
redis实现分布式全局唯一id的示例代码
一、前言
在很多项目中生成类似订单编号、用户编号等有唯一性数据时还用的UUID工具,或者自己根据时间戳+随机字符串等组合来生成,在并发小的时候很少出问题,当并发上来时就很可能出现重复编号的问题了,单体项目和分布式项目都是如此,要想解决这个问题也有很多种方法,可以自己写一个唯一ID生成规则,也可以通过数据库来实现全局ID生成这个和使用Redis实现其实类似,还可以使用比较成熟的雪花算法工具实现,每种方法都有各自的优缺点这里不展开说明,这里详细说明如何使用Redis实现生成分布式全局唯一ID。
还有一个问题为什么不能直接使用数据库的自增ID,而是需要单独生成一个分布式全局唯一ID,类似订单IDON202311090001,在数据库中有自增ID,对于当前业务来说就是唯一的为什么不能用,还要去生成一个独立的订单ID,对于这个问题要从几个方面分析:
1、数据库自增ID是有序增长的很容易就被人猜到,比如我现在下一单看到的订单ID为999那么就知道你的系统里最多只有999单,还有如果接口设计不合理,比如取消订单接口只校验了用户是否登录没有校验订单是否属于该用户,接收一个订单ID就能将订单取消,那么这样很容易就被人抓住漏洞,类似的情况有很多,也很多人写接口是不会注意这个问题。
2、这种自增ID没有意义,而且不同业务的自增ID是重合的,对于信息区分度很低,而且考虑到多业务交互和用户端展示也都是不合适的,想想看要是你在某宝下单,订单ID是999,或者在对接别人订单系统时,给你的订单ID是999是不是很奇怪。
3、分库分表时自增ID会重复
全局ID生成器:是一种在【分布式系统下】用来生成全局唯一ID的工具;
全局ID需要满足的特性:
1.唯一性
2.高可用:集群、哨兵机制;
3.高性能
4.递增性:Redis中的String数据类型的有自增特性!
5.安全性:将自增数值进行拼接,不容易猜出来;
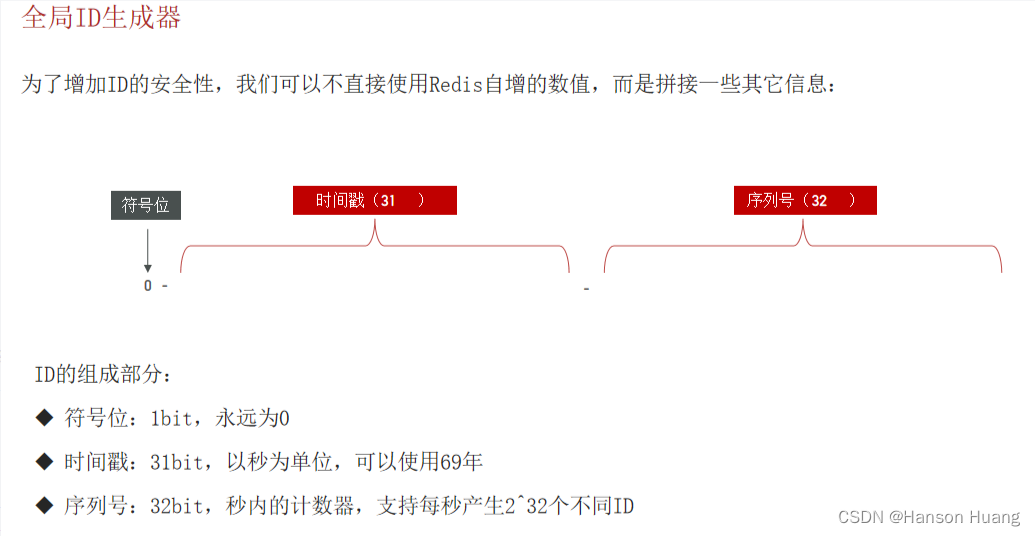
ID结构:符号位(1位) + 时间戳(31位) + 序列号(32位);
时间戳为从起始时间到现在的时间差;
理论上支持1秒钟2^32个订单;
二、如何通过Redis设计一个分布式全局唯一ID生成工具
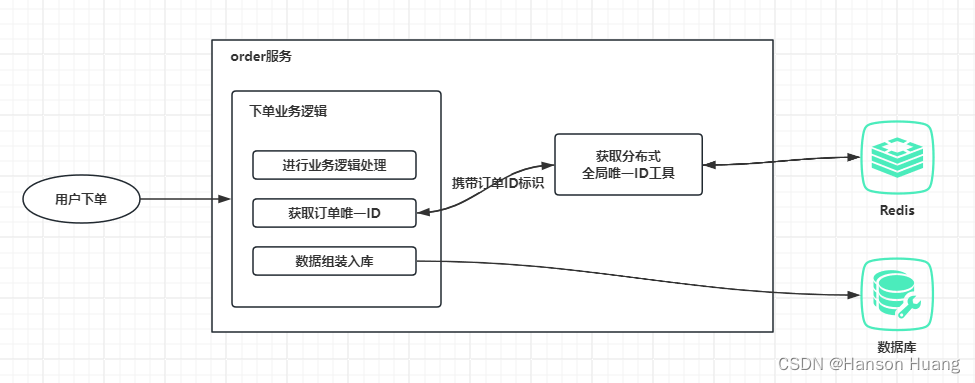
用户下单调用下单逻辑,先进行业务逻辑处理,然后携带订单ID标识通过分布式全局唯一ID工具获取一个唯一的订单ID,这个订单ID标识就是用于区分业务的,获取到订单ID后将数据组装入库,分布式全局唯一ID工具可以做成一个内嵌的utils,也可以封装成一个独立的jar,还可以做成一个分布式全局唯一ID生成服务供其它业务服务调用。
2.1 使用 Redis 计数器实现
Redis的String结构提供了计数器自增功能,类似Java中的原子类,还要优于Java的原子类,因为Redis是单线程执行的缓存读写本身就是线程安全的,也不用进行原子类的乐观锁操作,每一次获取分布式全局唯一ID时就将自增序列加1。
# 给key为GENERATEID:NO的value自增1,如果这key不存在则会添加到Redis中并且设置value为1 ## GENERATEID:key前缀 ## NO:订单ID标识 127.0.0.1:6379> incr GENERATEID:NO (integer) 1
2.2 使用 Redis Hash结构实现
Redis Hash结构中的每一个field也可以进行自增操作,可以用一个Hash结构存储所有的标识信息和自增序列,方便管理,比较适合并发不高的小项目所有服务都是用的一个Redis,如果并发较高就不合适了,毕竟Redis操作普通String结构肯定比操作Hash结构快。
# 给key为GENERATEID,field为no的value自增1,如果这key不存在则会添加到Redis中并且设置value为1 ## GENERATEID:分布式全局唯一ID Hash key ## NO:Hash结构中的field 127.0.0.1:6379> hincrby GENERATEID NO 1 (integer) 1
三、通过代码实现分布式全局唯一ID工具
这里使用Redis 计数器实现,自增序列以天为单位存储,在实际业务中,比如生成订单编号组成规则都类似NO1699631999000-1(业务标识key+当前时间戳+自增序列),这个规则可以自己定义,保证最终生成的订单编号不重复即可,不建议直接一个自增序列干到底,订单编号这类型的数据都是有长度限制的,或者是要求生成20字符的订单编号,如果增长的过长反而不好处理。
3.1 导入依赖配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
3.2 配置yml文件
spring:
#redis配置信息
redis:
## Redis数据库索引(默认为0)
database: 0
## Redis服务器地址
host: 127.0.0.1
## Redis服务器连接端口
port: 6379
## Redis服务器连接密码(默认为空)
password:
## 连接超时时间(毫秒)
timeout: 1200
lettuce:
pool:
## 连接池最大连接数(使用负值表示没有限制)
max-active: 8
## 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1
## 连接池中的最大空闲连接
max-idle: 8
## 连接池中的最小空闲连接
min-idle: 1
3.3 序列化配置
@Configuration
public class RedisConfig {
//编写我们自己的配置redisTemplate
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
// JSON序列化配置
