
深入理解C++11:探索lambda函数的奥秘
一、C++98中的排序
在 C++98 中,如果要对一个数据集合中的元素进行排序,可以使用 std::sort 方法,下面代码是对一个整型集合进行排序。
#include <algorithm>
#include <functional>
#include <iostream>
using namespace std;
int main()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
cout << "原始数组:";
for (auto e : array)
{
cout << e << ' ';
}
cout << endl << endl << "排升序:";
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
for (auto e : array)
{
cout << e << ' ';
}
cout << endl << endl << "排降序:";
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
for (auto e : array)
{
cout << e << ' ';
}
return 0;
}
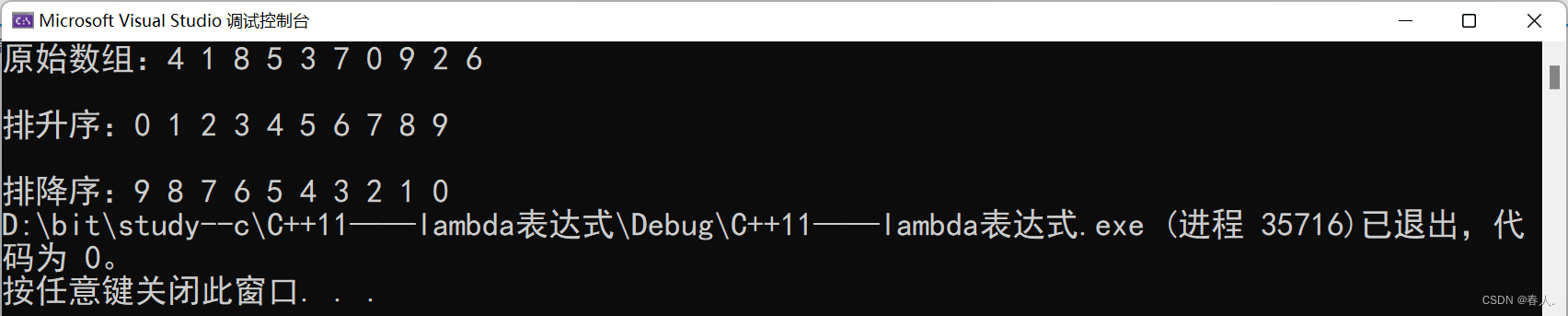
小Tips:上面的 greater 是一个仿函数,这里传递仿函数是用来控制大小比较的。关于仿函数,在前面的文章中已经多次使用,在【C++杂货铺】优先级队列的使用指南与模拟实现一文中,我们使用仿函数来进行大小比较;在【C++杂货铺】一文带你走进哈希:哈希冲突 | 哈希函数 | 闭散列 | 开散列一文中,我们使用仿函数来获取 pair<K, V> 模型中的 key。总之,仿函数有着十分强大的功能。
如果待排序的元素为自定义类型,由于自定义类型中可能有多重不同的属性,因此需要用户自己来定义排序时的比较规则:
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
ostream& operator<<(ostream& out, Goods& goods)
{
out << goods._name << '-' << goods._price << '-' << goods._evaluate;
return out;
}
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
struct CompareevaluateLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._evaluate < gr._evaluate;
}
};
struct CompareevaluateGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._evaluate > gr._evaluate;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
cout << "排序前:";
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照价格排升序:";
sort(v.begin(), v.end(), ComparePriceLess());
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照价格排降序:";
sort(v.begin(), v.end(), ComparePriceGreater());
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照评价排升序:";
sort(v.begin(), v.end(), CompareevaluateLess());
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照评价排降序:";
sort(v.begin(), v.end(), CompareevaluateGreater());
for (auto e : v)
{
cout << e << ' ';
}
cout << endl;
}
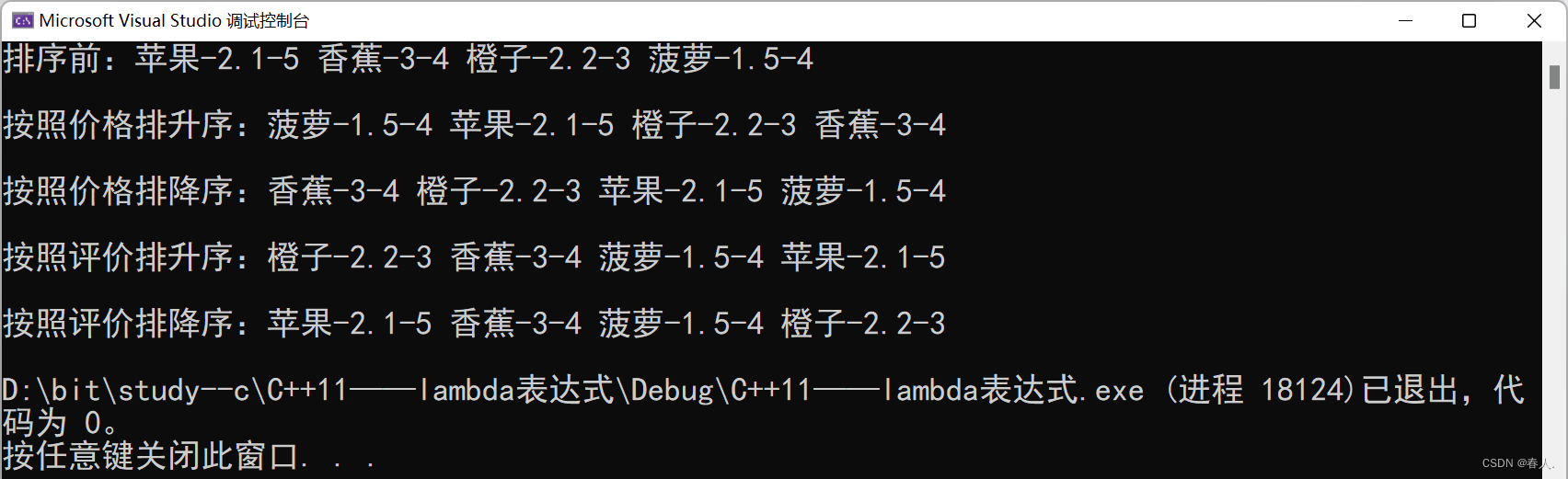
小Tips:上面代码中如果要使用库里面的仿函数 less 或 greater,需要对 >、< 进行运算符重载,实现 Goods 类的大小比较。但是上面的代码中并没有采取这种做法,而是直接自己写了两个仿函数进行大小关系的比较。前面那种提供运算符重载的方法比较局限,因为无论是 < 还是 > 都只能重载一份,即 operator< 和 operator> 各自只能在代码中出现一份,且它们的内部只能根据一种属性进行大小比较,在同一段代码中不能实现根据不同属性去排序。而自己写仿函数就不会出现这种情况,我们可以在同一段代码中根据不同的属性去写不同的仿函数(只要类名不同即可)。
