
Mysql行格式索引页详解
本篇文章以InnoDB存储引擎为例,主要讲两个大知识点。
- 行格式
- 索引页(也就是我们说的数据页)
行格式
先想一个问题,MySql是什么?是一个数据库系统?用来干什么的? 我们先来简化一下MySql,MySql其实也是一个软件,它只是给我们管理数据,然后方便我们对数据进行增删改查,就像Spring一样,它给我们管理Java对象,然后方便我们使用。
那既然是给我们管理数据,那肯定就会将我们的数据保存起来,这样就会涉及到一个问题?如何保存这样数据?以怎样的格式保存这些数据? 为了方便并且高效的管理数据MySql肯定会设计一套自己的方案来管理。我们来以行格式开始讲起。
行格式是什么? 我们平时向表里面插入一条记录,这条记录以什么的格式进行保存,就是我们要讲的东西,InnoDB主要有以下四种行格式
- COMPACT 本文主要讲的行格式
- REDUNDANT 是很古老的行格式了, MySQL 5.0 版本之前用的行格式
- DYNAMIC InnoDB的默认行格式,理解了COMPACT 行格式就会理解这个,只有一小点不同
- COMPRESSED 我也了解很少,所以不讲
先来看看COMPACT行格式都包含哪些信息
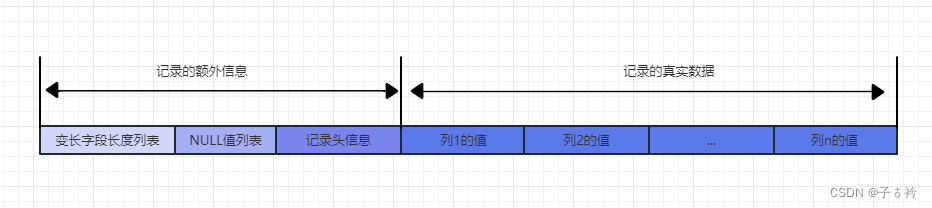
当我们插入一条记录的时候MySql并不是只保存了我们插入的数据,它还会记录很多额外的信息,这些额外的信息都是为了更好的帮我们管理数据。
变长字段长度列表
可能我们经常听到char类型是指定多少长度就要占用多少长度,比如我们指定char(100)个长度,但是我们实际只存储了一个“1”这个时候char也是占用100个长度的空间的,所以这种类型我们用的相对比较少,我们常用varchar,而这个varchar就是变长的,我们指定的长度只是表示最大能存放多少,实际占用的空间是你存了多少就占用多少空间,注意这里有个 编码的问题,当我们指定编码格式为 ascii时一个字符占用一个字节,当我们指定为utf8时占用3个字节,当指定utf8mb4时则占用四个字节,而varchar指定的是能存多少个已某种方式编码的字符,而不是多少个字节,假设我们使用utf8编码,使用varchar(100),则这个字段最多能存储100个字符,占用的空间最大是 100 * 3个字节
那这个变长字段长度列表有什么用呢?
我们知道varchar是变长的了,你给我多少个字符我就存储多少个,这样确实是省了空间了,但是我们很快就发现一个问题,我们读取数据的时候怎么办,我们该读多少?所以必须有个地方记录下来,每个字段实际占用多少空间,这样我们读的时候就能顺利读取,而这个长度就存放在记录在 一条记录开头。
每一个varchar类型的字段并且实际值不为NULL的字段的值的长度都会保存在这个列表里,每个字段的长度是逆序存放在这个列表里的(为啥要逆序放?后面讲)
上面我们存储的数据比较少用一个字节就能记录下,在现实中我们可能指定一个非常大的长度,这样的话用一个字节可能就记录不下了。所以MySql肯定有针对此的一套规则,理解这套规则我们需要区分开 varchar(10)这个10指的是最多能存储10个字符,并不是10个字节,当我们使用utf8编码时一个字符占用3个字节,10个字符表示最多能占用 3 * 10=30个字节,所以当我们的字段最大能存储的字节不超过255时,注意是字节!字节!字节!使用一个字节就能记录这个字段的长度,而当这个字段的最大长度超过255字节时则分为两种情况
- 情况一:当实际占用的字节小于等于127字节时使用一个字节记录这个长度
- 情况二:当实际占用的字节大于127时使用两个字节记录这个长度
NULL值列表
大多数情况下我们的列都会允许为NULL,那这个NULL在MySql是如何存储的呢?
