
python3 chromedrivers签到的简单实现
更新时间:2023年03月21日 10:55:45 作者:时光凉春衫薄
本文主要介绍了python3 chromedrivers签到的简单实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
爬虫一般是useragent,或者js脚本交互验算的方式来反机器人爬虫,只是很多反爬虫容易被侦测出来容易被拦截,这里有个思路可以用webdrivers来驱动浏览器去爬虫,这样就可以绕过大多数的防爬机制(有些高级的防反爬虫也不行,比如验证码,鼠标轨迹验证等技术这样chromedriver就不管用了)
用chrome浏览器举例
第一下载安装chrome浏览器并查明版本号。
┌──(kali㉿kali)-[~]
└─$ apt-get install google-chrome-stable

然后照着浏览器去下载相应的chromedriver
下载地址:CNPM Binaries Mirror

下载后解压,将里面的chromedriver 复制到/usr/bin/ 目录下面(pach环境变量里面)即可

下面开始写脚本
from time import sleep
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
option = webdriver.ChromeOptions()
#设置chrome的浏览器选项
option.add_argument('--headless')
#设施chrome选项为无窗口运行
driver = webdriver.Chrome(chrome_options=option)
# 创建一个chrome浏览器,应用无窗口的配置。
driver.get("http://www.jsons.cn/ping/")
#用chrome去访问网页
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'txt_url')))
#让chrome显式等待driver这个对象,并最多等待10秒,当界面出现'txt_url'这个元素后在继续往下
driver.find_element(By.XPATH, '//*[@id="txt_url"]').send_keys('ss111d.yqw5ey.dnslog.cn')
#再出现//*[@id="txt_url"]这个元素后往这个元素里面填入ss111d.yqw5ey.dnslog.cn这个数值
driver.find_element(By.XPATH, '//*[@id="startbtn"]').click()
#然后找到//*[@id="startbtn"] 这个按钮模拟点击它
sleep(1)
#等待一秒后退出find_element(By.XPATH, '//*[@id="txt_url"]') 这个元素怎么来的?如下:
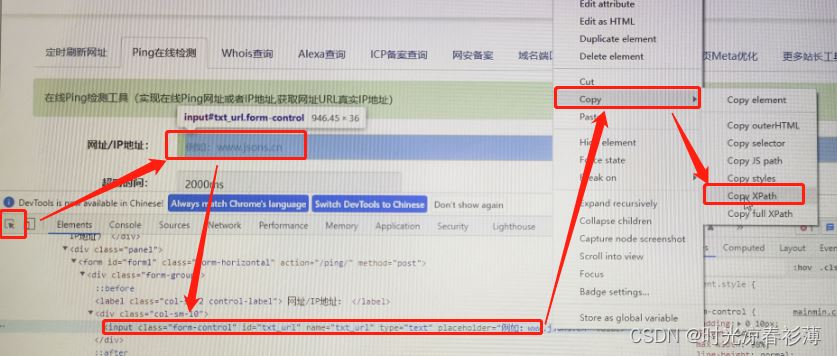
总的来说这个脚本就是用chrome 打开这个网站,然后输入这个dnslog的网址去ping一下。模仿人点击去测试网页

