
Java中的LinkedList集合详解
一、介绍
LinkedList 是一个双向链表结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环),在任意位置插入删除都很方便,但是不支持随机取值,每次都只能从一端开始遍历,直到找到查询的对象,然后返回;不过,它不像 ArrayList 那样需要进行内存拷贝,因此相对来说效率较高,但是因为存在额外的前驱和后继节点指针,因此占用的内存比 ArrayList 多一些。
LinkedList 采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, Eelement)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入
二、源码分析
1、LinkedList实现的接口
如下图:
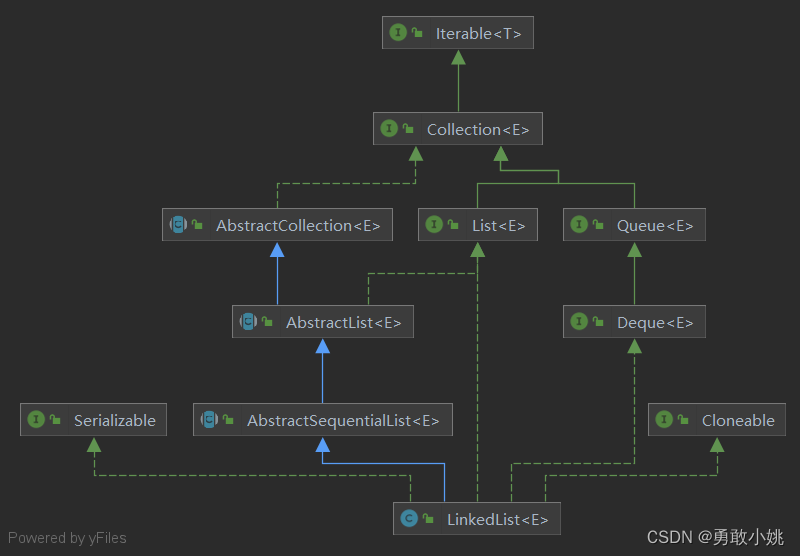
观察上图:
AbstractSequentialList抽象类:继承自 AbstractList,是 LinkedList 的父类,是 List 接口 的简化版实现,具有双端队列的功能
- List接口:列表,add、set、等一些对列表进行操作的方法
- Deque接口:实现了双端队列接口Deque,因此具有双端队列的功能
- Serializable接口:主要用于序列化,即:能够将对象写入磁盘。与之对应的还有反序列化操作,就是将对象从磁盘中读取出来。因此如果要进行序列化和反序列化,ArrayList的实例对象就必须实现这个接口,否则在实例化的时候程序会报错(java.io.NotSerializableException)。
- Cloneable接口:实现Cloneable接口的类能够调用clone方法,如果没有实现Cloneable接口就调用方法,就会抛出异常(java.lang.CloneNotSupportedException)。
2、LinkedList中的变量
- transient int size = 0:双向链表节点数量size。默认初始化值为0,包访问权限。
- transient Node<E> first:双向链表的头节点。包访问权限。
- transient Node<E> last:双向链表的尾节点。包访问权限。
3、LinkedList的构造方法
(1)无参构造方法
public LinkedList() {
}总结:无参构造方法,此时双向链表的节点数量size为0,双向链表的头尾节点为null。
(2)带集合参数的构造方法
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}总结:先将集合转换为数组,然后将数组中的元素按照索引顺序一个个从双向链表的尾部插入到空的双向链表中。
4、LinkedList中的重要方法
(1)静态内部类Node
private static class Node<E> {
//元素
E item;
//后驱指针
Node<E> next;
//前驱指针
Node<E> prev;
//构造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}(2)add()方法
public boolean add(E e) {
//将元素添加到链表的尾部
linkLast(e);
return true;
} void linkLast(E e) {
final Node<E> l = last;
//创建新节点
final Node<E> newNode = new Node<>(l, e, null);
//把之前的尾指针节点指向新节点
last = newNode;
//如果尾节点为空,则代表是新链表,直接赋值给头指针;如果不为空,则把尾指针指向新节点
if (l == null)
first = newNode;
else
l.next = newNode;
//长度++
size++;
//代表对集合的操作次数
modCount++;
}通过上述分析,可以看到:add()方法调用了linkLast()方法,将新节点插入到链表的尾部。在linkLast()方法里对尾指针last进行了判断,如果尾节点为空,说明是第一次插入元素,则直接将新节点赋值给头指针;如果尾节点不为空,则将节点的尾指针指向新节点即可,然后再将size和modCount自增1。modCount不是LinkedList里的变量,而是来自于AbstractList。
接下来看一下如何在指定位置添加元素:
public void add(int index, E element) {
//检查索引位置
checkPositionIndex(index);
//如果和当前长度size相等,则直接添加元素到末尾,否则就将元素插入到指定的位置
if (index == size)
linkLast(element);
else
linkBefore(element, node(index)); //node用来获取给定index处的元素节点
}
//索引校验
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
//linkLast()前面已经介绍,这里只展示linkBefore()
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}由上述分析可以看到:在指定位置添加元素的时候,首先调用checkPositionIndex()方法判断下标是否越界,然后判断index是否等于 size,如果相等则添加到末尾,否则将该元素插入的 index 的位置。linkBefore()方法负责把元素 e 插入到 succ 之前。
