
springboot 整合mysql实现版本管理通用最新解决方案
一、前言
当springboot微服务项目完成从开发到测试全流程后,通常来说,最终交付产物是一个完整的安装包。在交付产物中一个重要文件就是sql脚本,即项目在部署完成之后运行需要的数据库表。简而言之就是:如何在完成项目安装后,减少或降低sql执行的效率?或者说:如何在项目实施时减少人工对sql相关的干预呢?结合实践经验,有下面几种思路提供参考:
1.1 单独执行初始化sql
sql脚本统一放在一个外部文件中,在项目安装部署之前先执行初始化sql,然后再安装项目。
1)好处:sql文件单独维护,与项目代码分开,可以避免文件管理上的麻烦;
2)缺点:实施时需要较多的人力干预,如果sql与工程代码是多人维护,升级中遇到问题,需要多方协调人力参与排查问题,而且这种方式难以做到自动化。
1.2 程序自动执行
顾名思义,这种方式依托程序自动完成sql的执行,即项目安装之前通过程序就可以完成所需sql表的初始化,相比上面单独执行sql的方式来说,尽量减少了人工的干预,即人力成本的浪费。
二、数据库版本升级管理问题
在正式开始讨论如何使用程序自动管理sql之前,先来聊聊为什么会涉及数据库版本的管理问题,来看下面这张图,
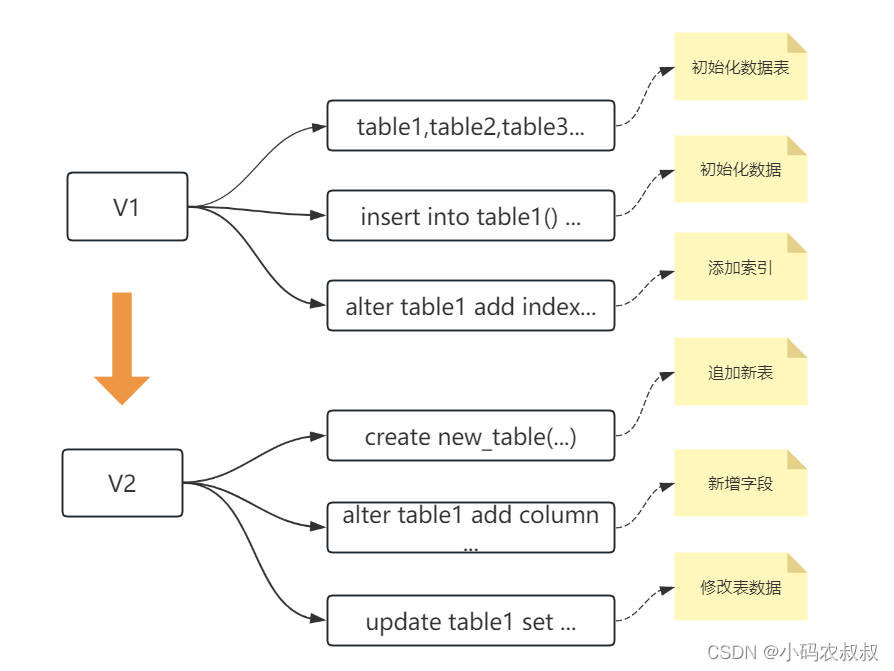
从这张图可还原下相对真实的开发场景:
- V1版本,初始化数据表,给部分表创建索引,同时初始化部分数据;
- V1版本的业务开发完成并上线;
- V2版本新的需求来了,需要继续追加新表,之前的某个表需要补充字段,同时某个表需要批量修改数据以适配新的业务;
- V3...
三、spring 框架sql自动管理机制
spring框架可以说早已成为很多微服务项目的标配,所以很多外部组件都提供了与spring框架整合的SDK或独立jar包,这里提供两种常用的外部jar,可以比较容易实现sql脚本的自动化执行,分别是jdbc-template与spring自带的配置方式,下面分别进行说明;
3.1 jdbcTemplate 方式
下面演示使用jdbcTemplate完成一个sql脚本自动执行的过程。
3.1.1 创建数据库
创建一个数据库,名为:bank(可自定);
create database bank;

3.1.2 创建 springboot 工程
创建一个spring boot工程,目录结构如下:
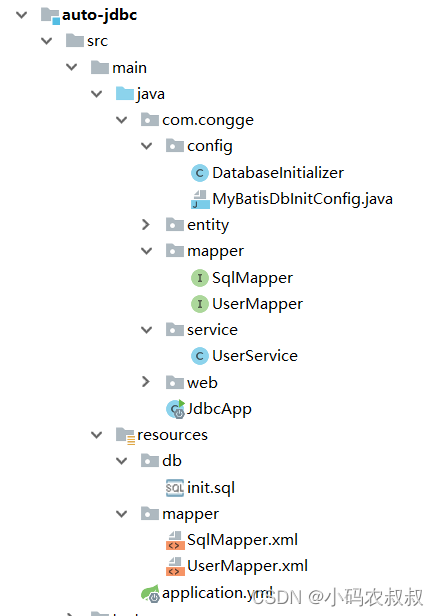
3.1.3 初始化sql脚本
在resource目录下,创建一个db的文件夹,里面有一个init.sql文件,初始化sql脚本如下:
-- 初始化建表sql use bank; -- tb_user表建表 CREATE TABLE `tb_user` ( `id` int(12) NOT NULL, `user_name` varchar(32) DEFAULT NULL, `password` varchar(64) DEFAULT NULL, `phone` varchar(32) DEFAULT NULL, `address` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- tb_role表建表 CREATE TABLE `tb_role` ( `id` int(12) NOT NULL, `role_name` varchar(32) DEFAULT NULL, `role_type` varchar(64) DEFAULT NULL, `code` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- tb_role 表增加索引 alter tb_role add index idx_code(code);
3.1.4 核心配置类
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.Resource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.DatabasePopulator;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
/**
* 成功执行
*/
@Component
@Slf4j
public class DatabaseInitializer implements InitializingBean {
@Value("classpath:db/init.sql")
private Resource dataScript;
@Bean
public DataSourceInitializer dataSourceInitializer(final DataSource dataSource) {
final DataSourceInitializer initializer = new DataSourceInitializer();
// 设置数据源
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(databasePopulator());
return initializer;
}
private DatabasePopulator databasePopulator() {
final ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScripts(dataScript);
log.info("sql脚本初始化完成");
return populator;
}
@Override
public void afterPropertiesSet() throws Exception {
}
}3.1.5 执行sql初始化
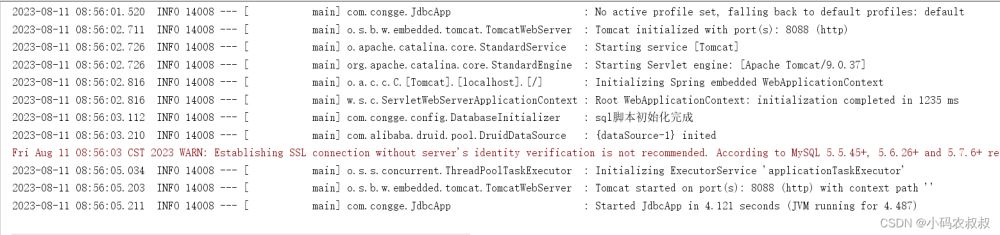
