
如何运用sklearn做逻辑回归预测
运用sklearn做逻辑回归预测
逻辑回归算是机器学习中最基础的模型了,回归模型在做分类问题中有着较好的效果。
下面介绍下利用sklearn做逻辑回归模型做模型一般分为:
提取数据---->了解数据(所谓的探索性数据)---->数据预处理(包括但不限于填充缺失值,特征提取,转换哑变量)---->选择模型---->验证模型---->模型优化
下面先简单介绍下逻辑回归的原理
说到逻辑回归就不得不提一下线性回归,线性回归用wiki百科的定义来解释就是:在统计学中,线性回归是一种用来建立响应标量(因变量)和一个或多个解释变量(自变量)之间的模型关系的线性方法。
线性回归分为一元线性回归和多元线性回归。
均方误差是回归模型中常用的度量方法。一般用最小二乘法来最小化均方误差。
线性回归用的最多的是做预测,而逻辑回归最适合的有二分预测,比如是否垃圾邮件,广告是否点击等等;今天的模型用kaggle比赛中的泰坦尼克预测数据集来做逻辑回归模型,故此次我们做的是监督学习。
1.在数据集从kaggle中下载后我们先读取数据和数据预览
通过DataFrame的函数info(),我们可以详细看到数据的分布等情况
import pandas as pd
train=pd.read_csv('D:\\pycm\\kaggle\\titanic\\train.csv',index_col=0) #read train data
test=pd.read_csv('D:\\pycm\\kaggle\\titanic\\test.csv',index_col=0) #read test data
print(train.info()) #show the information about train data,including counting values of null
2.了解数据
查看数据中的缺失值
print(train.isnull().sum()

发现数据中缺失数据Age有177个,Cabin 有687个,Embarked 有2个;由于Cabin 缺失数据占比太大了,我们看下这列数据缺失部分和有值部分对是否获救的情况是如何的,来判断该特征是否需要直接删除。
c=train.Cabin.value_counts() #get the value of Cabin print(c) train.drop(labels=Cabin,axis=1)
3.数据处理
看了下结果发现都是一些客舱号,由于不具有很大的参考意义,在这里我直接把这个特征舍弃掉。
另一个列Embarked是登船的港口,有2个缺失值,我们用出现频率最多的值来填充
train.Embarked=train.Embarked.fillna('S')
Em=train.Embarked.value_counts()
print(Em)接下来是Age有177个缺失值,
由于年龄和姓名相关,我们首先把未缺失的值按照姓名的简称来做下均值分类
train['cc']=train.Name.map(lambda x: str(re.compile(r',(.*)\.').findall(x)))#获取名字中的简称字样Mr,Miss,Mrs,Master,Dr等值
#替换上面的写法:train['cc']=train['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
c=train.loc[:,['cc','Age']].query('Age>0').groupby('cc').mean() #按照名称辅助列看下各年龄的均值最后我们看到结果如下:
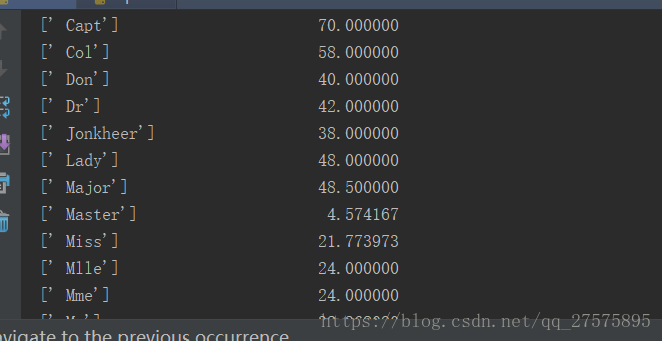
在这里我们对缺失值的年龄填充根据姓名简称的均值来进行填充
train['Age']=train['Age'].fillna(0)#先对缺失值进行0填充
for i in range(1,891):
if train['Age'][i]==0 and train['cc'][i]=="[' Mr']":
train.loc[i, 'Age']=32
if train['Age'][i]==0 and train['cc'][i] =="[' Mrs']":
train.loc[i, 'Age']= 35
if train['Age'][i]==0 and train['cc'][i] == "[' Miss']":
train.loc[i, 'Age']=20
if train['Age'][i]==0 and train['cc'][i] == "[' Master']":
train.loc[i, 'Age']= 4
if train['Age'][i]==0 and train['cc'][i] == "[' Dr']":
train.loc[i,'Age']=42另一种写法,如下:
value=['Mr','Miss','Mrs','Master','Dr']
for v in value:
train.loc[(train.Age==0)&(train.cc==v),'Age']=c.loc[v,'Age']到这里我们就把缺失值处理完了,下面我们对类别值进行处理,我们先看下目前有哪些特征是类别
categore=train.dtypes[train.dtypes=='object'].index
结果为:

我们看到,目前有年龄,船票和登船口是类别型的,这里我们对年龄和登船口做变量赋值
train=train.replace({'Sex':{'male':1,'female':2},
'Embarked':{'S':1,'C':2,'Q':3}}
)后面我们把Name,Ticket等无意义的字段直接删掉
data=data.drop(labels=['cc','Name','Ticket'],axis=1)
到这里就数据处理完啦。由于kaggle数据都是直接把train,test给我们的,所以我一般会前期把train数据集和test数据集放一起做数据处理。
这里前面我们可以在最初做数据拼接操作
data=pd.concat([train,test],keys=(['train','test']))
最后对所有的数据处理完后把数据分开
train_data=data.xs('train')#分开得到level 为train的测试数据
test_data=data.xs('test').drop(labels='Survived',axis=1)
x_train=train_data.drop(labels='Survived',axis=1)
y_train=train_data['Survived']
test_data=test_data.fillna(0)4.选择模型
本次的特征较少,我们就不做特别的特征选取了, 对数据处理完后就直接进入模型阶段,这次我们在这里讲解Logistics回归模型。
首先对模型做均一化处理
from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression
S=StandardScaler()
S.fit(x_train)
x_train_stand=S.transform(x_train)
x_test_stand=S.transform(test_data)
Log=LogisticRegression(C=10)
Log.fit(x_train_stand,y_train) #训练模型
prediction=Log.predict(x_test_stand) #用训练的模型Log来预测测试数据
result=pd.DataFrame({'PassengerId':test_data.index,'Survived':prediction.astype(np.int32)}) #这里需要注意把prediction的数据转换成Int型不然系统判定不了,得分会为0
result.to_csv('D:\\pycm\\kaggle\\titanic\\result.csv',index=False) #设置不输出Index最后将得到的结果提交,就完成啦,

后面还可以对模型进行优化,调参,我们放到下一期来进行讲解。这期讲解逻辑回归就先到这里,我们以一个是否生存的预测问题结尾。
最后附上完整代码:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
import re
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
train=pd.read_csv('D:\\pycm\\kaggle\\titanic\\train.csv',index_col=0) #读文件
test=pd.read_csv('D:\\pycm\\kaggle\\titanic\\test.csv',index_col=0)
data=pd.concat([train,test],keys=(['train','test']))
print(data.info())
data.Embarked=data.Embarked.fillna('S')
data=data.drop(labels='Cabin',axis=1)
#data['cc']=data.Name.map(lambda x: str(re.compile(r',(.*)\.').findall(x)))
data['cc']=data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
c=data.loc[:,['cc','Age']].query('Age>0').groupby('cc').mean()
print(c.loc['Miss','Age'])
value=['Mr','Miss','Mrs','Master','Dr']
data['Age']=data['Age'].fillna(0)
for v in value:
data.loc[(data.Age==0)&(data.cc==v),'Age']=c.loc[v,'Age']
data=data.drop(labels=['cc','Name','Ticket'],axis=1)
data=data.replace({'Sex':{'male':1,'female':2},
'Embarked':{'S':1,'C':2,'Q':3}}
)
train_data=data.xs('train')
test_data=data.xs('test').drop(labels='Survived',axis=1)
x_train=train_data.drop(labels='Survived',axis=1)
y_train=train_data['Survived']
test_data=test_data.fillna(0)
S=StandardScaler()
S.fit(x_train)
x_train_stand=S.transform(x_train)
x_test_stand=S.transform(test_data)
Log=RandomForestClassifier(oob_score=True,random_state=10)
Log.fit(x_train_stand,y_train)
prediction=Log.predict(x_test_stand)
result=pd.DataFrame({'PassengerId':test_data.index,'Survived':prediction.astype(np.int32)})
result.to_csv('D:\\pycm\\kaggle\\titanic\\result.csv',index=False)总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了python中for语句简单遍历数据的方法,以一个简单实例形式分析了Python中for语句遍历数据的技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了python中for语句简单遍历数据的方法,以一个简单实例形式分析了Python中for语句遍历数据的技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了python自动化unittest yaml使用过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了python自动化unittest yaml使用过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了python 通过手机号识别出对应的微信性别,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python 通过手机号识别出对应的微信性别,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12 这篇文章主要为大家详细介绍了Python选课系统开发程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-09-09
这篇文章主要为大家详细介绍了Python选课系统开发程序,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-09-09 这篇文章主要为大家介绍了用Python Tkinter库GUI编程创建图形用户界面,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08
这篇文章主要为大家介绍了用Python Tkinter库GUI编程创建图形用户界面,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08 这篇文章主要介绍了WxPython中控件隐藏与显示的小技巧,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11
这篇文章主要介绍了WxPython中控件隐藏与显示的小技巧,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要介绍了Python 有可能删除 GIL 吗,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了Python 有可能删除 GIL 吗,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03 这篇文章主要给大家介绍了关于python爬虫实例之获取动漫截图的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2020-05-05
这篇文章主要给大家介绍了关于python爬虫实例之获取动漫截图的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2020-05-05 这篇文章主要介绍了Python实现读取机器硬件信息的方法,涉及Python针对计算机注册表、操作系统、处理器、网络等常见硬件信息读取操作相关实现技巧,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了Python实现读取机器硬件信息的方法,涉及Python针对计算机注册表、操作系统、处理器、网络等常见硬件信息读取操作相关实现技巧,需要的朋友可以参考下2018-06-06 在本篇文章里小编给各位分享一篇关于python字典按照value排序方法的相关文章,有兴趣的朋友们可以学习下。2020-12-12
在本篇文章里小编给各位分享一篇关于python字典按照value排序方法的相关文章,有兴趣的朋友们可以学习下。2020-12-12










最新评论