结果
其他:
下拉菜单如何选择?
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 创建一个 WebDriver 实例
driver = webdriver.Chrome()
# 访问网页
driver.get("https://example.com")
# 选择下拉框元素
select_box = driver.find_element(By.ID, "my_select_box")
# 初始化 Select 类
select = Select(select_box)
# 选择一个选项
select.select_by_value("option_value")
# 关闭 WebDriver 实例
driver.quit()在最新版本的 Selenium Python 包中,推荐使用 find_element 方法的新形式,即指定查找方式的参数 By,以及对应的选择器表达式,具体有以下几种用法:
- 通过元素 ID 查找元素:find_element(By.ID, id_)
- 通过元素 name 查找元素:find_element(By.NAME, name)
- 通过元素 class name 查找元素:find_element(By.CLASS_NAME, name)
- 通过元素标签名查找元素:find_element(By.TAG_NAME, name)
- 通过元素链接文本查找元素:find_element(By.LINK_TEXT, text)
- 通过元素部分链接文本查找元素:find_element(By.PARTIAL_LINK_TEXT, text)
- 通过元素 CSS 选择器查找元素:find_element(By.CSS_SELECTOR, css_selector)
- 通过元素 XPath 查找元素:find_element(By.XPATH, xpath)
到此这篇关于python3 chromedrivers签到的简单实现的文章就介绍到这了,更多相关python3 chromedrivers签到内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- Python第三方库undetected_chromedriver的使用
- python一招完美搞定Chromedriver的自动更新问题
- Python3爬虫ChromeDriver的安装实例
- 详解Python+Selenium+ChromeDriver的配置和问题解决
- Selenium执行完毕未关闭chromedriver/geckodriver进程的解决办法(java版+python版)
- python+selenium+chromedriver实现爬虫示例代码
- 下载与当前Chrome对应的chromedriver.exe(用于python+selenium)
- python selenium 执行完毕关闭chromedriver进程示例
相关文章
 这篇文章主要介绍了numpy数组的维度、轴详解,numpy数组的某个轴,指的是:该数组的某个维度的方向,其方向从索引号由底到高,许多numpy方法或函数在调用时,常常需要指定一个关键参数“axis=X”,它表示的是沿哪个轴的方向进行运算,需要的朋友可以参考下2023-09-09
这篇文章主要介绍了numpy数组的维度、轴详解,numpy数组的某个轴,指的是:该数组的某个维度的方向,其方向从索引号由底到高,许多numpy方法或函数在调用时,常常需要指定一个关键参数“axis=X”,它表示的是沿哪个轴的方向进行运算,需要的朋友可以参考下2023-09-09 Scrapy是一个基于Python的强大的开源网络爬虫框架,用于从网站上抓取信息,它提供了广泛的功能,使得爬取和分析数据变得相对容易,本文小编将给给大家介绍一下如何使用python框架Scrapy爬取数据,需要的朋友可以参考下2023-10-10
Scrapy是一个基于Python的强大的开源网络爬虫框架,用于从网站上抓取信息,它提供了广泛的功能,使得爬取和分析数据变得相对容易,本文小编将给给大家介绍一下如何使用python框架Scrapy爬取数据,需要的朋友可以参考下2023-10-10 这篇文章主要介绍了Python使用tkinter实现的摇骰子小游戏功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了Python使用tkinter实现的摇骰子小游戏功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-07-07 这篇文章主要给大家介绍了关于Django自定义过滤器的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2017-10-10
这篇文章主要给大家介绍了关于Django自定义过滤器的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2017-10-10 这篇文章主要介绍了python之timeit统计运行时间模块,这个技巧非常的实用,感兴趣的小伙伴可以试试2021-04-04
这篇文章主要介绍了python之timeit统计运行时间模块,这个技巧非常的实用,感兴趣的小伙伴可以试试2021-04-04 这篇文章主要介绍了Python使用lambda抛出异常实现方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08
这篇文章主要介绍了Python使用lambda抛出异常实现方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08 这篇文章主要介绍了基于Python第三方插件实现西游记章节标注汉语拼音的方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05
这篇文章主要介绍了基于Python第三方插件实现西游记章节标注汉语拼音的方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05 这篇文章主要为大家介绍了python中在进程结束后端口依然被占用的问题解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2022-01-01
这篇文章主要为大家介绍了python中在进程结束后端口依然被占用的问题解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2022-01-01 这篇文章主要介绍了python Jupyter运行时间实例过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python Jupyter运行时间实例过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12 在实际数据分析过程中,我们分析用Python来处理数据(海量的数据),我们都是把这个数据转换为Python的对象的,比如最为常见的字典,下面这篇文章主要给大家介绍了关于python保存字典数据到csv的相关资料,需要的朋友可以参考下2022-06-06
在实际数据分析过程中,我们分析用Python来处理数据(海量的数据),我们都是把这个数据转换为Python的对象的,比如最为常见的字典,下面这篇文章主要给大家介绍了关于python保存字典数据到csv的相关资料,需要的朋友可以参考下2022-06-06










最新评论