MySql为那些可以为NULL的字段专门弄了一个NULL列表,该列表中用位图的表示形式来表示某个字段是否为NULL。
假设我们有表中有三个字段,并且这三个字段都可以为NULL,那这个NULL列表就会占用一个字节,一个字节有8个比特,每个比特对应一个字段,并且也是逆序对应的和上面的变长字段长度列表一样,如果某个字段对应的比特位为1则代表这个字段为NULL,反之不为NULL
NULL值列表占用的空间很少,比如我们表中有不超过8个的允许为NULL字段,这个时候使用一个字节就能记录下,当超过了8个就使用2个字节记录,2个字节实际上可以记录16个字段,即使我们只有11个允许为NULL的字段也会占用两个字节,使用0进行对齐,如此类推当我们超过了16个允许为NULL的字段的时候就使用3个字节或者更多来描述,总之就是一个字节可以描述8个字段,并且使用0进行对齐。
一条记录到底是如何存储的?
现在我们创建一个表, 并且插入两条记录
Create table t_test(
c1 varchar(10),
c2 varchar(10),
c3 char(10)
) charset=ascii;
insert into t_test(c1, c2, c3) values('aaa', 'bb', 'c');
insert into t_test(c1, c2, c3) values('d', NULL, NULL)
讲了这么多我们来一个图看看这两条记录到底是如何存储的

再次强调变长字段长度列表和NULL值列表都是逆序对应某个字段的

char类型的字段并不在变长字段长度列表中(但实际也有可能会在变长字段长度列表中,后面讲),而且我们c3这个字段实际只存储了 ‘c’ 这个值,但是MySql把我们没有使用的空间存储成了0x20(空格)
第二条数据

可以发现为NULL的字段并不占用实际的存储空间,MySql只会存储不为NULL的字段,这都得益于NULL值长度列表
char的特殊情况
经过上面的介绍我们知道char类型是定长的,并且不会出现在变长字段长度列表中,但是实际可能并不如此,因为现实中我们基本不可能使用ascii编码,而是使用utf8或者utf8mb4等变长编码,注意ascii是一个定长编码,在这个编码的中每个字符都只占用一个字节,而像utf8这种变长编码则不一定,它是占用1~3个字节,所以当我们字段的编码是变长编码时char类型的字段也会存储到变长字段长度列表中。
那既然都会存储到变长字段长度列表中它与varchar有什么区别呢?
