
Python采集电影评论实战示例
数据采集
我们上一篇介绍了,如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。我们今天来学习如何采集电影评论,看看这个电影好不好看。
发送请求
我们首先确定我们的目标网址,对我们需要获取的数据。
我们要把每一个评论获取下来,我们接下来用到开发者工具。我们看评论是在什么位置。是不是在网页源代码中。接下来,我们发送请求,获取网页源代码。
url = 'https://movie.douban.com/subject/35267208/comments'
params = {
'start': f'{num}',
'limit': '20',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
}
res = requests.get(url, headers=headers, params=params)
print(res)
这段代码中,我们首先定义了一个 URL,然后使用 requests.get() 函数获取该 URL 的数据,并将其存储在 res 变量中。最后,我们打印出 res 变量的值,即获取到的数据。
在这个例子中,我们使用了 params 参数来指定获取数据的起始位置和每页显示的记录数。在这个例子中,我们指定了起始位置为第 num 条记录,每页显示 limit 条记录。
请注意,这个例子中使用的 user-agent 头部是为了模拟浏览器的行为。在实际应用中,我们应该使用 User-Agent 头部来指定我们的请求类型,例如 requests.get() 函数默认使用 'requests/2.18.4' 作为 User-Agent。
解析数据
我们还可以获取其他信息,比如讲,地区,时间之类的。
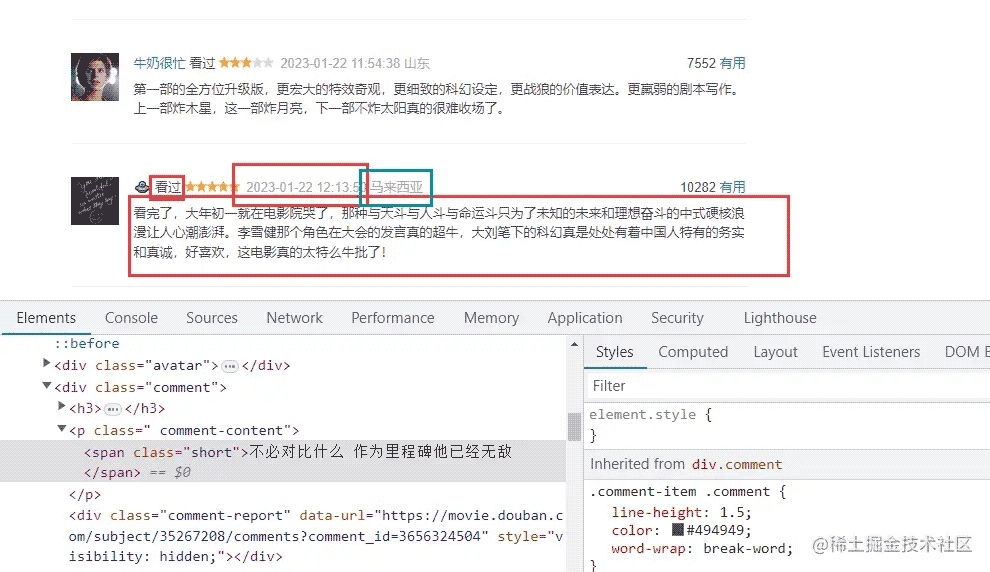
我们先解析数据。
selector = parsel.Selector(res.text)
info_lists = selector.css('div.comment-item')
这段代码中,我们首先使用 parsel 库中的 Selector 类来解析 res.text 中的内容,并将其转换为 CSS 选择器。然后,我们使用 css 方法来获取 CSS 选择器中的所有 div 元素,并将其存储在 info_lists 变量中。
需要注意的是,parsel 库中的 Selector 类是一个比较底层的 CSS 解析器,它并不会对 CSS 选择器进行任何优化或转换。因此,在使用 Selector 类时,我们需要确保输入的 CSS 选择器是有效的,并且不会包含任何无效的 CSS 属性或值。
获取内容
for info_list in info_lists:
# print(info_list)
name = info_list.css('.comment-info a::text').get()
rating = info_list.css('.rating::attr(title)').get()
times = info_list.css('.comment-time::attr(title)').get()
area = info_list.css('.comment-location::text').get()
vote_count = info_list.css('.vote-count::text').get()
short = info_list.css('.short::text').get()
这段代码中,我们使用 for 循环遍历 info_lists 中的每一个元素,并使用 css 方法获取该元素的 text 属性值。然后,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 name 变量中。接着,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 rating 变量中。最后,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 times 变量中。最后,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 area 变量中。最后,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 vote_count 变量中。最后,我们使用 get() 方法获取该属性值的 title 属性值,并将其存储在 short 变量中。
输出内容
print(name, rating, times, area, vote_count, short)
这段代码中,我们使用 print() 函数打印出了名称、评分、时间、地点、投票数和简短描述。
总结
