
Python 爬虫学习笔记之多线程爬虫
XPath 的安装以及使用
1 . XPath 的介绍
刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省事 啊。其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷。可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,就好比说一个人想去天安门,地址的描述是左边有一个圆形建筑,右边是一个方形建筑,你去找吧,而使用 XPath 的话,地址的描述就变成了天安门的具体地址。怎么样?相比之下,哪种方式效率更高,找的更准确呢?
2 . XPath 的安装
XPath 包含在 lxml 库中,那么我们到哪里去下载呢? 点击此处 ,进入网页后按住 ctrl+f 搜索 lxml ,然后进行下载,下载完毕之后将文件拓展名改为 .zip ,然后进行解压,将名为 lxml 的文件夹复制粘贴到 Python 的 Lib 目录下,这样就安装完毕了。
3 . XPath 的使用
为了方便演示,我利用 Html 写了个简单的网页,代码如下所示(为了节省时间,方便小伙伴们直接进行测试,可直接复制粘贴我的代码)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Test Html</title>
</head>
<body>
<div id="content">
<ul id="like">
<li>like one</li>
<li>like two</li>
<li>like three</li>
</ul>
<ul id="hate">
<li>hate one</li>
<li>hate two</li>
<li>hate three</li>
</ul>
<div id="url">
<a href="http://www.baidu.com">百度一下</a>
<a href="http://www.hao123.com">好123</a>
</div>
</div>
</body></html>
用谷歌浏览器打开这个网页,然后右击,选择检查,会出现如下所示界面
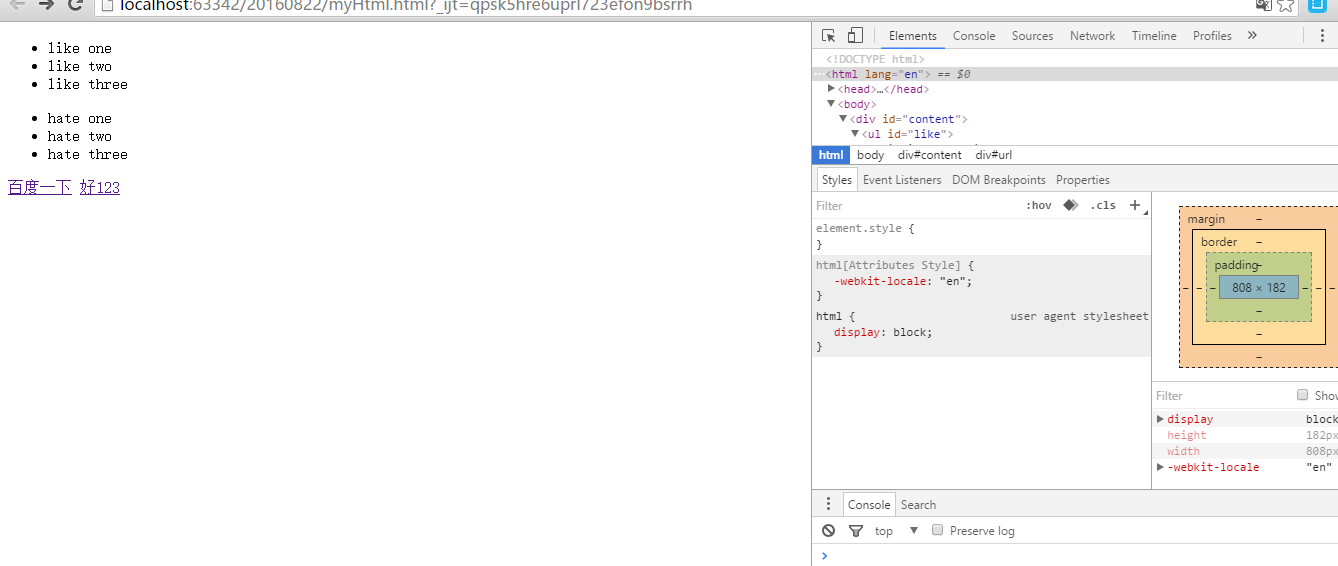
这个时候你鼠标右击任何一行 html 代码,都可以看到一个 Copy,将鼠标放上去,就可以看到 Copy XPath ,先复制下来,怎么用呢?