使用char时规定即使这个字段实际只存储了1个字节但也会占X个字节,这个X就是我们在char(X)指定的长度,例如:char(10) charset=utf8但是我们只存储了一个 ‘a’ ,实际上’a’只占用一个字节,但是使用char就意味着最少需要占10个字节,即使我们实际只存储了一个字节
记录头信息
再来简单了解以下记录头信息, 我们先记住 record_type、next_record
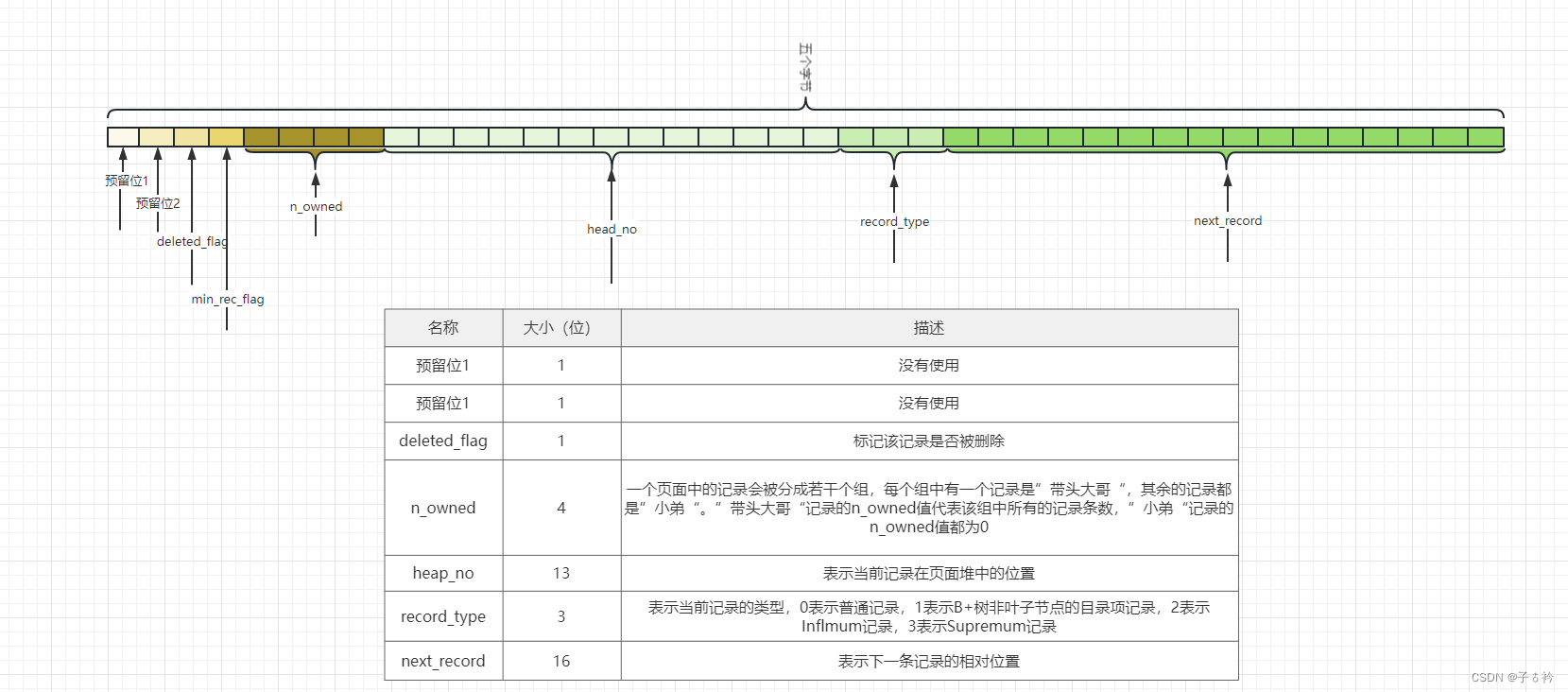
这里再来讲一下MySql如何删除数据的,当我们执行一条 delete from table where id = 1 时,该条记录并不会被真正的删除,而是打上一个标记,表示这表记录已经删除了,有人可能会有疑惑,那这样不就会浪费很多存储空间吗?不是的,实际上被删除的数据会组成一个链表,当我们插入数据时就会去这个链表上找已经删除的数据,然后将已经删除的数据覆盖,这样做的好处就是可以提高删除性能,不至于我们每次删除数据的时候都要去移动这些数据,为什么会移动数据?就像我们使用ArrayList一样当我们删除一条记录之后,后面的记录要向前移动,而只打一个删除标记,后面我们在重用这个空间就能避免数据移动
索引页(数据页)
MySql的数据都是存储在磁盘中的,当我们需要查询数据时它就会去磁盘加载数据,这里就会有一个问题,我们一次性加载多少数据?一条一条的加载吗?
这样的话就太慢了,所以MySql将存储空间分一个很多个页,每个页默认是占用16KB,这个页就是MySql每次加载数据的基本单位。
页又分为很多中类型,比如:index页、undo页、XDES页、INODE页等
我们的每一条记录都是存储在一个类型为 index页的上面,这个页就是我们称的索引页(外面都是叫数据页,数据页即是索引页)
先来看下索引页的结构

| 名称 | 描述 | 占用大小 |
|---|---|---|
| File Header | 文件头部,用来表示一些页的通用信息 | 38字节 |
| Page Header | 页面头部,表示数据页的专有信息 | 56字节 |
| User Record | 用户记录,存储我们插入的数据 | 不确定 |
| Free Space | 空闲空间 | 不确定 |
| Page Directory | 页目录 | 不确定 |
| File Trailer | 文件尾,校验页是否完整 | 8字节 |
这整个页就是占用 16KB
我们重点只关注 UserRecord部分,因为我们的用户记录就是存储在这个部分。
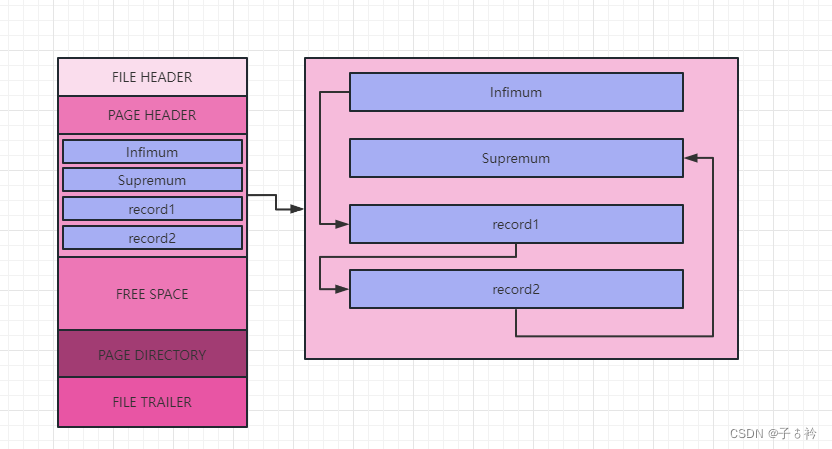
record1和record2就是我们的用户记录,且这每条记录都是按照我们上面的行格式存储的,每条记录都会组成一个链表,那这个链表是如何形成的呢?