全部的配置到这里就完成了,启动工程即可执行,由于这种方式是实现了InitializingBean,即在容器完成bean的初始化过程中执行,所以伴随容器的启动即可完成sql的自动执行,执行之后可看到如下效果;
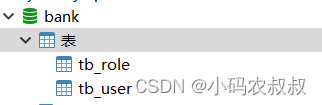
启动完成后,数据表也创建出来了
3.2 配置文件方式
也可以直接通过配置文件的方式,按照约定配置好相关的属性之后即可完成sql脚本的自动初始化,参考配置如下,相关的配置说明见备注;
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://IP:3306/bank?createDatabaseIfNotExist=true&useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8
driver-class-name: com.mysql.jdbc.Driver
username: root
password: root
#初始化sql建表相关配置属性 ========================
schema: classpath:db/init.sql #初始化sql语句,DDL相关
data: classpath:db/data.sql # 追加数据,添加字段,索引等
separator: ";" # sql语句中的结束分隔符,通常为;
continue-on-error: false #执行错误时是否继续
initialization-mode: always #是否每次启动工程时都执行
platform: mysql #使用哪种数据库
sqlScriptEncoding: utf-8 #编码缺点:上述这种方式有一个明显的缺点就是第一次初始化之后,再次启动时如果配置initialization-mode仍然开启的话将会报错,只能手动修改配置。
四、Flyway 实现数据库版本自动管理
4.1 Flyway 简介
Flyway是一个款数据库版本管理工具,程序通过集成Flyway可实现启动项目时自动执行项目中数据库迭代升级所需Sql语句,从而减少sql升级时人工介入与干预。
Flyway是独立于数据库的应用、管理并跟踪数据库变更的数据库版本管理工具。通俗来讲,Flyway就像Git管理代码那样,管理不同版数据库本sql脚本,从而做到数据库同步升级。
4.2 Flyway 执行流程与原理
Flyway 是如何实现自动管理不同版本的sql文件呢?下面给出其执行过程;
- 按照Flyway 的配置要求,完成相关的配置信息;
- 运行项目,会在默认的数据库下(没有指定的话就用在项目的数据库)下创建Flyway自带的数据表,用于存储Flyway运行中的数据,比如记录了本次升级的版本号,时间等;
- 对工程文件目录进行扫描,主要是需要初始化加载或运行的sql文件路径,然后Flyway执行数据迁移时将基于sql脚本版本号进行排序,按顺序执行,这个由Flyway内部的机制保障;
- 初次执行完sql脚本之后,将会在Flyway运行时数据表中记录关键的信息,比如本次升级的版本号,下次项目继续启动时将会对比sql文件以确定是否需要再次执行sql升级;
4.3 Flyway sql脚本命名规范
下图是一张权威的关于使用Flyway命名sql脚本的规范说明。

关于这张图,做如下的说明:
Prefix (前缀)
V为版本迁移,U为回滚迁移,R为可重复迁移。在日常开发中,我们使用V前缀,表示版本迁移。绝大多数情况下,我们只会使用V前缀。
Version (版本号)
每一个迁移脚本,都需要一个对应一个唯一的版本号。而脚本的执行顺序,按照版本号的顺序。一般情况下,每次发生了sql脚本的变更,我们使用数字自增即可。
Separator (分隔符)
两个
_,即__,约定的一种配置,建议按这种规范执行。
Description (描述)
在下面的示例中,我们使用 init,或update,一般见名知义即可。
Suffix (后缀)
.sql ,可配置,不过一般可以不用配置,默认即为.sql。
4.3.1 sql命名参考示例
sql命名规范非常重要,涉及到开发中可能会踩坑的问题,为了更好的加深对此问题的理解,我们以几个命名文件为例加以说明;
有如下几个sql文件
V20230810__init.sql
V20230810__data.sql
V20230810.01_init.sql
V20230810.02_data.sql
V:大写
固定大写(必须大写,小写不执行),约定规范;
20230810.01
20230810是日期,后面用.01代表序号,如果前面日期相同,但是后面的序号不一样,.02比.01版本高,.03比.02版本高,Flyway 在执行sql脚本时是严格按照版本号的顺序进行;
执行顺序
Flyway 比较两个 SQL 文件的先后顺序时采用 采用左对齐原则, 缺位用 0 代替 。
举几个例子一看便知:
- 1.0.1.1 比 1.0.1 版本高;
- 1.0.10 比 1.0.9.4 版本高;
- 1.0.10 和 1.0.010 版本号一样,每个版本号部分的前导 0 会被忽略;
如下是下文两个需要执行的sql
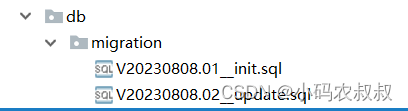
4.3.2 sql命名规范补充说明
需重复运行的SQL,则以大写的“R”开头,后面再以两个下划线分割,接着跟文件名称,最后以.sql结尾,比如,R20230809.03index.sql;
当与V开头的sql文件在一起执行时,V开头的SQL执行优先级要比R开头的SQL优先级高

4.4 SpringBoot集成Flyway
下面介绍如何与springboot进行整合使用,实现程序的自动版本管理,需求如下:
1、V1版本,初始化建表;
2、V2版本,给表初始化一些数据,补充索引、字段等;
3、V3版本,依次类推..