随着 C++ 语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个排序算法,都要重新去写一个类(仿函数,实现大小比较),如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在 C++11 语法中出现了 Lambda 表达式。
二、先来看看 lambda 表达式长什么样
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
cout << "排序前:";
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照价格排升序:";
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._price < g2._price; });
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照价格排降序:";
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._price > g2._price; });
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照评价排升序:";
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._evaluate < g2._evaluate; });
for (auto e : v)
{
cout << e << ' ';
}
cout << endl << endl << "按照评价排降序:";
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool {return g1._evaluate > g2._evaluate; });
for (auto e : v)
{
cout << e << ' ';
}
cout << endl;
}

小Tips:上述代码就是使用 C++11 中的 lambda 表达式来解决,可以看出 lambda 表达式实际是一个匿名函数对象。
三、lambda表达式语法
lambda 表达式书写格式为:[capture-list](parameters) mutable-> return-type {statement}。
[capture-list]:捕捉列表。该列表总是出现在 lambda 函数的开始位置,编译器根据 [ ] 来判断后面的代码是否是 lambda 函数,捕捉列表能够捕捉上下文中的变量供 lambda 函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同 () 一起省略。
mutable:默认情况下,lambda 函数总是一个 const 函数,mutable 可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可以省略。返回值类型明确的情况下,也可以省略,由编译器对返回值类型进行推断。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕捉到的变量。
小Tips:在 lambda 函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此 C++11 中最简单的 lambda 函数为:[]{};。该 lambda 函数不能做任何事情。
实例:
int AddFunc(int x, int y)
{
return x + y;
}
int num1 = 10, num2 = 20;
int main()
{
// 实现两个数相加的 lambda 函数
int a = 1, b = 10;
auto add = [](int x, int y)->int {return x + y; };
cout << add(a, b) << endl;
// 实现两个函数交换的 lambda 函数
auto swap = [add, a, b](int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
// cout << add(a, b) << endl; // 在 lambda 函数的函数体中无法直接使用局部的 lambda 函数或者变量(对象).
