
Redis key命令key的储存方式
Redis是目前使用比较广泛的nosql数据库,它也是一种基于key-value结构的数据库且支持多种数据类型,Redis中它的存储是使用一张hash表用于存储所有的key和对应value的地址。
因此key的命令是我们必须要掌握的。
前项
数据准备,首先我们先在redis中设置一些数据
arr1 = beijing arr2 = shanghai arr3 = shenzhen arr4 = guangzhou param1 = guangdong param2=hunan param3 = jiangxi param4 = hubei
Key命令使用
1. keys [pattern]
查看当前库的key(*代表通配符)。
该命令慎用,keys命令会扫描所有key,由于redis的执行是串行执行,当key过多时使用keys命令时会导致阻塞其他命令的执行,从而导致redis服务的崩溃。
大多数生产使用redis时会将keys命令禁用。
keys * 查看所有的key
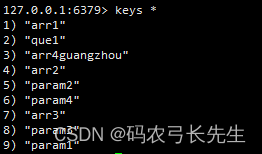
keys arr* 匹配以arr开头的key

keys *guangzhou 匹配以guangzhou结尾的key

keys param1 指定查看key为param1
![]()
2. exists [key . . .]
判断key是否存在,可以同时判断多个key
exists arr1 判断arr1 是否存在 返回1则存在 返回0则不存在
![]()
![]()
exists arr1 arr2 arr3 同时判断arr1 arr2 arr3 是否存在 匹配到n个key则返回n
如果都不存在则返回0
![]()

3. type key
查看key的类型,只能支持单个判断
![]()
4. del [key . . .]
删除指定的key 删除n个key 则返回n
unlink [key . . .]异步删除
![]()
5. exprie key [second]
设置key的过期时间
![]()
6. ttl key
查看key还剩多少时间过期,数字代表剩下多少秒, -2 代表已过期, -1 代表永不过期

7. dbsize
查看当前key的数量

Key的存储
redis中对key的存储使用的是一张全局的hashtable来存储,将每个key使用siphash函数生成一个64位的数字作为存储在hashtable里的索引。
当不同的键被落在同一个索引下时,使用链表结构来存储。
如下图:
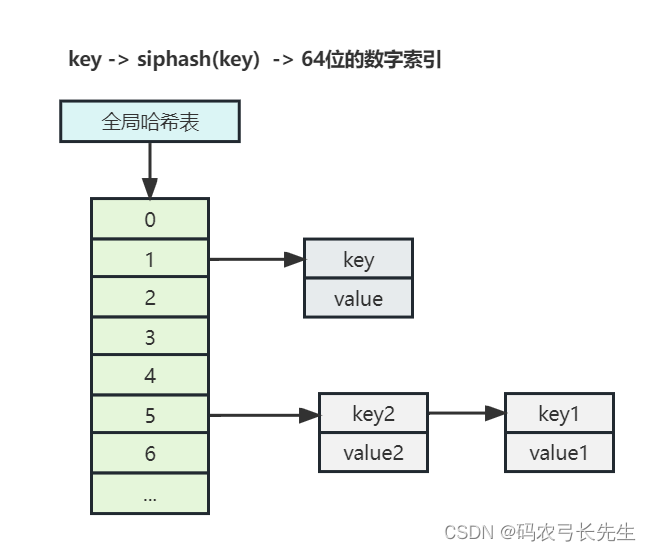
渐进式rehash
当相同的索引键链表节点数过大,超过整个hashtable的数量时,那么查找key的效率就会降低,因此redis则会对该全局hashtable进行rehash的操作。
如果 key的数量过大时直接进行rehash操作进行扩容时有可能会导致redis服务阻塞,因此redis则采用的是渐进式的rehash操作。
渐进式rehash的过程
redis在启动时内部默认会分配两个hashtable(ht0 、ht1),在正常使用时则使用其中一个ht0,当需要进行rehash操作时ht1才需要被使用到。
渐进式rehash的操作步骤:
1、首先将原ht1的空间扩容,让ht1同时有ht0 和 ht1两个哈希表的空间大小。
2、进行rehash操作时,在ht0中维护一个索引计数器 rehashidx , 并将它的值设置为 0 。
3、在rehash期间,当执行添加、删除、查找或者更新操作时,redis会将ht0 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht1,同时rehashidx 的值加1。
4、当rehash的次数不断增多时,ht0的所有键值对都会被 rehash 至 ht1,此时rehashidx 属性的值设为 -1 ,则代表rehash 操作已经全部完成,那么ht1和ht0的位置进行交换,前面提到的默认操作都是在ht0上的。
总之
rehash操作主要是解决由于hash冲突导致key链表过大影响性能,而使用渐进式rehash操作则是未来避免key数量过大因rehash导致redis服务的阻塞。
这些机制最终的目的都是为了能够提高redis服务的性能。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 布隆过滤器优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。本文将介绍布隆过滤器的原理以及Redis如何实现布隆过滤器,感兴趣的朋友跟随小编一起看看吧2019-12-12
布隆过滤器优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。本文将介绍布隆过滤器的原理以及Redis如何实现布隆过滤器,感兴趣的朋友跟随小编一起看看吧2019-12-12 在本篇文章里小编给大家分享了关于redis事务常用操作的相关知识点内容,有兴趣的朋友们可以跟着学习参考下。2019-07-07
在本篇文章里小编给大家分享了关于redis事务常用操作的相关知识点内容,有兴趣的朋友们可以跟着学习参考下。2019-07-07 这篇文章主要介绍了高并发场景分析之redis+lua防重校验,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了高并发场景分析之redis+lua防重校验,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-07-07 项目中有遇到这个问题,跟MySQL中的数据不一致,记录一下,本文主要介绍了Redis跟MySQL的双写问题解决方案,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-02-02
项目中有遇到这个问题,跟MySQL中的数据不一致,记录一下,本文主要介绍了Redis跟MySQL的双写问题解决方案,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-02-02 在Redis中,我们可以使用Hash数据结构来存储一组键值对,而有时候,我们可能需要设置这些键值对的过期时间,本文主要介绍了Redis设置Hash数据类型的过期时间,具有一定的参考价值,感兴趣的可以了解一下2024-01-01
在Redis中,我们可以使用Hash数据结构来存储一组键值对,而有时候,我们可能需要设置这些键值对的过期时间,本文主要介绍了Redis设置Hash数据类型的过期时间,具有一定的参考价值,感兴趣的可以了解一下2024-01-01 这篇文章主要介绍了Redis缓存淘汰策略和事务实现乐观锁详情,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-07-07
这篇文章主要介绍了Redis缓存淘汰策略和事务实现乐观锁详情,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-07-07 这篇文章主要介绍了排查Redis大key的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面跟着小编来一起学习学习吧2024-08-08
这篇文章主要介绍了排查Redis大key的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面跟着小编来一起学习学习吧2024-08-08 本文将演示主从复制如何配置、实现以及实现原理,Redis主从复制三大策略,全量复制、部分复制和立即复制。2021-05-05
本文将演示主从复制如何配置、实现以及实现原理,Redis主从复制三大策略,全量复制、部分复制和立即复制。2021-05-05 本文主要介绍了命令行清除Redis缓存的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-04-04
本文主要介绍了命令行清除Redis缓存的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-04-04 这篇文章主要介绍了Redis 的 GeoHash详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了Redis 的 GeoHash详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-11-11










最新评论