4.4.1 引入基础依赖
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-core</artifactId>
<version>6.0.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.3.2.RELEASE</version>
</dependency>4.4.2 配置Flyway参数
在application.yml中添加如下配置,可视情况补充
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://IP:3306/bank
driver-class-name: com.mysql.jdbc.Driver
username: root
password: root
flyway:
enabled: true
encoding: UTF-8
cleanDisabled: true
## 迁移sql脚本文件存放路径,默认db/migration
locations: classpath:db/migration
## 迁移sql脚本文件名称的前缀,默认V
sqlMigrationPrefix: V
## 迁移sql脚本文件名称的分隔符,默认2个下划线__
sqlMigrationSeparator: __
# 迁移sql脚本文件名称的后缀
sqlMigrationSuffixes: .sql
validateOnMigrate: true
# 设置为true,当迁移发现数据库非空且存在没有元数据的表时,自动执行基准迁移,新建schema_version表
baselineOnMigrate: true更多的配置参数,可以进入到FlywayProperties这个类中详细查看,上述配置中可结合备注进行了解,其中核心的配置包括:
- locations,即升级sql的文件位置;
- sqlMigrationSuffixes,执行sql文件的后缀名;
- 数据库连接信息必不可少,因为Flyway升级过程中需要初始化自己的表;
4.4.3 准备升级sql脚本
在resource的目录下,创建db文件目录,在这个文件目录下创建升级相关的sql文件,如下,
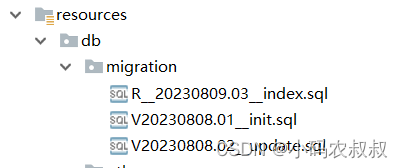
V20230808.01__init.sql 文件中存放的是初始化安装相关的建表sql,内容如下:
-- 初始化建表sql use bank; -- tb_user表建表 CREATE TABLE `tb_user` ( `id` int(12) NOT NULL, `user_name` varchar(32) DEFAULT NULL, `password` varchar(64) DEFAULT NULL, `phone` varchar(32) DEFAULT NULL, `address` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- tb_role表建表 CREATE TABLE `tb_role` ( `id` int(12) NOT NULL, `role_name` varchar(32) DEFAULT NULL, `role_type` varchar(64) DEFAULT NULL, `code` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
V20230808.02__update.sql 文件中存放的是追加索引,追加字段相关,内容如下:
-- 初始化建表sql use bank; -- 给tb_user表添加一个索引 alter table tb_user add index idx_name(user_name); -- 给tb_user表追加新字段 alter table tb_user add column woker varchar(32) default null;
4.4.4 测试效果一:执行sql初始化建表
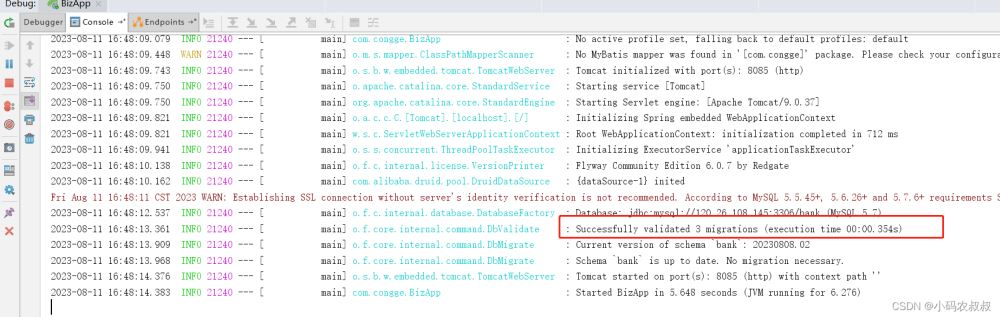
直接启动工程即可自动执行,为了看到效果,可以先将V20230808.02__update.sql内容注释掉,第一次执行完成后,再执行;
第一次执行后,从日志不难看出,对应的sql脚本被执行了,尽管另一个被注释了,仍然输出了,这也就是说,只要放到被扫描的目录下就能被Flyway检测到;
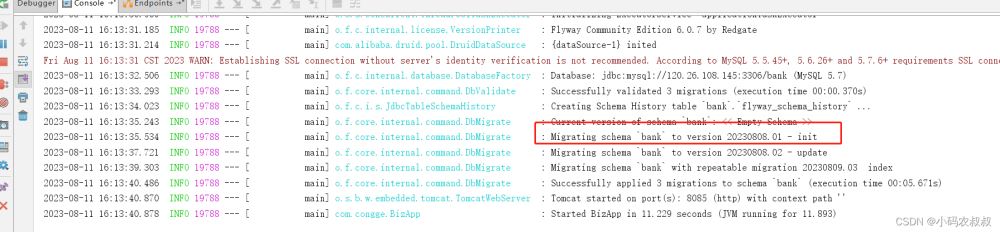
启动完成后,检查数据库看到相关的表也被创建出来了

在上文中谈到Flyway是通过flyway_schema_history这个表来管理数据库版本升级的,打开这张表,可以看到记录了详细而完整的与升级sql文件相关的信息;

4.4.5 测试效果二:执行sql创建索引
放开V20230808.02__update.sql内容注释,再次启动工程执行,遗憾的是,此时启动报错了,这个错误大概是说,检测到数据库中flyway_schema_history这张表的checksum的数据与当前准备执行的sql文件版本冲突了,直接抛出错。
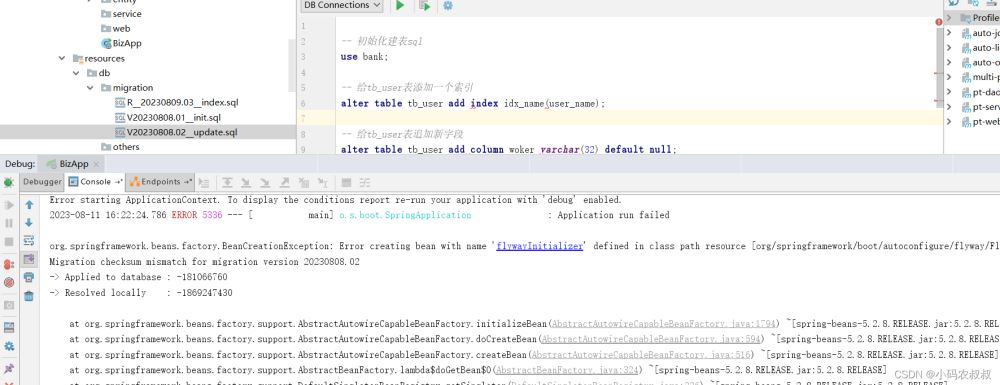
这也就是说其实上面的这种操作方式是有问题的,因为一开始就把V20230808.02__update.sql这个文件放在这个目录下面了,尽管里面没有要执行的sql,但是Flyway仍然会在表中创建一个checksum的数据记录这个文件的元信息,所以再次执行的时候,我们再将注释放开的时候执行会报错,解决的办法是:
初始化sql使用V1版本;再次发生sql变更的时候新建一个V2的文件,记录变更的sql内容,放在扫描的目录下即可;
按照这个思路,再次走一遍这个流程之后,去数据库中确认下索引是否成功创建
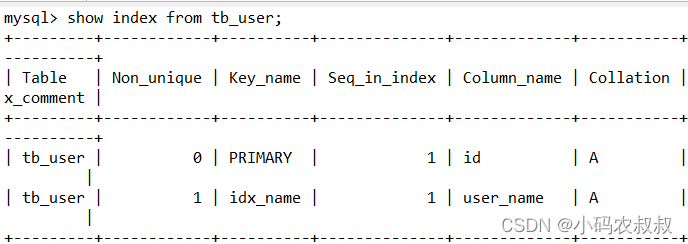
再检查字段是否追加成功

在没有对上述两个sql文件做任何修改的情况下再次执行,可以看到再次启动工程时就不会报错了
4.5 使用经验与问题总结
这里结合实际使用经验,将实际开发中遇到的问题做一个总结,避免后续踩坑;
- V开头的sql脚本,执行后不可修改,修改会导致启动项目时Flyway检测不通过,导致项目启动失败,一旦有sql变更,建议增加版本号使用新的sql文件;