//cout << AddFunc(a, b) << endl; // 在 lambda 函数的函数体中可以直接使用全局的函数或者变量(对象).
cout << AddFunc(num1, num2) << endl; // 在 lambda 函数的函数体中可以直接使用全局的函数或者变量(对象).
};
swap(a, b);
return 0;
}
小Tips:在 lambda 函数的函数体中可以调用全局的函数,使用全局的变量。但是要想在 lambda 的函数体中使用局部的变量或对象,则需要通过捕捉列表或者参数列表。
3.1 捕捉列表的使用细节
捕捉列表描述了上下文中哪些数据可以被 lambda 使用,以及使用的方式是传值还是传引用。
[var]:表示值传递方式捕捉变量 var。
[=]:表示值传递方式捕捉所有父作用域中的变量(包括this)。
[&var]:表示引用传递捕捉变量 var。
[&]:表示引用方式传递捕捉所有父作用域中的变量(包括this)。
[this]:表示值传递方式捕捉当前的 this 指针。
小Tips:
父作用域指包含 lambda 函数语句块的作用域。
值传递方式捕捉到的变量本质上是父作用域中变量的一份拷贝,在默认情况下会对捕捉到的变量加上 const 属性,即不可以在 lambda 函数体中对捕捉到的变量进行修改。如果想修改可以加上 mutable 取消其常量性。即 [x, y] 捕捉列表中的 x 和 y 是父作用域中 x 和 y 的一份拷贝,并且默认给捕捉列表中的 x 和 y 加上了 const 属性。
引用传递方式既可以捕捉普通的变量也可以捕捉 const 变量。
语法上捕捉列表可以由多个捕捉项组成,并以逗号隔开。例如:[=, &a, &b]:以引用传递的方式捕捉变量 a 和 b,以值传递方式捕捉其他所有变量;[&, a, this]:以值传递方式捕捉变量 a 和 this,以引用方式捕捉其他变量。如果由多个捕捉项组成,= 和 & 只能出现在捕捉列表的开头,即 [&a, &b, = ] 这样写是错误的。
捕捉列表不允许变量重复传递,否则就会导致编译出错。例如:[=, a]:= 已经以值传递的方式捕捉了所有变量,在去捕捉 a 就会导致重复捕捉。
在块作用域以外的 lambda 函数捕捉列表必须为空。
在块作用域中的 lambda 函数仅能捕捉父作用域中的局部变量,捕捉任何非此作用域或者 非局部变量都会导致编译报错。
lambda 表达式之间不能相互赋值,即使看起来类型相同。
四、lambda 的底层原理
lambda 看起来很厉害,但它本质上就是仿函数。
int main()
{
auto func1 = [](int x, int y) {return x + y; };
auto func2 = [](int x, int y) {return x + y; };
cout << typeid(func1).name() << endl;
cout << typeid(func2).name() << endl;
func1(1, 2);
return 0;
}

如上面代码所示,两个仿函数对象 func1 和 func2 它们看起来是一模一样的,但是通过打印它们各自的类型可以看出,它们的类型有所不同,因此 func1 和 func2 本质上就是两个不同的类对象,所以 lambda 表达式之间不能相互赋值,即使看起来类型相同。func1(1, 2) 本质上就是 func1 这个仿函数的对象在调用 operator()。