在这个例子中,我们使用了parsel库中的 Selector 类和 css 方法来获取网页中的 CSS 选择器,并将其转换为相应的属性值。我们还可以使用其他方法来解析数据,例如使用 params 参数来指定获取数据的起始位置和每页显示的记录数,使用 headers 参数来指定 User-Agent 头部。我们还可以使用其他开发者工具来获取更多数据,例如使用网页源代码来获取网页中的所有评论。
以上就是Python采集电影评论的详细内容,更多关于Python采集电影评论的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章主要介绍了Python操作MySQL数据库的方法,文中示例代码非常详细,帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07
这篇文章主要介绍了Python操作MySQL数据库的方法,文中示例代码非常详细,帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07 下面小编就为大家带来一篇python 循环while和for in简单实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-08-08
下面小编就为大家带来一篇python 循环while和for in简单实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-08-08 这篇文章主要介绍了Python类和对象的定义与实际应用,结合三个具体案例形式分析了Python面向对象程序设计中类与对象的定义、应用、设计模式等相关操作技巧,需要的朋友可以参考下2018-12-12
这篇文章主要介绍了Python类和对象的定义与实际应用,结合三个具体案例形式分析了Python面向对象程序设计中类与对象的定义、应用、设计模式等相关操作技巧,需要的朋友可以参考下2018-12-12 在 Python 编程中,适当的代码逻辑分离可以帮助降低复杂度、提高可读性,减少大量的 if-else 结构,本文将深入探讨如何使用不同方法来改进代码结构,降低对 if-else 结构的依赖2023-12-12
在 Python 编程中,适当的代码逻辑分离可以帮助降低复杂度、提高可读性,减少大量的 if-else 结构,本文将深入探讨如何使用不同方法来改进代码结构,降低对 if-else 结构的依赖2023-12-12 常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth。Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下2021-06-06
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth。Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下2021-06-06 在数据分析和可视化的领域,选择合适的工具可以让我们事半功倍,本文主要为大家介绍两个工具,Streamlit和ECharts,感兴趣的小伙伴可以跟随小编一起了解下2023-09-09
在数据分析和可视化的领域,选择合适的工具可以让我们事半功倍,本文主要为大家介绍两个工具,Streamlit和ECharts,感兴趣的小伙伴可以跟随小编一起了解下2023-09-09 这篇文章主要介绍了Python实时监控网站浏览记录实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了Python实时监控网站浏览记录实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07 今天小编就为大家分享一篇Python计算机视觉里的IOU计算实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01
今天小编就为大家分享一篇Python计算机视觉里的IOU计算实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01 这篇文章主要介绍了python实现逢七拍腿小游戏的思路,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05
这篇文章主要介绍了python实现逢七拍腿小游戏的思路,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05 这篇文章主要介绍了分析并输出Python代码依赖的库的实现代码,需要的朋友可以参考下2015-08-08
这篇文章主要介绍了分析并输出Python代码依赖的库的实现代码,需要的朋友可以参考下2015-08-08










最新评论