- 开发或测试阶段需修改已执行脚本,可通过删除相关flyway_schema_history表元数据后,重启项目;
- 脚本命名不规范,导致脚本未被执行,比如未使用V开头命名文件,可参阅官网或资料认真了解命名规范;
- 脚本文件名版本和描述之间没有使用双下滑线‘__’分割导致执行失败;
- 新增脚本,版本号没有大于已有版本号,导致执行失败;
- 各sql语句要以分号‘;’结尾,忘记用分号会导致sql执行失败,语法格式牢记于心;
- sql语句不满足可重复执行,新环境执行sql导致失败;
五、Liquibase 实现数据库版本自动管理
与Flyway相同的是,通过项目集成,都可以完成对sql脚本的自动化管理,但是Liquibase提供了更丰富的操作管理,配置管理,以及插件化管理。
5.1 Liquibase简介
Liquibase是一个数据库变更的版本控制工具。项目中通过Liquibase解析用户编写的Liquibase的配置文件,生成sql语句,并执行和记录(执行是根据记录确定sql语句是否曾经执行过,和配置文件里的预判断语句确定sql是否执行)。官网地址:liquibase官网地址,Liquibase开发文档:liquibase文档
5.2 Liquibase 优势
下面总结了Liquibase的在做sql版本变更时的优势:
- 可以用上下文控制sql在何时何地如何执行;
- 根据配置文件自动生成sql语句用于预览;
- 配置文件支持SQL、XML、JSON 或者 YAML;
- 可重复执行迁移,可回滚,且支持插件化配置拓展;
- 兼容14中主流数据库如oracle,mysql,pg等,支持平滑迁移;
- 版本控制按序执行,支持schmea的变更;
- 与springboot整合简单,上手简单;
- 支持schema方式的多租户(multi-tenant);
5.3 SpringBoot集成Liquibase
使用SpringBoot与Liquibase进行整合的方式有很多,网上的参考资料也比较丰富,下面演示一种最简单的方式,方便开发中直接拿来使用。
5.3.1 导入依赖
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
<version>3.6.3</version>
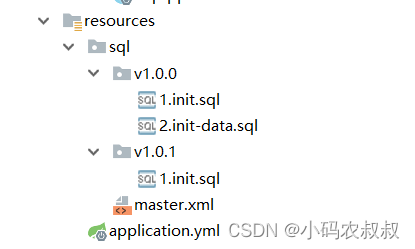
</dependency>5.3.2 新建master.xml
使用该文件,用于指定数据库初始化脚本的位置,整个配置文件以及sql脚本目录结构如下
master.xml配置如下,不难看出,在xml文件中使用了changeSet 这个标签,里面配置了sql脚本相关的信息;
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.1.xsd">
<changeSet id="v1.0.0-1" author="zcy" context="main">
<sqlFile path="classpath:/sql/v1.0.0/1.init.sql"/>
<sqlFile path="classpath:/sql/v1.0.0/2.init-data.sql"/>
</changeSet>
</databaseChangeLog>5.3.3 创建sql文件
sql文件中包括一个初始化表相关,另一个为创建索引和追加字段,与上文相同不再单独列举
5.3.4 自定义Liquibase配置类
自定义配置类,通过该类在spring容器完成初始化时自动执行对sql的管理,这个与上文jdbcTemplate是不是很相似,原理差不多;
import liquibase.integration.spring.SpringLiquibase;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.DefaultResourceLoader;
import javax.annotation.Resource;
import javax.sql.DataSource;
@Slf4j
@Configuration
public class LiquibaseConfig {
//指定liquibase版本
@Value("${dc.version:main}")
private String contexts;
//是否开启liquibase
@Value("${dc.liquibase.enable:true}")
private Boolean enable;
//liquibase用到的两张表,记录与管理升级sql相关
private static final String DATABASE_CHANGE_LOG_TABLE = "lqb_changelog_demo";
private static final String DATABASE_CHANGE_LOG_LOCK_TABLE = "lqb_lock_demo";
@Resource
private DataSource dataSource;
/**
* liquibase bean配置声明
*/
@Bean
public SpringLiquibase liquibase() {
SpringLiquibase liquibase = new SpringLiquibase();
// Liquibase xml 文件路径
liquibase.setChangeLog("classpath:sql/master.xml");
liquibase.setDataSource(dataSource);
if (StringUtils.isNotBlank(contexts)) {
liquibase.setContexts(contexts);
}
liquibase.setShouldRun(enable);
liquibase.setResourceLoader(new DefaultResourceLoader());
// 覆盖Liquibase changelog表名
liquibase.setDatabaseChangeLogTable(DATABASE_CHANGE_LOG_TABLE);
liquibase.setDatabaseChangeLogLockTable(DATABASE_CHANGE_LOG_LOCK_TABLE);
