
PostgreSQL数据库备份还原全攻略
前言
- 逻辑备份
即SQL转储方式,使用pg_dump和pg_dumpall进行备份。逻辑备份在恢复时,介于逻辑备份与故障时间点之间的数据难以恢复,所以逻辑备份适用于留存某个时间点的备份或进行跨平台跨版本的数据迁移。 - 文件系统级备份
即拷贝数据文件的完整目录,备份时需要关闭数据库。恢复数据库时,只需将数据目录复制到原来的位置。该方式实际工作中很少使用。 - 连续归档
该方式是把一个文件系统级别的全量备份和WAL(预写式日志)级别的增量备份结合起来。当需要恢复时,我们先恢复文件系统级别的备份,然后重放备份的WAL文件,把系统恢复到之前的某个状态。
本文主要介绍逻辑备份和连续归档方式的备份及还原,文件系统级备份由于比较简单,这里不在赘述。
以下操作使用的数据库版本为PostgreSQL 12.5,不同的数据库版本在进行连续归档操作时会有细微差异。
一、逻辑备份
1.pg_dump工具
以下为pg_dump工具的常用参数选项(更多参数可使用pg_dump --help查看)
联接选项: -h, --host=主机名 数据库服务器的主机名或套接字目录 -U, --username=名字 以指定的数据库用户联接 -d, --dbname=DBNAME 对数据库 DBNAME备份 -p, --port=端口号 数据库服务器的端口号 -w, --no-password 永远不提示输入口令 -W, --password 强制口令提示 (自动) --role=ROLENAME 在转储前运行SET ROLE 一般选项: -f, --file=FILENAME 输出文件或目录名,导出到指定文件 -F, --format= p|c|d|t 导出文件格式(p|c|d|t) p:plain-输出普通文字SQL脚本(默认); c:custom-输出自定义归档格式,适用于pg_restore导入,该格式是最灵活导出方式,允许在导入时自定义选择和重 排序归档条目。该格式默认启用压缩; d:directory-输出文件夹归档格式,适用于pg_restore导入。该格式会创建一个文件夹,一个表对应一个文件。该格式默认启用压缩,并且支持并行导出; t:tar-输出tar压缩归档格式,适用于pg_restore导入。该格式将文件夹归档格式产生的文件夹压缩成tar压缩包。但该格式不支持压缩(文件夹归档已经压缩了),并且在导入时也不能更改相关的表顺序。 控制输出内容选项: -s, --schema-only 只转储模式, 不包括数据 -a, --data-only 只转储数据,不包括模式 -t, --table=TABLE 只转储指定名称的表 -T, --exclude-table=TABLE 不转储指定名称的表 -C, --create 在转储中包括创建数据库语句 -c, --clean:包含drop删除语句,建议与--if-exists同时使用; --if-exists,drop删除语句时带上IF EXISTS指令 -n, --schema=SCHEMA 只转储指定名称的模式 -N, --exclude-schema=SCHEMA 不转储已命名的模式 -O, --no-owner 在明文格式中, 忽略恢复对象所属者 -S, --superuser=NAME 在明文格式中使用指定的超级用户名 --column-inserts 以带有列名的INSERT命令形式转储数据 --inserts 以INSERT命令,而不是COPY命令的形式转储数据 --disable-triggers 在只恢复数据的过程中禁用触发器 --exclude-table-data=TABLE 不转储指定名称的表中的数据 --no-synchronized-snapshots 在并行工作集中不使用同步快照 --no-tablespaces 不转储表空间分配信息 --no-unlogged-table-data 不转储没有日志的表数据 --quote-all-identifiers 所有标识符加引号,即使不是关键字 --section=SECTION 备份命名的节 (数据前, 数据, 及 数据后) --serializable-deferrable 等到备份可以无异常运行 --snapshot=SNAPSHOT 为转储使用给定的快照 --strict-names 要求每个表和/或schema包括模式以匹配至少一个实体
常用示例:
#备份schema及数据,指定数据库pg_hive,指定文件为pg_hive20210108.sql pg_dump -h 127.0.0.1 -U postgres -d pg_hive -f /opt/pg_hive20210108.sql #只备份schema pg_dump -h 127.0.0.1 -U postgres -d pg_hive -s -f /opt/pg_hive20210108.sql #只备份数据 pg_dump -h 127.0.0.1 -U postgres -d pg_hive -a -f /opt/pg_hive20210108.sql #备份单个表 pg_dump -h 127.0.0.1 -U postgres -d pg_hive –t table1 -f /opt/pg_hive20210108.sql #备份多个表 pg_dump -h 127.0.0.1 -U postgres -d pg_hive –t table1 –t table2 -f /opt/pg_hive20210108.sql #以带有列名的INSERT命令形式转储数据 pg_dump -h 127.0.0.1 -U postgres -d pg_hive --column-inserts -f /opt/pg_hive20210108.sql #指定导出格式为自定义格式(二进制形式) pg_dump -h 127.0.0.1 -U postgres -d pg_hive -Fc -f /opt/pg_hive20210108.dump #使用gzip压缩转储(针对大型数据库) pg_dump -h 127.0.0.1 -U postgres -d pg_hive | gzip > /opt/pg_hive20210108_gz.sql.gz #使用split切片文件(针对大型数据库) /pg_dump -h 127.0.0.1 -U postgres -d pg_hive | split -b 100m - /opt/pg_hive20210108_sp.sql