node(index)方法是获取 index 位置的节点,它将index与当前链表的一半进行比较,如果比一半小则从头遍历,如果比一半大则向后遍历。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}在前面介绍LinkedList的有参构造时,我们可以看到其调用了addAll()方法,那么接下来看看这个方法又是如何实现的?
//调用addAll(index, c)
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
//检查index是否越界
checkPositionIndex(index);
//将集合转为数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
//遍历数组,将数组中的元素创建为节点,并按照顺序连接起来
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
//修改当前节点个数size的值
//操作次数modCount+1
size += numNew;
modCount++;
return true;
}(3)remove()方法
如果是删除指定位置的元素,则先检查下标是否越界,然后再调用unlink()方法释放节点,移除掉指定的元素。
//移除指定位置的元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果移除的是头节点,则头节点后移
if (prev == null) {
first = next;
} else {
prev.next = next; //否则就释放节点的迁移借宿
x.prev = null;
}
//如果溢出的是尾节点,则尾节点前移
if (next == null) {
last = prev;
} else {
next.prev = prev; //否则就释放节点的后一个元素
x.next = null;
}
//节点数据置为空
x.item = null;
size--;
modCount++;
return element;
}remove(Object o)从该列表中删除第一个出现的指定元素(如果存在)。如果此列表不包含该元素,则它将保持不变。
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}除了上述的移除元素方法,还有一些其他的方法,如:removeFirst()、removeLast()、poll()等,这里不再赘述。
(4)set()方法
set()方法通过修改下标获取到下标节点,获取出旧值返回,把新值赋值元素
public E set(int index, E element) {
//检查索引是否越界
checkElementIndex(index);
//获取到要修改的元素的下标
Node<E> x = node(index);
//获取旧值
E oldVal = x.item;
//修改
x.item = element;
return oldVal;
}(5)get()方法
get()方法根据下标获取元素遍历找到当前元素并返回,遍历利用的是判断当前获取元素位于链表的前半段还是后半段,前半段则从头遍历到当前位置返回,后半段则从尾遍历到当前位置返回
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}除此之外,还有getFirst()、element()、peek()、peekFirst() 这四个获取头结点方法,区别在于对链表为空时的处理,是抛出异常还是返回null,其中getFirst() 和element() 方法将会在链表为空时,抛出异常;因为内部都保存了头节点所以直接获取头节点就可以。getLast() 方法在链表为空时,会抛出NoSuchElementException,而peekLast() 则不会,只是会返回 null;内部保存了尾节点直接返回即可。
三、总结
1、LinkedList总结
- linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构。
- LinkedList能存储null值。
- LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好。
- 从源码中看,它不存在容量不足的情况。
- LinkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值。
- LinkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口。
2、双向链表与双向循环链表
双向链表就是一个元素有3个属性,一个向前的指针,一个向后的指针,一个当前节点值;双向就是本节点既有向后的指向,也有向前的
双向循环链表的差别在于循环,双向链表首位不相连,指针都指向空,双向循环链表是首位相连形成环状
3、JDK1.7为什么把双向循环链表改为双向链表
- 双向循环链表是通过new一个headerEntry管理首尾相连得,可以少创建对象
- 写操作主要分为2种,一种头尾插入,一种中间插入;双向链表的有点在于头尾插入的时候只需要维护一个指针,中间插入2个没什么区别,但实际使用中头尾插入是最频繁的
4、ArrayList 与LinkedList比较
- ArrayList是基于数组实现的,LinkedList是基于双链表实现的。另外LinkedList类不仅是List接口的实现类,可以根据索引来随机访问集合中的元素,除此之外,LinkedList还实现了Deque接口,Deque接口是Queue接口的子接口,它代表一个双向队列,因此LinkedList可以作为双向队列 ,栈(可以参见Deque提供的接口方法)和List集合使用,功能强大。