return liquibase;
}
}5.3.5 效果测试一
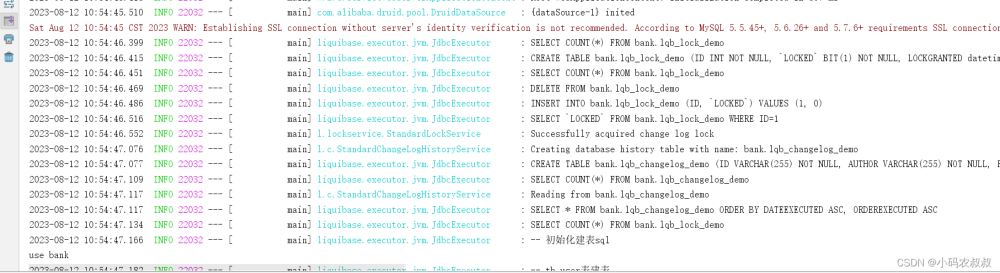
到这里主要的配置就完成了,清空bank数据库,然后启动工程;
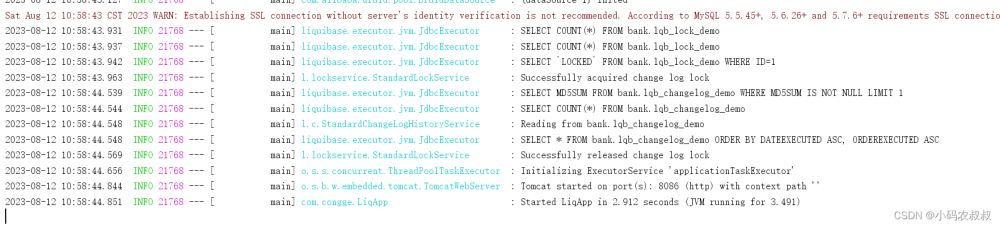
从控制台输出的日志可以看到使用Liquibase建表的详细过程

启动完成后,检查数据库,可以看到表成功创建出来,同时用于管理版本相关的两张表也一起创建出来了;
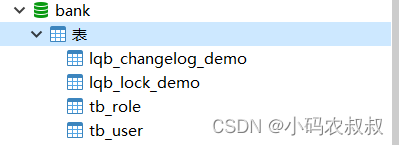

如果重新启动工程,不会报错,也不会再次重新创建,说明可以自动进行sql数据库的版本管理了
5.3.6 效果测试二
再在xml中追加新的sql文件,即v1.0.1的目录和相关的sql脚本
1.init.sql内容如下
-- 初始化建表sql use bank; -- tb_depart表建表 CREATE TABLE `tb_depart` ( `id` int(12) NOT NULL, `dept_name` varchar(32) DEFAULT NULL, `dept_type` varchar(64) DEFAULT NULL, `code` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
重启工程之后,控制台再次输出了sql中创建表的信息
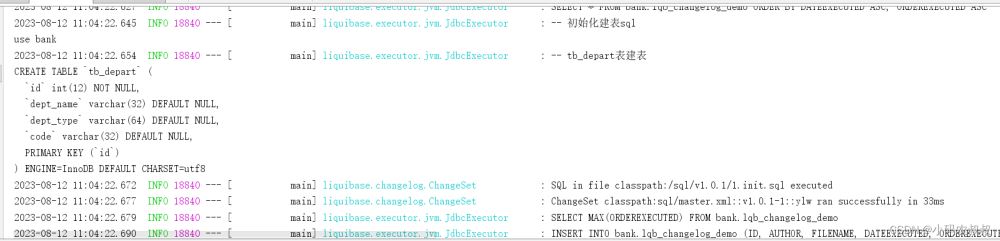
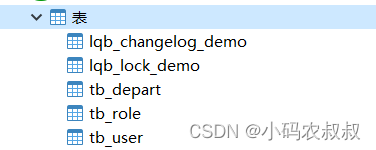
检查数据库,sql中的表也被创建出来了
关于使用Liquibase进行版本管理和命名规范的问题,限于篇幅原因就不再详细展开了,有兴趣的同学可参考相关资料和官方文档,网上的资料很丰富。
5.4 Flyway与Liquibase的对比
从使用上来说,Flyway与Liquibase都能与项目快速实现整合实现对数据库版本的管理,成本较小,但是两款数据库迁移工具其实定位上是差别的,经验来说如果项目规模较小,整体变动不大的话可以考虑用 Flyway ,而大应用和企业应用用 Liquibase 更合适。
不过从入门到使用,Liquibase 并未看到比 Flyway 带来多大优势,反倒 Flyway 基于“约定大于配置”的思想,在使用上更加便捷,也更容易实现标准化。
六、自研数据库版本管理SDK工具
如果觉得引入外部或第三方组件仍觉得麻烦,可以考虑自己开发一个SDK用来做数据库版本管理,
比如像SAAS这样的平台应用,可能存在非常多的微服务模块,如果每个应用都引第三方组件,一方面技术栈难以统一,另一方面不同的应用开发人员存在不同的学习成本,相反,如果自研一套SDK工具,只需要发布一下SDK,其他应用按照SDK的规范统一接入使用即可。
6.1 实现思路
自研SDK其实也没有想象中那么难,一方面可以借鉴上述几种外部组件的实现思路,另一方面也是最核心的就是要制定标准规范,即sql文件的内容必须按照一定的规范编写,否则解析的时候会出现各种问题,总结来说如下:
- 统一技术栈,建议SDK中尽可能少的依赖第三方包;
- 商讨并制定sql文件的格式规范,下文会给出一个模板规范;
- SDK对外暴露的信息尽可能少,方便其他应用引用,减少对接和学习成本;
如下是接下来示例中即将要做的一个sql文件的内容
--version 1.0.0,build 2023-08-11 ,新建用户表 CREATE TABLE `tb_user` ( `id` int(12) NOT NULL, `user_name` varchar(32) DEFAULT NULL, `password` varchar(64) DEFAULT NULL, `phone` varchar(32) DEFAULT NULL, `address` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
不难看出,在该文件中,以 --version 开头的内容就是规范的核心内容,即:
version
表示每次升级涉及到的sql的版本号,至于是1.0.0或1.0等,可以根据团队习惯来定,需要注意的是,每次发生了sql版本的变更,程序在启动之后会执行sql的变更
build
即本次升级sql的时间,也可以理解为一个标识位,即发生sql变更的时间,方便后续出现问题时进行sql的回滚或问题追溯
至于其他的信息,比如后面的备注,或者可以根据自身的需求再补充其他的内容,因为这些信息将会作为一个记录变更sql信息的表进行数据存储,说到这里,相信有经验的同学应该知道大致的实现思路了,下面用一张图来说明该方案的实现过程,这也是程序中实现的思路;
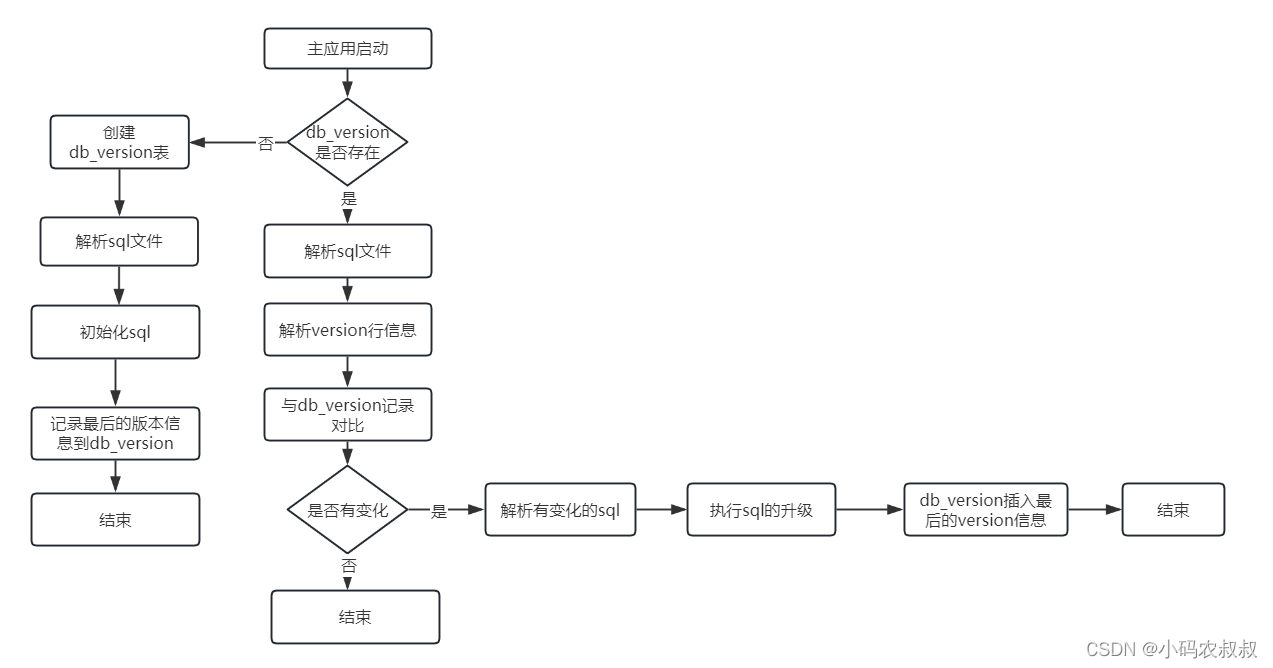
6.2 核心代码
结合上面的实现业务流程,下面给出核心的实现逻辑,最终可以将该核心实现做成一个SDK,外部服务可以直接应用,通过调用核心的入口方法,传入相关的基础参数即可,同时为了最小化依赖,这里操作数据库使用的是jdbc的方式;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.sql.*;
import java.util.LinkedList;
import java.util.List;
import java.util.regex.Pattern;
/**
* 操作sysversion表相关
*/
public class SysVersionUtils {
public static void main(String[] args){
boolean sysVersionTableExist = SysVersionConfig.isSysVersionTableExist();
if(!sysVersionTableExist){
//如果没有创建表,执行表的创建
SysVersionConfig.checkAndCreateSysVersion();
}
//到这一步,说明已经创建完成了,接下来开始解析sql文件进行脚本的初始化
String sqlFilePath= "classpath:sql/table_init.sql";
parseAndStoreVersionInfo(sqlFilePath);
}
public static void parseAndStoreVersionInfo(String sqlFilePat) {
