
基于Python正则表达式提取搜索结果中的站点地址
更新时间:2015年10月15日 09:59:29 投稿:mrr
正则表达式对于Python来说并不是独有的,最近在鼓捣一个东西把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址,小编把具体实现思路整理分享给大家
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址。
这其中涉及几个需要解决的问题:
1、获取搜索的结果文本
为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果。
获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本
2、分析如何提取站点信息
首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息。
我使用IE8自带的开发工具(按F12就会弹出来)中的探查器功能查看自己要关心的内容有什么特殊的格式
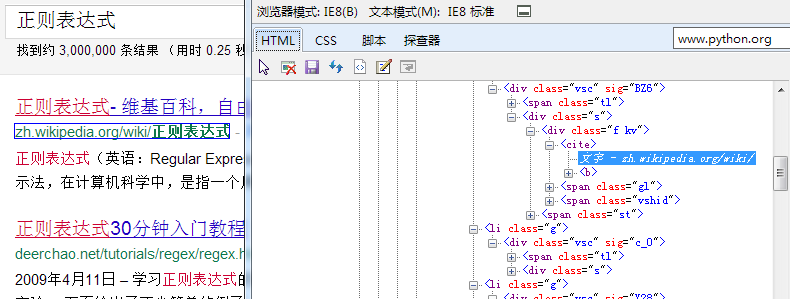
从上图可以看出我需要的站点在标签<cite></cite>中,所以我使用正则表达式提取这其中的文本是否就可以呢?
3、编写正则表达式来获取站点地址
接下来的就是写表达式了,我使用Python3.2编写的,方便好用(~_~)
代码如下,先把搜索结果页面保持到e:/t3.txt中,在执行如下代码
import re
p = re.compile(r'<cite>([^<>\/].+?)</cite>')
f = open("e:/t3.txt", encoding='utf-8')
content = f.read()
print ("\n".join(p.findall(content)))
运行如下:
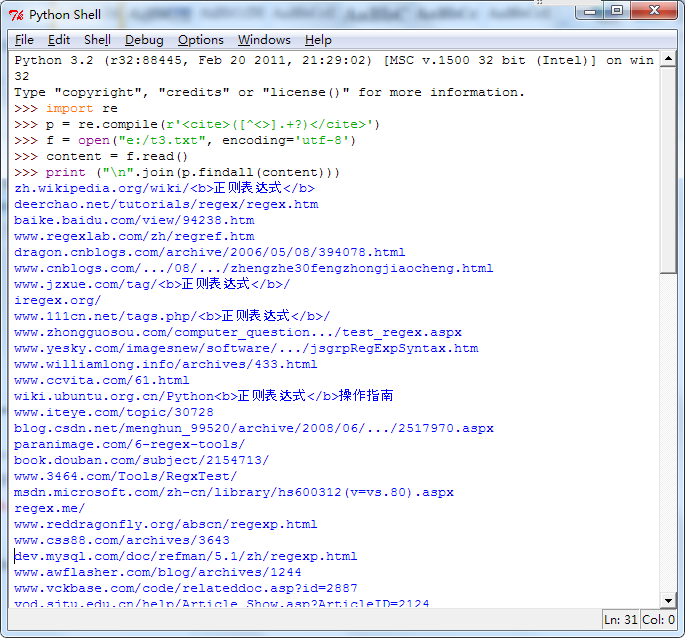
大家可以对照一下运行效果图,看看所有的站点地址是不是都给获取到了。
相关文章
 正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些ExtJS常用的表达式收集于此,以备不时之需2013-11-11
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些ExtJS常用的表达式收集于此,以备不时之需2013-11-11
Centos7 Shell编程之正则表达式、文本处理工具详解
正则表达式可以很灵活的提供各种模糊匹配的筛选规则。常被用来检索、替换那些符合某个模式的文本,这篇文章主要介绍了Centos7 Shell编程之正则表达式、文本处理工具,需要的朋友可以参考下2022-08-08 正则表达式也称为模式表达式,自身具有一套非常完整的、可以编写模式的语法体系,提供了一种灵活且直观的字符串处理方法,本文给大家介绍正则表达式如何在PHP里巧妙的应用,需要的朋友参考下吧2016-03-03
正则表达式也称为模式表达式,自身具有一套非常完整的、可以编写模式的语法体系,提供了一种灵活且直观的字符串处理方法,本文给大家介绍正则表达式如何在PHP里巧妙的应用,需要的朋友参考下吧2016-03-03
java正则表达式四种常用的处理方式(匹配、分割、替代、获取)
这篇文章主要为大家详细介绍了java正则表达式四种常用的处理方式,包括匹配、分割、替代、获取四种,感兴趣的小伙伴们可以参考一下2016-06-06 本文是小编在日常工作中积累并整理的有关一些常用的正则表达式(例如:匹配中文、匹配html),在此把全部内容分享在脚本之家网站,需要的朋友可以来脚本之家网站学习2015-10-10
本文是小编在日常工作中积累并整理的有关一些常用的正则表达式(例如:匹配中文、匹配html),在此把全部内容分享在脚本之家网站,需要的朋友可以来脚本之家网站学习2015-10-10 正则替换字符串功能...2007-10-10
正则替换字符串功能...2007-10-10 表单验证常用正则,非常不错,收集的相对比较完整,大家可以看看。2009-11-11
表单验证常用正则,非常不错,收集的相对比较完整,大家可以看看。2009-11-11 使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。2011-08-08
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。2011-08-08 正则表达式regular expression详述(一)...2006-06-06
正则表达式regular expression详述(一)...2006-06-06 正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具2020-04-04
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具2020-04-04










最新评论