- ArrayList是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的,可以直接返回数组中index位置的元素,因此在随机访问集合元素上有较好的性能。Array获取数据的时间复杂度是O(1),但是要插入、删除数据却是开销很大的,因为这需要移动数组中插入位置之后的的所有元素。LinkedList的随机访问集合元素时性能较差,因为需要在双向列表中找到要index的位置,再返回;但在插入,删除操作是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList在插入数据时还需要更新索引(除了插入数组的尾部)。
- LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。也就是说,ArrayList在查找方面速度快。LinkedList在增删速度快。
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
- 如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
到此这篇关于Java中的LinkedList集合详解的文章就介绍到这了,更多相关LinkedList集合详解内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Java基于jdbc实现的增删改查操作,结合实例形式分析了java使用jdbc进行数据库的连接、增删改查等基本操作技巧,需要的朋友可以参考下2019-01-01
这篇文章主要介绍了Java基于jdbc实现的增删改查操作,结合实例形式分析了java使用jdbc进行数据库的连接、增删改查等基本操作技巧,需要的朋友可以参考下2019-01-01 这篇文章主要介绍了Java简单工厂模式定义与用法,结合实例形式分析了java简单工厂模式的相关定义与使用技巧,并给出了原理类图进行总结,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了Java简单工厂模式定义与用法,结合实例形式分析了java简单工厂模式的相关定义与使用技巧,并给出了原理类图进行总结,需要的朋友可以参考下2019-07-07 这篇文章主要为大家详细介绍了java实现微信点餐申请微信退款,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09
这篇文章主要为大家详细介绍了java实现微信点餐申请微信退款,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09 本篇文章主要介绍了SpringMVC实现自定义类型转换器 ,详细的介绍了自定义类型转换器的用法和好处,有兴趣的可以了解一下。2017-04-04
本篇文章主要介绍了SpringMVC实现自定义类型转换器 ,详细的介绍了自定义类型转换器的用法和好处,有兴趣的可以了解一下。2017-04-04
解决SpringMVC Controller 接收页面传递的中文参数出现乱码的问题
下面小编就为大家分享一篇解决SpringMVC Controller 接收页面传递的中文参数出现乱码的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-03-03![使用@Service注解出现No bean named 'xxxx' available]错误的解决](//img.jbzj.com/images/xgimg/bcimg5.png)
使用@Service注解出现No bean named 'xxxx'&
这篇文章主要介绍了使用@Service注解出现No bean named 'xxxx' available]错误的解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
spring NamedContextFactory在Fegin配置及使用详解
在我们日常项目中,使用FeignClient实现各系统接口调用变得更加简单, 在各个系统集成过程中,难免会遇到某些系统的Client需要特殊的配置、返回读取等需求。Feign使用NamedContextFactory来为每个Client模块构造单独的上下文(ApplicationContext)2023-11-11 这篇文章主要介绍了Spring Bean的生命周期的相关资料,需要的朋友可以参考下2016-09-09
这篇文章主要介绍了Spring Bean的生命周期的相关资料,需要的朋友可以参考下2016-09-09 数据时代的到来,多线程一直都是比较关心的问题之一,这篇文章介绍了JAVA实现多线程的三种方法,有需要的朋友可以参考一下2015-08-08
数据时代的到来,多线程一直都是比较关心的问题之一,这篇文章介绍了JAVA实现多线程的三种方法,有需要的朋友可以参考一下2015-08-08 这篇文章主要介绍了SpringMVC实现Validation校验过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了SpringMVC实现Validation校验过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11





![使用@Service注解出现No bean named 'xxxx' available]错误的解决](http://img.jbzj.com/images/xgimg/bcimg5.png)




最新评论