2.pg_dumpall工具
相对于pg_dump只能备份单个库,pg_dumpall可以备份整个PostgreSql实例中所有的数据,包括角色和表空间定义。
使用示例:
#备份整个postgresql实例中所有的数 pg_dumpall -h 127.0.0.1 -U postgres -f /opt/pg_hive20210108_all.sql
二、逻辑备份还原
逻辑备份的还原命令为psql和pg_restore:
如果使用pg_dump未指定format(即未使用-F参数),则导出的是SQL脚本,导入时需用psql命令,否则用pg_restore还原。因这2个还原工具大部分参数与pg_dump含义相近,可使用命令后加–help查看详细参数。
常用示例:
#pg_dump备份时未指定format,还原时用psql psql -h 127.0.0.1 -U postgres -d pg_hive -f /opt/pg_hive20210108.sql #pg_dump备份时候使用-F参数指定format,还原时用pg_restore pg_restore -h 127.0.0.1 -U postgres -d pg_hive /opt/pg_hive20210108.dump #还原gzip压缩数据库备份 gunzip -c /opt/pg_hive20210108_gz.sql.gz | psql -h 127.0.0.1 -U postgres -d pg_hive #还原切片数据库备份 cat /opt/pg_hive20210108_sp.sql* | psql -h 127.0.0.1 -U postgres -d pg_hive
三、连续归档备份
连续归档是通过基础备份和wal日志相结合的方式进行备份,恢复的时候可以选择恢复到指定的时间点、指定事务点、或者完全恢复到wal日志的最新位置。
操作步骤如下:
1、创建备份目录
#创建基础备份目录 mkdir -p /data/pg_base #创建wal日志备份目录 mkdir -p /data/pg_archive
注意新建备份文件夹的权限及所有者,否则会备份失败
#更新备份文件夹的所有者 chown postgres:postgres /data/pg_base chown postgres:postgres /data/pg_archive
2、修改配置文件
打开postgresql.conf配置文件,修改以下3个参数:
vi postgresql.conf #wal_level中有三个主要的参数:minimal、archive和hot_standby。1.minimal是默认的值,它仅写入崩溃或者突发关机时所需要的信息(不建议使用)。2.archive是增加wal归档所需的日志(最常用)。3.hot_standby是在备用服务器上增加了运行只读查询所需的信息,一般实在流复制的时候使用到 wal_level = archive #开启归档模式 archive_mode = on #备份wal日志,每天生成一个日期命名的文件夹 archive_command = 'DIR=/data/pg_archive/`date +%F`; test ! -d $DIR && mkdir -p $DIR; test ! -f $DIR/%f && cp %p $DIR/%f'
3、重启pg数据库
命令为:pg_ctl restart
4、创建表
该步骤为测试备份及恢复效果使用
--创建表,插入10条测试数据: create table test (id integer); insert into test values(generate_series(1,10));
5、做基础备份
pg_basebackup -Ft -Pv -Xf -z -Z5 -D /data/pg_base/`date +%F`
为了测试备份和恢复效果,再插入10条数据,并进行手动切换wal日志,执行如下sql:
#插入数据 insert into test values(generate_series(1,10)); #切换wal日志 select pg_switch_wal();
四、连续归档恢复
1、创建data文件夹
#重命名原来的data文件夹 mv /pgsql/postgresql/data /pgsql/postgresql/data.bak #创建新的data文件夹 mkdir data
2、解压基础备份至新建的data文件夹
#拷贝基础备份到新建data文件夹 cp /data/pg_base/2021-01-15/base.tar.gz /pgsql/postgresql/data #解压文件 tar -zxvf base.tar.gz #删除基础备份中的wal日志和postmaster.pid文件 Cd /pgsql/postgresql/data rm -rf pg_wal rm -rf postmaster.pid #创建archive_status文件夹 mkdir -p pg_wal/archive_status
