self.username)
time.sleep(2)
self.br.find_element(By.XPATH, f'{self.elements[keys[3]]}').send_keys(self.password)
time.sleep(2)
self.br.find_element(By.XPATH, f'{self.elements[keys[4]]}').click()
time.sleep(2)
# 设置跳转到最后页面
def skipPage(self, url):
self.br.get(url)
time.sleep(2)
# 下载文件
def download_excel(self):
# 获取所有ul下面的li标签个数
ul2 = self.br.find_element(By.XPATH, f'{self.elements[keys[6]]}')
# 获取li标签数目
lis2 = ul2.find_elements(By.XPATH, 'li')
time.sleep(1)
# 循环li标签
for j in range(len(lis2)):
# 因为li的elements都是从1开始,python列表是从0开始,所以要+1
j+=1
# 获取li标签的text
name = self.br.find_element(By.XPATH, f'{self.elements[keys[7]][1]}'%j).get_attribute('title')
print(f'li标签name: {name}')
if '日报' in name:
print(f'第二遍过滤name: {name}')
li_test = self.br.find_element(By.XPATH, f'{self.elements[keys[8]]}'%j)
self.br.execute_script('arguments[0].click();',li_test)
time.sleep(0.5)
self.br.find_element(By.XPATH, f'{self.elements[keys[9]]}').click()
time.sleep(0.5)
li_test2 = self.br.find_element(By.XPATH, f'{self.elements[keys[8]]}'%j)
time.sleep(1)
# 设置点击覆盖,以防止报错
# 因为一直要模拟点击选择文件,然后进行下载文件,防止点击覆盖
self.br.execute_script("arguments[0].click();", li_test2)