Jackson2JsonRedisSerializer jsonRedisSerializer=new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper=new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jsonRedisSerializer.setObjectMapper(objectMapper);
// String的序列化
StringRedisSerializer stringRedisSerializer=new StringRedisSerializer();
//key和hash的key都采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
template.setHashKeySerializer(stringRedisSerializer);
//value和hash的value都采用jackson的序列化方式
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
3.4 编写获取工具
@Component
public class RedisGenerateIDUtils {
@Resource
private RedisTemplate<String, Object> redisTemplate;
// key前缀
private String PREFIX = "GENERATEID:";
/**
* 获取全局唯一ID
* @param key 业务标识key
*/
public String generateId(String key) {
// 获取对应业务自增序列
Long incr = getIncr(key);
// 组装最后的结果,这里可以根据需要自己定义,这里是按照业务标识key+当前时间戳+自增序列进行组装
String resultID = key + System.currentTimeMillis() + "-" + incr;
return resultID;
}
/**
* 获取对应业务自增序列
*/
private Long getIncr(String key) {
String cacheKey = getCacheKey(key);
Long increment = 0L;
// 判断Redis中是否存在这个自增序列,如果不存在添加一个序列并且设置一个过期时间
if (!redisTemplate.hasKey(cacheKey)) {
// 这里存在线程安全问题,需要加分布式锁,这里做简单实现
String lockKey = cacheKey + "_LOCK";
// 设置分布式锁
boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, 1, 30, TimeUnit.SECONDS);
if (!lock) {
// 如果没有拿到锁进行自旋
return getIncr(key);
}
increment = redisTemplate.opsForValue().increment(cacheKey);
// 我这里设置24小时,可以根据实际情况设置当前时间到当天结束时间的插值
redisTemplate.expire(cacheKey, 24, TimeUnit.HOURS);
// 释放锁
redisTemplate.delete(lockKey);
} else {
increment = redisTemplate.opsForValue().increment(cacheKey);
}
return increment;
}
/**
* 组装缓存key
*/
private String getCacheKey(String key) {
return PREFIX + key + ":" + getYYYYMMDD();
}
/**
* 获取当前YYYYMMDD格式年月日
*/
private String getYYYYMMDD() {
LocalDate currentDate = LocalDate.now();
int year = currentDate.getYear();
int month = currentDate.getMonthValue();
int day = currentDate.getDayOfMonth();
return "" + year + month + day;
}
}
3.5 测试获取工具
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedisUniqueIdDemoApplication.class)
class RedisUniqueIdDemoApplicationTests {
@Resource
private RedisGenerateIDUtils redisGenerateIDUtils;
@Test
public void test() throws InterruptedException {
// 定义一个线程池 设置核心线程数和最大线程数都为100,队列根据需要设置
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10000));
CountDownLatch countDownLatch = new CountDownLatch(10000);
long beginTime = System.currentTimeMillis();
// 获取10000个全局唯一ID 看看是否有重复
CopyOnWriteArraySet<String> ids = new CopyOnWriteArraySet<>();
for (int i = 0; i < 10000; i++) {
executor.execute(() -> {
// 获取全局唯一ID