File databaseFile = null;
try {
databaseFile = ResourceUtils.getFile(sqlFilePat);
} catch (FileNotFoundException e) {
System.out.println("获取或解析sql文件失败");
e.printStackTrace();
return;
}
List<String> readLines = null;
try {
readLines = FileUtils.readLines(databaseFile, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
System.out.println("解析sql文件失败");
return;
}
if (CollectionUtils.isEmpty(readLines)) {
return;
}
//如果解析数据时发现不合理的数据行,是直接抛出异常不再执行?还是忽略?可以自行扩展,这里暂时跳过,记录日志
List<String> versionInfoList = new LinkedList<>();
for (String readLine : readLines) {
if (!isValidVersionTagLine(readLine)) {
continue;
}
versionInfoList.add(readLine);
}
//检查数据库中sys_version数据是否存在
Connection connection = JdbcUtils.getConnection();
VersionRecord dbVersionRecord = getDbVersionRecord(connection);
if (dbVersionRecord == null) {
System.out.println("初次执行sql变更");
String upgradeSql = getSqlTextFromLines(readLines);
System.out.println("to execute sql : " + upgradeSql);
//解析得到最后一行的version数据
String lastVersionLine = ((LinkedList<String>) versionInfoList).getLast();
TemLineRecord temLineRecord = ParseUtils.getFromLine(lastVersionLine);
System.out.println("本次变更的sql版本号信息" + temLineRecord.getVersionNum() + ":" + temLineRecord.getBuildDate());
//TODO 执行sql建表相关的创建
initSysVersion(connection,"app",temLineRecord.getVersionNum(),temLineRecord.getBuildDate());
//执行sql升级
doUpgradeSql(connection,upgradeSql);
System.out.println("完成sql的初始化执行");
return;
}
/**
* FIXME 1、如果sys_version已经有数据了,说明之前做过升级了,只需要解析最新的版本变更;
* FIXME 2、可以重复执行,如果没有版本变更,直接忽略,不用解析
*/
//拿到最后一行的version信息,下面使用
String lastVersionLine = ((LinkedList<String>) versionInfoList).getLast();
TemLineRecord lineRecord = ParseUtils.getFromLine(lastVersionLine);
if(lineRecord.getBuildDate().equals(dbVersionRecord.getBuildDate()) &&
lineRecord.getVersionNum().equals(dbVersionRecord.getVersionNum())){
System.out.println("已经是最新版本号,无需升级");
return;
}
//从哪一行开始的数据才是本次需要执行的sql呢?那就是:数据库中的两个字段和 --version 以及时间正好能够对的上的那一行开始
getTargetSqlLines(readLines, versionInfoList, dbVersionRecord);
String sqlText = getSqlTextFromLines(readLines);
System.out.println("待执行的sql :" + sqlText);
//执行本次sql的更新
doUpgradeSql(connection,sqlText);
//升级版本号
updateSysVersion(lineRecord,dbVersionRecord.getId());
}
private static void getTargetSqlLines(List<String> readLines, List<String> versionInfoList, VersionRecord dbVersionRecord) {
String targetLine = null;
int lineNum = 0;
for (int i = 0; i < versionInfoList.size() - 1; i++) {
if (versionInfoList.get(i).contains(dbVersionRecord.getVersionNum()) && versionInfoList.get(i).contains(dbVersionRecord.getBuildDate())) {
lineNum = i;
break;
}
}
targetLine = versionInfoList.get(lineNum + 1);
int targetNum = 0;
for (int i = 0; i < readLines.size(); i++) {