# coding=utf-8
from lxml import etree
f = open('myHtml.html','r')
html = f.read()
f.close()
selector = etree.HTML(html)
content = selector.xpath('//*[@id="like"]/li/text()')
for each in content:
print each
看看打印结果
like one like two like three
很显然,将我们想要的内容打印下来了,注意我们在 xpath() 中使用了 text() 函数,这个函数就是获取其中的内容,但是如果我们想获取一个属性,该怎么办?比如说我们想得到 html 中的两个链接地址,也就是 href 属性,我们可以这么操作
content = selector.xpath('//*[@id="url"]/a/@href')
for each in content:
print each
这个时候的打印结果就是
http://www.baidu.com http://www.hao123.com
看到现在大家大概也就对 xpath() 中的符号有了一定的了解,比如一开始的 // 指的就是根目录,而 / 就是父节点下的子节点,其他的 id 属性也是一步一步从上往下寻找的,由于这是一种树结构,所以也难怪方法的名字为 etree()。
4 . XPath 的特殊用法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <div id="likeone">like one</div> <div id="liketwo">like two</div> <div id="likethree">like three</div> </body> </html>
面对上面的一个网页,我们应该如何获取到三行的内容的 ? 嗯哼,很简单,我写三个 XPath 语句不就好了,so easy 。 如果真是这样,那么我们的效率好像是太低了一点,仔细看看这三行 div 的 id 属性,好像前四个字母都是 like, 那就好办了,我们可以使用 starts-with 对这三行进行同时提取,如下所示
content = selector.xpath('//div[starts-with(@id,"like")]/text()')
不过这样有一点麻烦的地方,我们就需要手动的去写 XPath 路径了,当然也可以复制粘贴下来在进行修改,这就是提升复杂度来换取效率的问题了。再来看看标签嵌套标签的提取情况
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="content">
<div id="text">
<p>hello
<b> world
<font color="#ffe4c4">
Python
</font>
</b>
</p>
</div>
</div>
</body>
</html>
像上面这样的一个网页,如果我们想获取到 hello world Python 语句,该怎么获取呢?很明显这是一种标签嵌套标签的情况,我们按照正常情况进行提取,看看结果如何
content = selector.xpath('//*[@id="text"]/p/text()')
for each in content:
print each
运行之后,很遗憾的,只打印出了 hello 字样,其他字符丢失了,该怎么办呢?这种情况可以借助于 string(.)如下所示
content = selector.xpath('//*[@id="text"]/p')[0]
info = content.xpath('string(.)')
data = info.replace('\n','').replace(' ','')
print data
这样就可以打印出正确内容了,至于第三行为什么存在,你可以将其去掉看看结果,到时候你自然就明白了。
Python 并行化的简单介绍
有人说 Python 中的并行化并不是真正的并行化,但是多线程还是能够显著提高我们代码的执行效率,为我们节省下来一大笔时间,下面我们就针对单线程和多线程进行时间上的比较。
# coding=utf-8
import requests
from multiprocessing.dummy import Pool as ThreadPool
import time
def getsource(url):
html = requests.get(url)
if __name__ == '__main__':
urls = []
for i in range(50, 500, 50):
newpage = 'http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=' + str(i)
urls.append(newpage)
# 单线程计时
time1 = time.time()
for i in urls:
print i
getsource(i)
time2 = time.time()
print '单线程耗时 : ' + str(time2 - time1) + ' s'
# 多线程计时
pool = ThreadPool(4)
time3 = time.time()
results = pool.map(getsource, urls)
pool.close()
pool.join()
time4 = time.time()
print '多线程耗时 : ' + str(time4 - time3) + ' s'
打印结果为
http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=100 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=150 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=200 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=250 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=300 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=350 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=400 http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=450 单线程耗时 : 7.26399993896 s 多线程耗时 : 2.49799990654 s
至于以上链接为什么设置间隔为 50,是因为我发现在百度贴吧上没翻一页,pn 的值就会增加 50。 通过以上结果我们发现,多线程相比于单线程效率提升了太多太多。至于以上代码中多线程的使用,我就不再过多讲解,我相信只要接触过 Java 的人对多线程的使用不会陌生,其实都是大差不差。没有接触过 Java ?那就对不起了,以上代码请自行消化吧。
实战 -- 爬取当当网书籍信息
一直以来都在当当网购买书籍,既然学会了如何利用 Python 爬取信息,那么首先就来爬取一下当当网中的书籍信息吧。本实战完成之后的内容如下所示

在当当网中搜索 Java ,出现了89页内容,我选择爬取了前 80 页,而且为了比较多线程和单线程的效率,我特意在这里对二者进行了比较,其中单线程爬取所用时间为 67s,而多线程仅为 15s 。
如何爬取网页,在上面 XPath 的使用中我们也已经做了介绍,无非就是进入网页,右击选择检查,查看网页 html 代码,然后寻找规律,进行信息的提取,在这里就不在多介绍,由于代码比较短,所以在这里直接上源代码。
# coding=utf8
import requests
import re
import time
from lxml import etree
from multiprocessing.dummy import Pool as ThreadPool
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def changepage(url, total):
urls = []
nowpage = int(re.search('(\d+)', url, re.S).group(1))
for i in range(nowpage, total + 1):
link = re.sub('page_index=(\d+)', 'page_index=%s' % i, url, re.S)
urls.append(link)
return urls
def spider(url):
html = requests.get(url)
content = html.text
selector = etree.HTML(content)
title = []
title = selector.xpath('//*[@id="component_0__0__6612"]/li/a/@title')
detail = []
detail = selector.xpath('//*[@id="component_0__0__6612"]/li/p[3]/span[1]/text()')
saveinfo(title,detail)
def saveinfo(title, detail):
length1 = len(title)
for i in range(0, length1 - 1):
f.writelines(title[i] + '\n')
f.writelines(detail[i] + '\n\n')
if __name__ == '__main__':
pool = ThreadPool(4)
f = open('info.txt', 'a')
url = 'http://search.dangdang.com/?key=Java&act=input&page_index=1'
urls = changepage(url, 80)
time1 = time.time()
pool.map(spider, urls)
pool.close()
pool.join()
f.close()
print '爬取成功!'