还记得我们上面的行格式中,有个记录头,里面有个next_record字段,这个字段就指向下一条记录,通过这个字段每条记录之间就组成了一条链表,可以看到除了我们自己插入的两条记录外还有两个分别叫 Infimum和Supremum的东西,其实这也是两条记录,只不过不是我们手动插入的记录,而是MySql为什么自动生成记录,所以也叫虚拟记录,Infimum记录表示最小的记录,而Supremum表示最大的记录,这是规定,规定这两条记录就是分别代表最小的记录和最大的记录,在这个数据页中没有记录会比Infimum记录小,也没有记录比Supremum记录大,每个页中的记录都是有序的,会根据主键进行排序,当我们没有显示指定主键时,并且表没有不允许为NULL并且建立了唯一索引的字段时,MySql就会为我们生成一个row_id的字段作为主键。
Infimum记录指向的下一条记录就是这个页中用户记录(我们自己插入的记录)的最小记录,而指向Supremum记录的用户记录就是这个页中的最大记录。
刚开始时这个页就只有Infimum记录和Supremum记录,当我们执行insert语句向这个页插入数据的时候就会向FreeSpace申请空间,然后就存储这条记录,直到这个数据页中没有可用空间,就会申请新的索引页来保存数据
现在假设一个数据页中存储了7条记录,当我们要查找数据时如何查找?
当我们要查询 record5时难道从头开始遍历这个页中的所有数据进行比对吗?
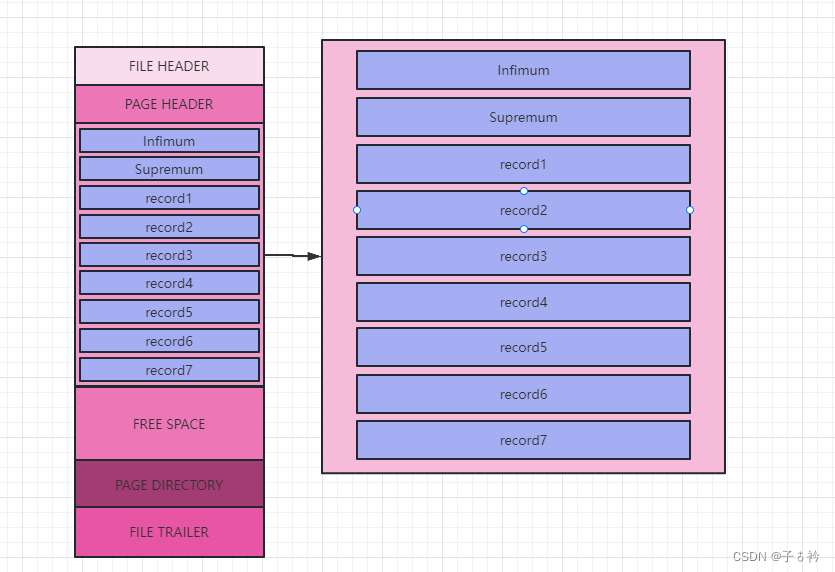
每个数据页都有一个叫页目录的东西,可以想象以下我们平时看书时,当我们要查找某个内容时都会先看目录,然后快速定位到这个内容所在的页,索引页中的页目录也是如此。
它把记录分成多个组,当这个数据页中即使没有一条用户记录时也会存在两个组,即Infimum和Supremum组,那每个组的的记录数又是多少呢?