long beginTime02 = System.currentTimeMillis();
String orderNo = redisGenerateIDUtils.generateId("NO");
System.out.println(orderNo);
System.out.println("获取单个ID耗时 time=" + (System.currentTimeMillis() - beginTime02));
if (ids.contains(orderNo)) {
System.out.println("重复ID=" + orderNo);
} else {
ids.add(orderNo);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
// 打印获取到的全局唯一ID集合数量
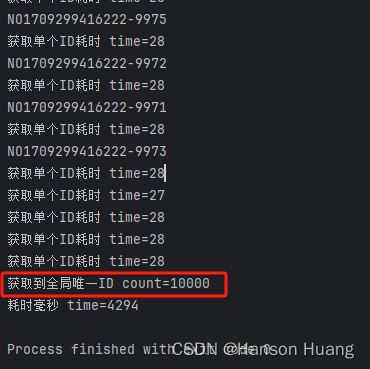
System.out.println("获取到全局唯一ID count=" + ids.size());
System.out.println("耗时毫秒 time=" + (System.currentTimeMillis() - beginTime));
}
}
知识小贴士:关于countdownlatch
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
countDown
await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
四、运行结果
redis结果
代码运行结果,id没有出现重复:
代码地址:Github
到此这篇关于redis实现分布式全局唯一id的示例代码的文章就介绍到这了,更多相关redis 分布式全局唯一id内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了redis哨兵模式说明与搭建详解,需要的朋友可以参考下2023-01-01
这篇文章主要介绍了redis哨兵模式说明与搭建详解,需要的朋友可以参考下2023-01-01 这篇文章主要介绍了使用 Redis 流实现消息队列,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了使用 Redis 流实现消息队列,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-11-11 这篇文章主要介绍了React 组件的常用生命周期函数汇总,组件的生命周期有助于理解组件的运行方式、完成更复杂的组件功能、分析组件错误原因等2022-08-08
这篇文章主要介绍了React 组件的常用生命周期函数汇总,组件的生命周期有助于理解组件的运行方式、完成更复杂的组件功能、分析组件错误原因等2022-08-08 本文主要介绍了Redis位图bitmap操作,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08
本文主要介绍了Redis位图bitmap操作,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-08-08 在springboot中引入spring-boot-starter-data-redis依赖时,默认使用的是lettuce,如果不想使用lettuce而是使用Jedis连接池,本文主要介绍了Redis缓存lettuce更换为Jedis的实现步骤,感兴趣的可以了解一下2024-08-08
在springboot中引入spring-boot-starter-data-redis依赖时,默认使用的是lettuce,如果不想使用lettuce而是使用Jedis连接池,本文主要介绍了Redis缓存lettuce更换为Jedis的实现步骤,感兴趣的可以了解一下2024-08-08 这篇文章主要介绍了Redis教程(七):Key操作命令详解,本文讲解了Key操作命令概述、相关命令列表、命令使用示例等内容,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Redis教程(七):Key操作命令详解,本文讲解了Key操作命令概述、相关命令列表、命令使用示例等内容,需要的朋友可以参考下2015-04-04 Redis作为常用开源的非关系型数据库,是开发中常用的数据库之一,很多朋友不清楚Windows下安装Redis的过程,今天小编通过分享本文给大家介绍详细过程,一起看看吧2021-08-08
Redis作为常用开源的非关系型数据库,是开发中常用的数据库之一,很多朋友不清楚Windows下安装Redis的过程,今天小编通过分享本文给大家介绍详细过程,一起看看吧2021-08-08 这篇文章主要介绍了Redis开启键空间通知实现超时通知的步骤,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了Redis开启键空间通知实现超时通知的步骤,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06 本文主要介绍了Redis实现事物以及锁的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-07-07
本文主要介绍了Redis实现事物以及锁的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-07-07 这篇文章主要介绍了redis启动失败问题之完美解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了redis启动失败问题之完美解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09










最新评论