到此这篇关于深入理解C++11:探索lambda函数的奥秘的文章就介绍到这了,更多相关C++11 lambda函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 本篇文章是对C++中常见关键字的含义进行了详细的分析介绍,需要的朋友参考下2013-05-05
本篇文章是对C++中常见关键字的含义进行了详细的分析介绍,需要的朋友参考下2013-05-05 本篇文章是对goto语句的替代实现方式进行了详细的分析介绍,需要的朋友参考下2013-05-05
本篇文章是对goto语句的替代实现方式进行了详细的分析介绍,需要的朋友参考下2013-05-05 2013-01-01
2013-01-01 这篇文章主要为大家详细介绍了C++中实现时间转换及格式化的相关知识,文中的示例代码讲解详细,具有一定的借鉴价值,感兴趣的小伙伴可以跟随小编一起学习一下2023-11-11
这篇文章主要为大家详细介绍了C++中实现时间转换及格式化的相关知识,文中的示例代码讲解详细,具有一定的借鉴价值,感兴趣的小伙伴可以跟随小编一起学习一下2023-11-11 进程同步是一个操作系统级别的概念,是在多道程序的环境下,存在着不同的制约关系,为了协调这种互相制约的关系,实现资源共享和进程协作,从而避免进程之间的冲突,引入了进程同步2021-06-06
进程同步是一个操作系统级别的概念,是在多道程序的环境下,存在着不同的制约关系,为了协调这种互相制约的关系,实现资源共享和进程协作,从而避免进程之间的冲突,引入了进程同步2021-06-06 本篇文章是对用C语言实践OOP,new,delete进行了详细的分析介绍,需要的朋友参考下2013-05-05
本篇文章是对用C语言实践OOP,new,delete进行了详细的分析介绍,需要的朋友参考下2013-05-05
C++编程中__if_exists与__if_not_exists语句的用法
这篇文章主要介绍了C++编程中__if_exists与__if_not_exists语句的用法,是C++中用于判断指定的标识符是否存在的基础的条件判断语句,需要的朋友可以参考下2016-01-01 Lua 语言不支持真正的多线程,即不支持共享内存的抢占式线程,在执行协程体的 Lua 脚本时,Lua 同样可以调用 C++ 的函数,本文给大家介绍了C++ 与 Lua 的协程交互,需要的朋友可以参考下2024-02-02
Lua 语言不支持真正的多线程,即不支持共享内存的抢占式线程,在执行协程体的 Lua 脚本时,Lua 同样可以调用 C++ 的函数,本文给大家介绍了C++ 与 Lua 的协程交互,需要的朋友可以参考下2024-02-02 函数指针是一个指针变量,它可以存储函数的地址,然后使用函数指针,下面这篇文章主要给大家介绍了关于C语言进阶教程之函数指针的相关资料,需要的朋友可以参考下2022-04-04
函数指针是一个指针变量,它可以存储函数的地址,然后使用函数指针,下面这篇文章主要给大家介绍了关于C语言进阶教程之函数指针的相关资料,需要的朋友可以参考下2022-04-04 这篇文章主要为大家详细介绍了如何利用C语言实现一个简单的静态版通讯录,文中的示例代码讲解详细,对我们学习C语言有一定帮助,需要的可以参考一下2022-08-08
这篇文章主要为大家详细介绍了如何利用C语言实现一个简单的静态版通讯录,文中的示例代码讲解详细,对我们学习C语言有一定帮助,需要的可以参考一下2022-08-08










最新评论