对于Infimum所在的组只能有Infimum这一条记录,而对于Supremum所在的组可以存储1~8条数据,而其他组则存储4~8条数据。
然后把每个分组中的最大记录地址存储到页目录中,而页目录中的每个元素都称为槽

当我们只有7条用户记录时,这个页中分为两个组,一个是Infimum记录所在的组,一个是Supremum所在的组,而Supremum所在的组是可以存储1~8条记录的,所以这里刚好两个组就能存储下。
当我们再插入一条记录时,就会再分裂出一个组,一个组存储4条记录,一个组存储5条记录
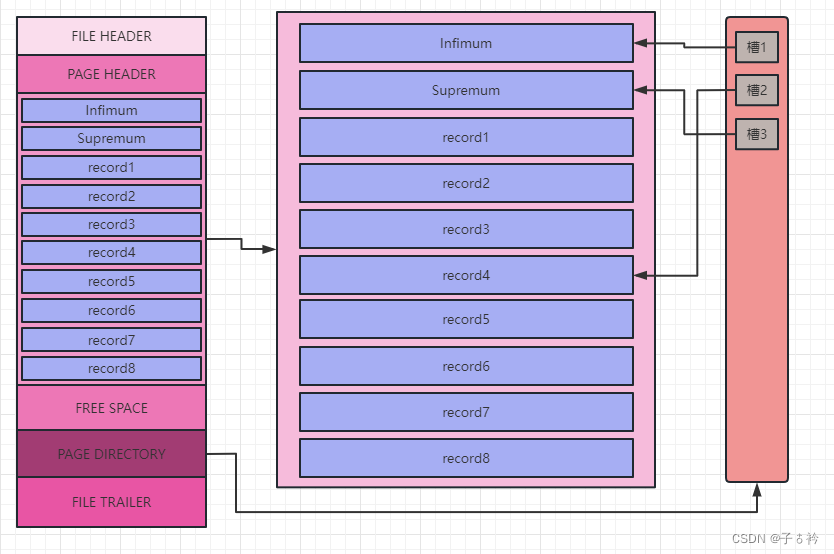
当我们需要查找某个数据时就直接遍历槽就可以了,就避免了遍历页中的所有数据
多个索引页中如何查找数据
上面介绍的是在一个索引页中如何查找数据,但是在实际中我们的数据会占用很多个索引页,那如何在多个索引页中查找数据?
我们先做一个大胆的假设,假设每个页只能存储3条记录,并且先暂时去掉Infimum记录和Supremum记录。
如果每个页只能存储三条记录的话,此时我们有9条记录,那就需要占用3个数据页,并且数据页之间组成了一个双向链表,像下面这样
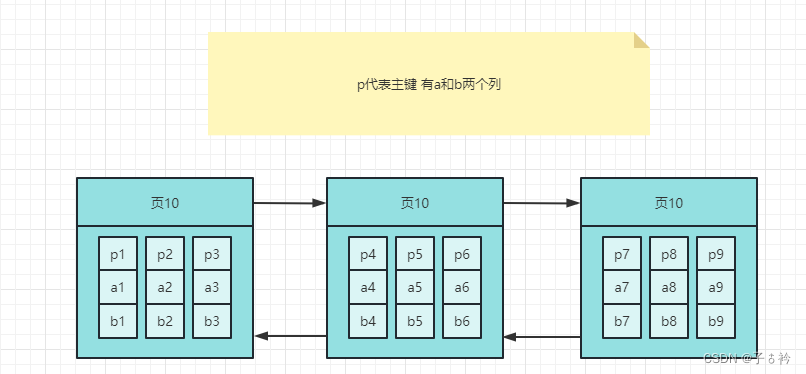
如果我们需要查找 p8这条数据如何查找?难道遍历每个页吗?