time.sleep(8)
time.sleep(10)
time.sleep(12)
# 退出浏览器,推出后台服务
# c_service.stop()对应之前的c_service.stop()
self.br.quit();self.c_service.stop()
JSON文件
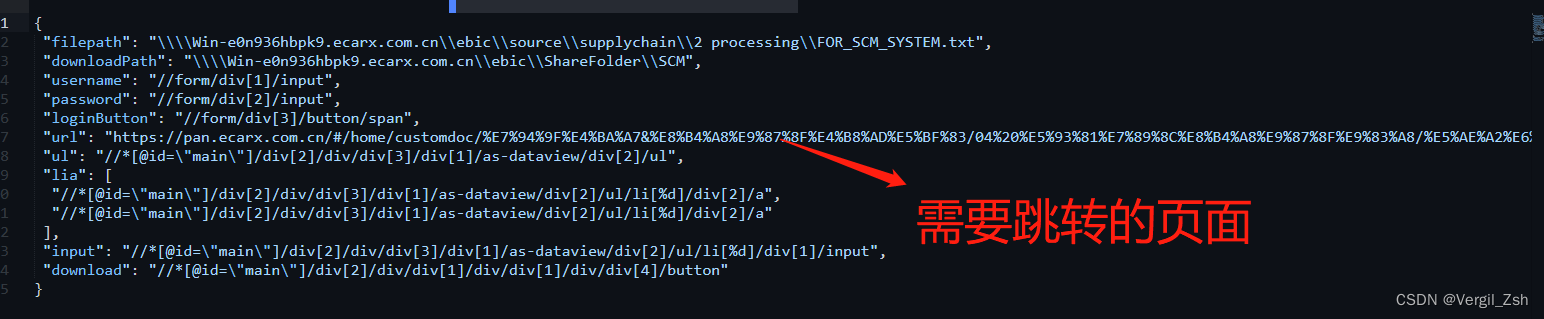
ul标签的展示

li标签下的title

在这里顺便讲下如何获取xpath的绝对路径或者相对路径
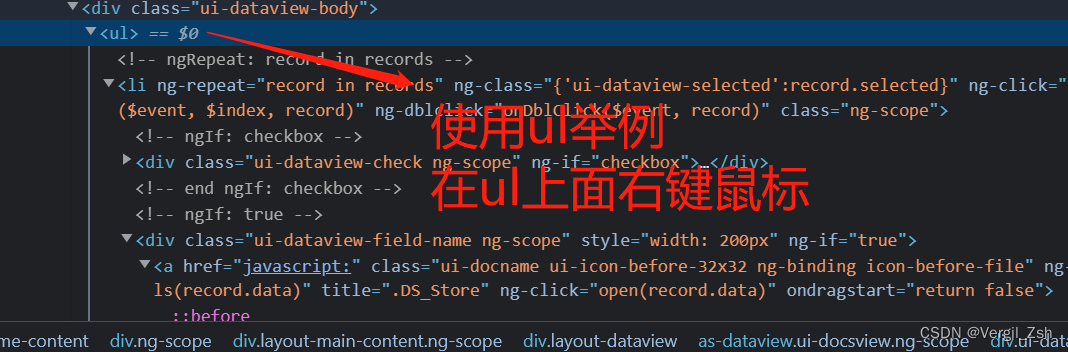
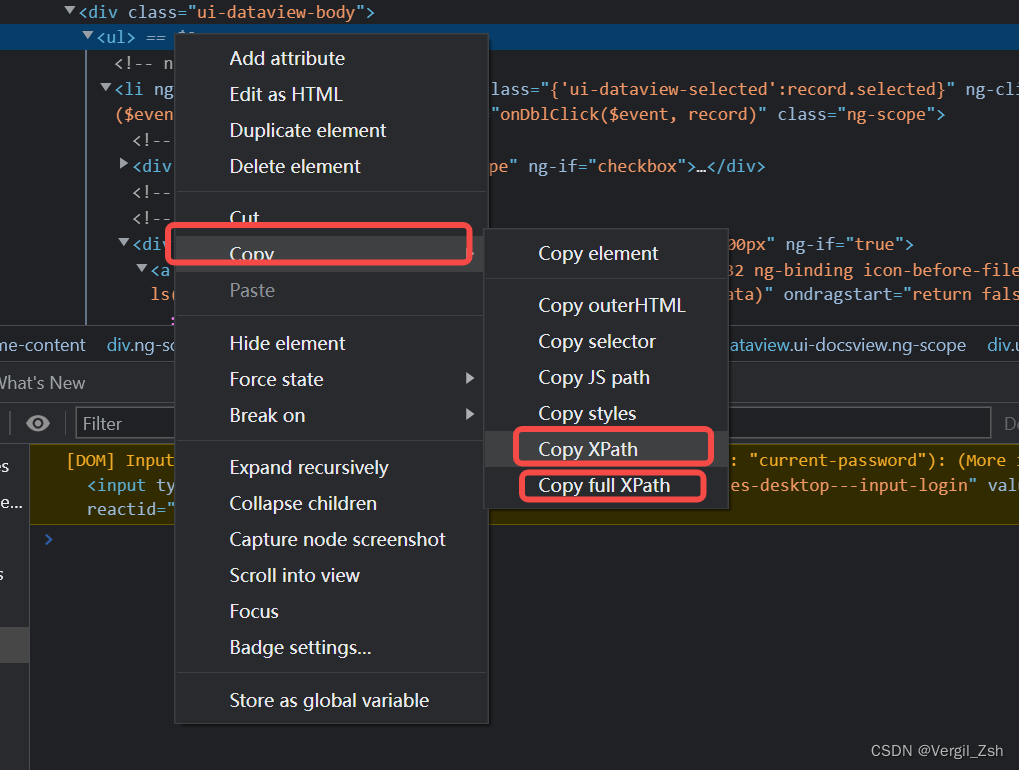
展示下ul标签相对路径和绝对路径
xpath: //*[@id="main"]/div[2]/div/div[3]/div[1]/as-dataview/div[2]/ul full_xpath: /html/body/div[2]/div[1]/div[2]/div/div[1]/div[2]/div/div[3]/div[1]/as-dataview/div[2]/ul
下图是没有c_service.stop(),后台运行服务,不能进行关闭

运行代码
if __name__ == '__main__':
jsonFile = r'JsonFile\elements.json'
with open(jsonFile, 'r') as f:
row_data = json.load(f)
# 获取所有json的键
keys = list(row_data.keys())
# 读取账号和密码
filename = row_data[keys[0]]
# 获取账号和密码txt
with open(filename, 'r') as f:
data = f.read()
data1 = data.split('\n')
url = 'url'
# chromedriver.exe
chrome = r'chromedriver.exe'
username = data1[0]
password = data1[1]
path = row_data[keys[1]]
year = time.gmtime().tm_year
start = Download(url, year, path, chrome, username, password, row_data)