3、修改配置文件
vi postgresql.conf #修改restore_command为要恢复的wal日志目录 restore_command = 'cp /data/pg_archive/2021-01-15/%f %p'
4、新建recovery.signal文件
#恢复时依赖该文件,恢复至最新wal位置,文件无需添加内容 touch recovery.signal
5、赋权并启动数据库
#新建的data文件夹更改所有者 chown -R postgres:postgres /pgsql/postgresql/data #修改data目录权限,否则会因为目录权限过大无法启动数据库 chmod 0700 data -R #启动数据库 pg_ctl start
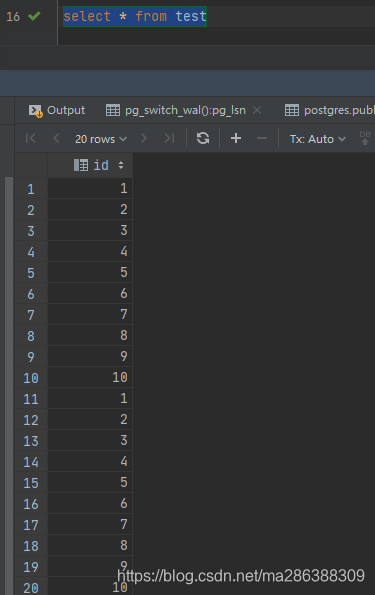
6、验证恢复效果
如下图,已通过基础备份和wal日志恢复全部数据。
总结
新创建文件夹时注意文件夹的归属及权限,否则会导致备份或恢复失败。
以上就是PostgreSQL数据库备份还原全攻略的详细内容,更多关于PostgreSQL备份还原的资料请关注脚本之家其它相关文章!
相关文章

Postgresql设置远程访问的方法(需要设置防火墙或者关闭防火墙)
这篇文章主要介绍了Postgresql设置远程访问的方法(需要设置防火墙或者关闭防火墙),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03 这篇文章主要介绍了PostgreSQL13基于流复制搭建后备服务器,后备服务器作为主服务器的数据备份,可以保障数据不丢,而且在主服务器发生故障后可以提升为主服务器继续提供服务。需要的朋友可以参考下2022-01-01
这篇文章主要介绍了PostgreSQL13基于流复制搭建后备服务器,后备服务器作为主服务器的数据备份,可以保障数据不丢,而且在主服务器发生故障后可以提升为主服务器继续提供服务。需要的朋友可以参考下2022-01-01 这篇文章主要介绍了PostgreSQL教程(十九):SQL语言函数,本文讲解了SQL语言函数基本概念、基本类型、复合类型、带输出参数的函数、返回结果作为表数据源等内容,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了PostgreSQL教程(十九):SQL语言函数,本文讲解了SQL语言函数基本概念、基本类型、复合类型、带输出参数的函数、返回结果作为表数据源等内容,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了PostgreSQL 性能优化之服务器参数配置操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01
这篇文章主要介绍了PostgreSQL 性能优化之服务器参数配置操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01 这篇文章主要为大家详细介绍了postgresql实现对已有数据表分区处理的操作的相关知识,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-12-12
这篇文章主要为大家详细介绍了postgresql实现对已有数据表分区处理的操作的相关知识,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-12-12 这篇文章主要介绍了postgresql中如何执行sql文件问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
这篇文章主要介绍了postgresql中如何执行sql文件问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-05-05
PostgreSQL连接数过多报错:too many clients already的解决
在使用 Navicat 连接 PostgreSQL 数据库时,突然遭遇到了一个报错:“FATAL: sorry, too many clients already”,这一错误提示表明数据库连接数已经达到上限,无法再创建新连接,所以本文给大家介绍了相关的解决办法,需要的朋友可以参考下2024-03-03 这篇文章主要介绍了PostgreSQL copy 命令教程详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01
这篇文章主要介绍了PostgreSQL copy 命令教程详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01 这篇文章主要介绍了PostgreSQL 实现给查询列表增加序号操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01
这篇文章主要介绍了PostgreSQL 实现给查询列表增加序号操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-01-01
PostgreSQL中offset...limit分页优化的一些常见手段
我们在使用数据库进行分页查询时,随着offset过滤的数据越来越多,查询也会越来越慢,下面这篇文章主要给大家介绍了关于PostgreSQL中offset...limit分页优化的一些常见手段,需要的朋友可以参考下2023-05-05










最新评论