然后在页中又遍历每个槽,如果我们的数据很多很多,需要很多索引页,那这样的查找速度就太慢了,很显然MySql不可能这么干。
我们想一想我们在一个页中是如何查找数据的?我们会把记录分为一组一组的,然后额外记录每个组的最大记录,我们把记录每个组最大记录的地方称为槽,然后我们在查找数据时就只需要遍历槽就可以了。
在多个数据页中查找多个记录也是类似的,我们可以把每个页存储的最小记录单独记录起来
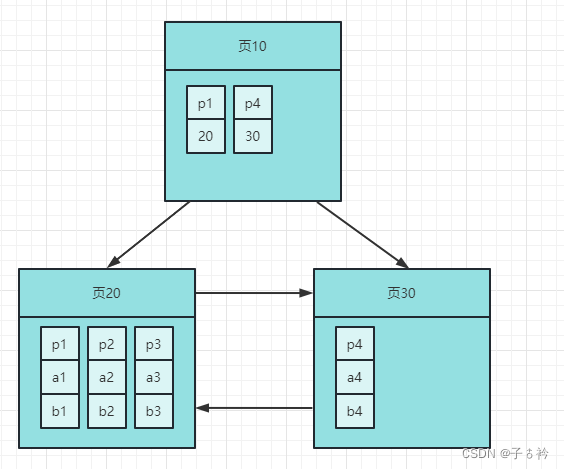
再新开一个索引页,记录每个页中的最小主键值还有起所在的页号,假设我们需要查找 p3时我们就直接到页10中查找,发现 p1 < p3 < p4从而定位到 页20,然后在页中遍历每个槽就能很容易的找到某条记录
心得
- 每条记录是如何存储的
- 每条记录都会有我们的真实数据和一些额外数据
- 数据在索引页中会组成一个链表
- 删除数据时只是打了一个删除标记,并不是真正的数据
- 删除的数据也会组成一个链表,称为垃圾链表
- 每个索引页中会生成两条虚拟记录分别是Infimum和Supremum记录
- 会将页中的记录分为很多个组,每个组的最大记录会记录到一个称为槽的地方
- 当在单个索引页查找数据时会遍历每个槽来查找数据
- 在有多个索引页时会记录每个页的最小记录以及该记录所在的页号
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要为大家详细介绍了Linux环境Mysql5.7.12安装教程,感兴趣的小伙伴们可以参考一下2016-06-06
这篇文章主要为大家详细介绍了Linux环境Mysql5.7.12安装教程,感兴趣的小伙伴们可以参考一下2016-06-06 本文主要介绍了MYSQL统计逗号分隔字段元素的个数,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01
本文主要介绍了MYSQL统计逗号分隔字段元素的个数,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01 事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部失败,是一个整体。MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的数据是不相同的2022-09-09
事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部失败,是一个整体。MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的数据是不相同的2022-09-09 这篇文章主要介绍了MySQL占用CPU过高排查过程及可能优化方案,具有很好的参考价值,希望对大家的学习或工作有所帮助,感兴趣的朋友可以参考下2024-01-01
这篇文章主要介绍了MySQL占用CPU过高排查过程及可能优化方案,具有很好的参考价值,希望对大家的学习或工作有所帮助,感兴趣的朋友可以参考下2024-01-01 这篇文章主要介绍了SQL之各种join小结详细讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了SQL之各种join小结详细讲解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08 这篇文章主要为大家介绍了MySQL on k8s 云原生环境部署实现过程详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09
这篇文章主要为大家介绍了MySQL on k8s 云原生环境部署实现过程详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-09-09
MySQL 5.5的max_allowed_packet属性的修改方法
今天在部署一个实验系统的时候,报错提示需要修改一下MySQL的配置文件,在修改的时候是有技巧的,大家可以参考下本文尝试操作下2013-08-08
MySQL中的datediff()方法和timestampdiff()方法的应用示例小结
在MySQL中,DATEDIFF()函数和TIMESTAMPDIFF()函数用于计算日期和时间之间的差异,TIMESTAMPDIFF()函数返回的结果是整数,但你可以通过在计算过程中使用适当的除法来获得所需的小数部分,本文介绍MySQL中的datediff()方法和timestampdiff()方法的应用,感兴趣的朋友一起看看吧2023-12-12 这篇文章主要介绍了MySQL如何基于Explain关键字优化索引功能,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了MySQL如何基于Explain关键字优化索引功能,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了sql ROW_NUMBER()与OVER()方法案例详解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了sql ROW_NUMBER()与OVER()方法案例详解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08










最新评论