if (readLines.get(i).equalsIgnoreCase(targetLine)) {
//找到这一行的行号
targetNum = i;
break;
}
}
//接下来移除targetNum之前的所有元素
readLines.subList(0, targetNum+1).clear();
}
/**
* 将读取到的数据行组装成sql
* @param allLines
* @return
*/
public static String getSqlTextFromLines(List<String> allLines){
if(CollectionUtils.isEmpty(allLines)){
System.out.println("数据行为空");
return null;
}
StringBuilder stringBuilder = new StringBuilder();
for(String text : allLines){
if(text.startsWith("--")){
continue;
}else if(StringUtils.isEmpty(text)){
continue;
}
stringBuilder.append(text);
stringBuilder.append("\n");
}
return stringBuilder.toString();
}
/**
* 更新版本号
* @param lineRecord
* @param id
*/
public static void updateSysVersion(TemLineRecord lineRecord,String id){
Connection connection = JdbcUtils.getConnection();
PreparedStatement ps=null;
String sql="UPDATE sys_version SET BUILD_DATE=?, VERSION_NUM= ? WHERE id=?";
try {
ps=connection.prepareStatement(sql);
ps.setString(1, lineRecord.getBuildDate());
ps.setString(2, lineRecord.getVersionNum());
ps.setString(3, id);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
connection.close();
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 初次新增版本号
* @param connection
* @param id
* @param versionNum
* @param dateStr
*/
public static void initSysVersion(Connection connection,String id,String versionNum,String dateStr){
PreparedStatement ps=null;
String sql = "insert into sys_version values('" +id+"','"+versionNum+"','"+dateStr+"')";
try {
ps = connection.prepareStatement(sql);
ps.execute(sql);
System.out.println("初始化插入sys_version版本号成功");
} catch (SQLException e) {
e.printStackTrace();
System.out.println("初始化插入sys_version版本号失败");
}
}
/**
* 执行升级sql
* @param connection
* @param sql
* @throws SQLException
*/
private static void doUpgradeSql(Connection connection, String sql) {
if(StringUtils.isEmpty(sql)){
System.out.println("带升级的sql不存在");
return;
}
Statement statement = null;
try {
statement = connection.createStatement();
String[] sqlCommands = sql.split(";");
for (String sqlCommand : sqlCommands) {
if (!sqlCommand.trim().isEmpty()) {
try {
statement.executeUpdate(sqlCommand);
} catch (SQLException e) {
e.printStackTrace();
System.out.println("执行升级sql失败");
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取数据库的最新版本号
* @param connection
* @return
*/
public static VersionRecord getDbVersionRecord(Connection connection) {
String sql = "select * from sys_version";
PreparedStatement ps = null;
ResultSet rs = null;
VersionRecord versionRecord = null;
try {
ps = connection.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
versionRecord = new VersionRecord();
versionRecord.setId(rs.getString("id"));
versionRecord.setBuildDate(rs.getString("BUILD_DATE"));
versionRecord.setVersionNum(rs.getString("VERSION_NUM"));
}