start.web_sets()
start.loginWeb()
e = row_data[keys[5]]
start.skipPage(e)
start.download_excel()
time.sleep(15)为了展示出来 取消掉无头模式 这样可以看到浏览器进行下载
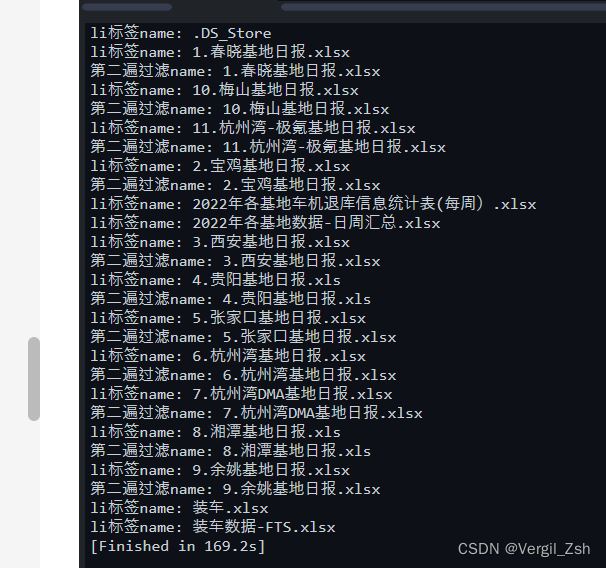
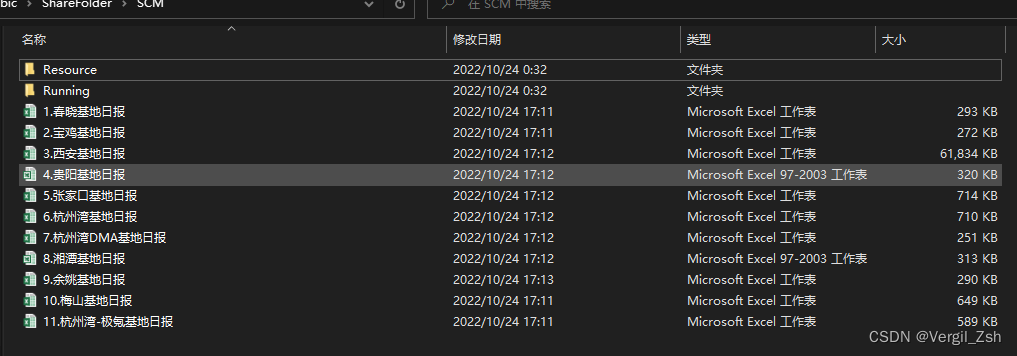
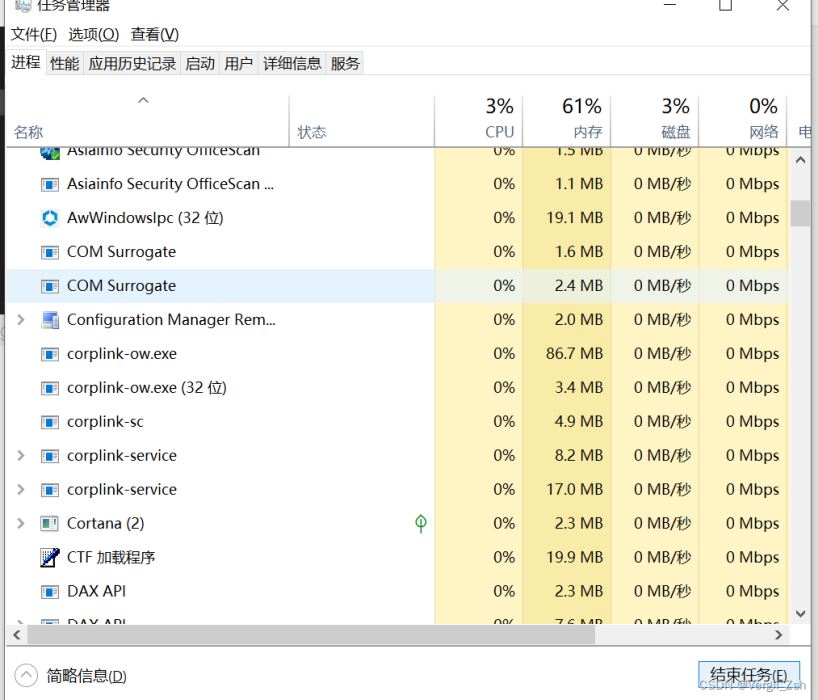
可以看到只有含有’日报’的数据被下载了,并且任务管理器里面没有刚才出现的Chrome32的服务
到此这篇关于python selenium参数详解和实现案例的文章就介绍到这了,更多相关python selenium参数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 virtualenv用于创建独立的Python环境,多个Python相互独立,互不影响,它能够:1. 在没有权限的情况下安装新套件 2. 不同应用可以使用不同的套件版本 3. 套件升级不影响其他应用2017-08-08
virtualenv用于创建独立的Python环境,多个Python相互独立,互不影响,它能够:1. 在没有权限的情况下安装新套件 2. 不同应用可以使用不同的套件版本 3. 套件升级不影响其他应用2017-08-08 这篇文章主要介绍了七种Python代码审查工具推荐,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了七种Python代码审查工具推荐,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
Python-OpenCV实战:利用 KNN 算法识别手写数字
K-最近邻(KNN)是监督学习中最简单的算法之一,KNN可用于分类和回归问题。本文将为大家介绍的是通过KNN算法实现识别手写数字。文中的示例代码介绍详细,需要的朋友可以参考一下2021-12-12
Tensorflow高性能数据优化增强工具Pipeline使用详解
这篇文章主要为大家介绍了Tensorflow高性能数据优化增强工具Pipeline使用详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-11-11 .ini配置文件常被用作存储程序中的一些参数,通过它程序可以变得更加灵活。下面这篇文章主要给大家介绍了关于python对配置文件.ini进行增删改查操作的方法示例,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。2017-07-07
.ini配置文件常被用作存储程序中的一些参数,通过它程序可以变得更加灵活。下面这篇文章主要给大家介绍了关于python对配置文件.ini进行增删改查操作的方法示例,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。2017-07-07
详解pytorch中squeeze()和unsqueeze()函数介绍
这篇文章主要介绍了详解pytorch中squeeze()和unsqueeze()函数介绍,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09 本文主要介绍了Python实现批量图片的切割,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-09-09
本文主要介绍了Python实现批量图片的切割,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-09-09 这篇文章主要介绍了Python使用py2exe打包程序介绍,本文讲解了py2exe简介、安装、用法、指定额外文件等内容,需要的朋友可以参考下2014-11-11
这篇文章主要介绍了Python使用py2exe打包程序介绍,本文讲解了py2exe简介、安装、用法、指定额外文件等内容,需要的朋友可以参考下2014-11-11 今天小编就为大家分享一篇tensorflow实现二维平面模拟三维数据教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
今天小编就为大家分享一篇tensorflow实现二维平面模拟三维数据教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 这篇文章主要介绍了Numpy之random使用学习,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-01-01
这篇文章主要介绍了Numpy之random使用学习,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-01-01










最新评论