time2 = time.time()
print '多线程耗时 : ' + str(time2 - time1) + 's'
# time1 = time.time()
# for each in urls:
# spider(each)
# time2 = time.time()
# f.close()
# print '单线程耗时 : ' + str(time2 - time1) + 's'
可见,以上代码中的知识,我们都在介绍 XPath 和 并行化 中做了详细的介绍,所以阅读起来十分轻松。
好了,到今天为止,Python 爬虫相关系列的文章到此结束,谢谢你的观看。
相关文章
 今天小编就为大家分享一篇解决python中 f.write写入中文出错的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10
今天小编就为大家分享一篇解决python中 f.write写入中文出错的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10 这篇文章主要为大家详细介绍了python实现简易的学生信息管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05
这篇文章主要为大家详细介绍了python实现简易的学生信息管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05 这篇文章主要介绍了图解Python中深浅copy(通俗易懂),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09
这篇文章主要介绍了图解Python中深浅copy(通俗易懂),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09 openpyxl模块是一个读写Excel 2010文档的Python库,如果要处理更早格式的Excel文档,需要用到额外的库,openpyxl是一个比较综合的工具,能够同时读取和修改Excel文档,下面这篇文章主要给大家介绍了关于Python第三方常用模块openpyxl的相关资料,需要的朋友可以参考下2022-08-08
openpyxl模块是一个读写Excel 2010文档的Python库,如果要处理更早格式的Excel文档,需要用到额外的库,openpyxl是一个比较综合的工具,能够同时读取和修改Excel文档,下面这篇文章主要给大家介绍了关于Python第三方常用模块openpyxl的相关资料,需要的朋友可以参考下2022-08-08 这篇文章主要为大家详细介绍了python爬虫实例,包括爬虫技术架构,组成爬虫的关键模块,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
这篇文章主要为大家详细介绍了python爬虫实例,包括爬虫技术架构,组成爬虫的关键模块,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06 这篇文章主要为大家介绍了Pandas数据处理库画图与文件读取使用示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-10-10
这篇文章主要为大家介绍了Pandas数据处理库画图与文件读取使用示例,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-10-10 这篇文章主要介绍了python特性语法之遍历、公共方法、引用的相关资料,需要的朋友可以参考下2018-08-08
这篇文章主要介绍了python特性语法之遍历、公共方法、引用的相关资料,需要的朋友可以参考下2018-08-08 这篇文章主要为大家详细介绍了python面向对象编程设计原则之单一职责原则,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03
这篇文章主要为大家详细介绍了python面向对象编程设计原则之单一职责原则,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03 这篇文章主要为大家介绍了Python内建类型list源码学习,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了Python内建类型list源码学习,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 这篇文章主要介绍了python中的opencv 图像分割与提取,图像中将前景对象作为目标图像分割或者提取出来。对背景本身并无兴趣分水岭算法及GrabCut算法对图像进行分割及提取。具体实现过程需要的朋友可以参考下面文章详细介绍2022-06-06
这篇文章主要介绍了python中的opencv 图像分割与提取,图像中将前景对象作为目标图像分割或者提取出来。对背景本身并无兴趣分水岭算法及GrabCut算法对图像进行分割及提取。具体实现过程需要的朋友可以参考下面文章详细介绍2022-06-06










最新评论