} catch (SQLException e) {
e.printStackTrace();
System.out.println("获取最新版本号失败");
}
return versionRecord;
}
private static Pattern oldVersionTagPattern = Pattern.compile("^--version\\s[0-9\\.]+,build\\s.*");
public static boolean isValidVersionTagLine(String tagLine) {
return oldVersionTagPattern.matcher(tagLine).matches();
}
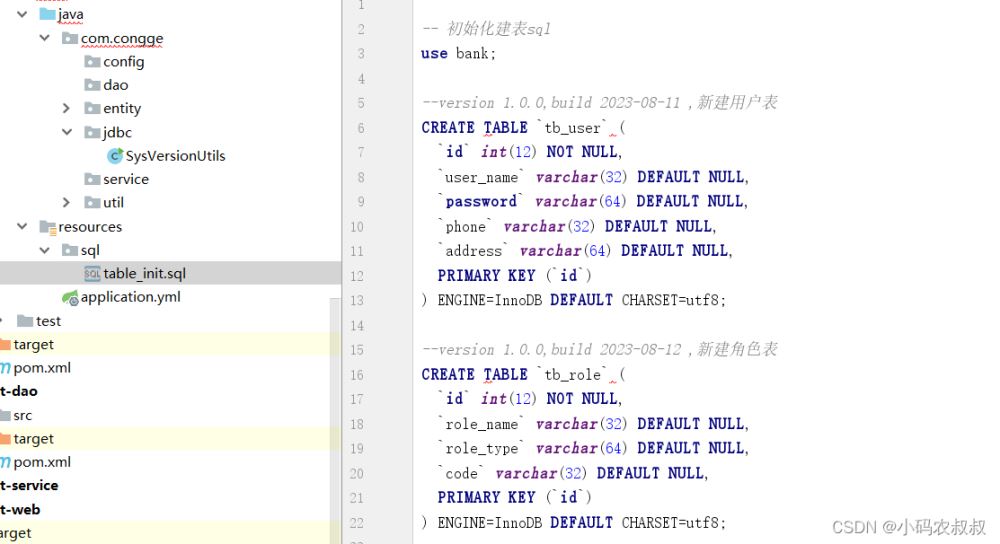
}关于此处的代码,如果拿来生产实现,还有一些细节点值得推敲和完善,比如日志的输出,参数的健壮性处理上,毕竟是SDK,需要考虑的更加细致一点。接下来测试下效果吧,在resources目录下有如下待执行的sql文件;
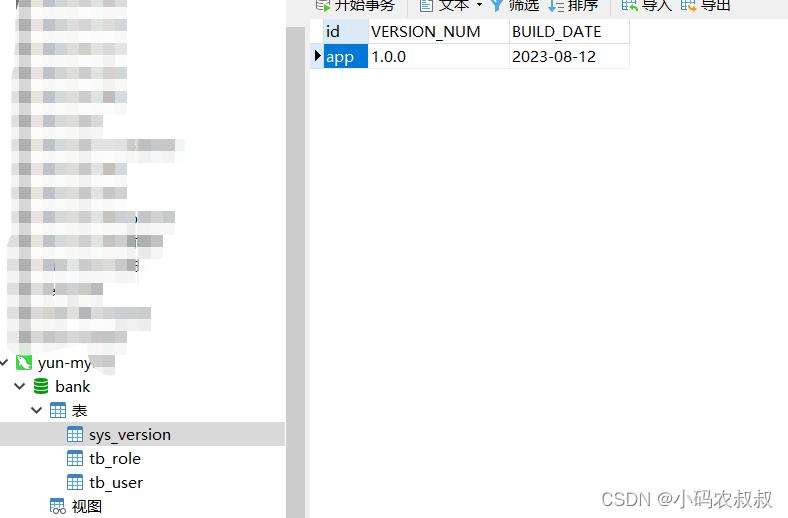
第一次执行时version表不存在,结合控制台日志,可以看到表创建成功

第二次执行,在sql中追加如下内容
--version 1.0.0,build 2023-08-13 ,创建索引alter table tb_user add index idx_name(user_name);
然后再次执行
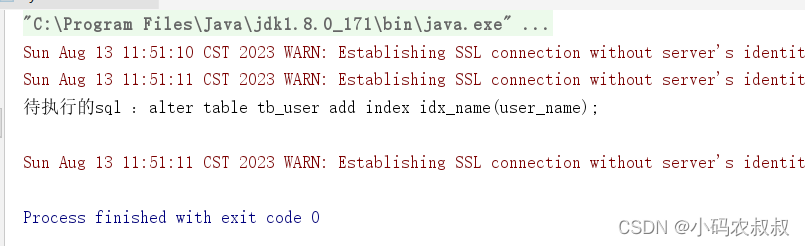
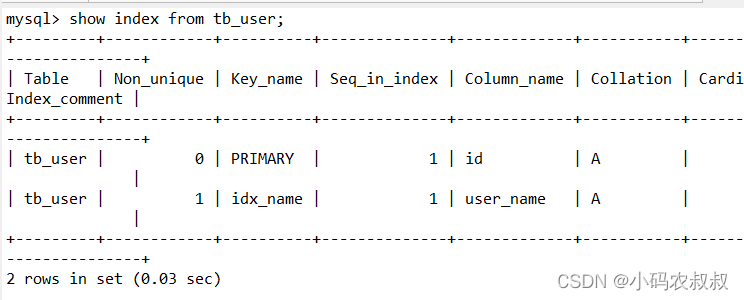
执行完成后,在数据库确认下索引是否创建成功
七、写在文末
本篇通过较大的篇幅详细总结了几种常用的实现数据库版本自动管理的方式,每一种都有合适的应用场景,希望对看到的小伙伴们有用,本篇到此结束,感谢观看!
到此这篇关于springboot 整合mysql实现版本管理通用解决方案的文章就介绍到这了,更多相关springboot 整合mysql内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了使用JVM常用GC日志打印参数,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09
这篇文章主要介绍了使用JVM常用GC日志打印参数,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-09-09 这篇文章主要介绍了java 数据结构之堆排序(HeapSort)详解及实例的相关资料,需要的朋友可以参考下2017-03-03
这篇文章主要介绍了java 数据结构之堆排序(HeapSort)详解及实例的相关资料,需要的朋友可以参考下2017-03-03 这篇文章主要介绍了简单了解JAVA中类、实例与Class对象,类是面向对象编程语言的一个重要概念,它是对一项事物的抽象概括,可以包含该事物的一些属性定义,以及操作属性的方法,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了简单了解JAVA中类、实例与Class对象,类是面向对象编程语言的一个重要概念,它是对一项事物的抽象概括,可以包含该事物的一些属性定义,以及操作属性的方法,需要的朋友可以参考下2019-06-06
Java中List.contains(Object object)方法使用
本文主要介绍了Java中List.contains(Object object)方法,使用List.contains(Object object)方法判断ArrayList是否包含一个元素对象,感兴趣的可以了解一下2022-04-04 下面小编就为大家带来一篇List转换成Map工具类的简单实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-01-01
下面小编就为大家带来一篇List转换成Map工具类的简单实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-01-01 这篇文章主要介绍了java获取百度网盘真实下载链接的方法,涉及java针对URL操作及页面分析的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了java获取百度网盘真实下载链接的方法,涉及java针对URL操作及页面分析的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-07-07 这篇文章主要给大家介绍了关于Java网络编程教程之设置请求超时的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2017-12-12
这篇文章主要给大家介绍了关于Java网络编程教程之设置请求超时的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2017-12-12 这篇文章主要介绍了Java集合之HashMap用法,结合实例形式分析了java map集合中HashMap定义、遍历等相关操作技巧,需要的朋友可以参考下2017-05-05
这篇文章主要介绍了Java集合之HashMap用法,结合实例形式分析了java map集合中HashMap定义、遍历等相关操作技巧,需要的朋友可以参考下2017-05-05 这篇文章主要介绍了Java数组队列概念与用法,结合实例形式分析了Java数组队列相关概念、原理、用法及操作注意事项,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了Java数组队列概念与用法,结合实例形式分析了Java数组队列相关概念、原理、用法及操作注意事项,需要的朋友可以参考下2020-03-03 这篇文章主要介绍了Spring Boot 2.X 快速集成单元测试解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了Spring Boot 2.X 快速集成单元测试解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08










最新评论