
Python常用的数据清洗方法详解
Python常用的数据清洗方法
在数据处理的过程中,一般都需要进行数据的清洗工作,如数据集是否存在重复、是否存在缺失、数据是否具有完整性和一致性、数据中是否存在异常值等。当发现数据中存在如上可能的问题时,都需要有针对性地处理,本文介绍如何识别和处理重复观测、缺失值和异常值。
重复观测处理
重复观测是指观测行存在重复的现象,重复观测的存在会影响数据分析和挖掘结果的准确性,所以在数学分析和建模之前,需要进行观测的重复性检验,如果存在重复观测,还需要进行重复项的删除。
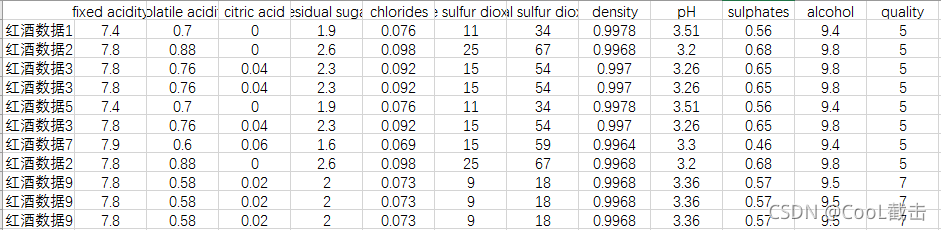
检测数据集的是否重复,pandas 使用duplicated方法,该方法返回的是数据行每一行的检验结果,即每一行返回一个bool值,再使用drop_duplicates方法移除重复值。
import pandas as pd
dataset= pd.read_csv("red_wine_repetition.csv")
print("是否存在重复值:",any(dataset.duplicated())) #输出:True
dataset.drop_duplicates(inplace=True)
dataset.to_csv('red_wine_repetition2.csv',index=False) #保存移除重复值后的数据集缺失值处理
数据缺失在大部分数据分析应用中都很常见,pandas使用浮点值NaN表示浮点或非浮点数组中的缺失数据,python内置的None值也会被当做缺失值处理。
pandas使用isnull方法检测是否为缺失值,检测对象的每个元素返回一个bool值
from numpy import NaN
from pandas import Series
data=Series([5, None, 15, NaN, 25])
print(data.isnull()) #输出每个元素的检测结果
print('是否存在缺失值:',any(data.isnull())) #输出 :True缺失值的处理可以采用三种方法:过滤法、填充法和插值法。过滤法又称删除法,是指当缺失的观测比例非常低时(如5%以内),直接删除存在缺失的观测;或者当某变量缺失的观测比例非常高时(如85%以上),直接删除这些缺失的变量。填充法又称替换法,是指用某种常数直接替换那些缺失值,例如:对于连续值变量采用均值或中位数替换,对于离散值变量采用众数替换。插值法是指根据其他非缺失的变量或观测来预测缺失值,常见的插值法有线性插值法、KNN插值法和Lagrange插值法等。
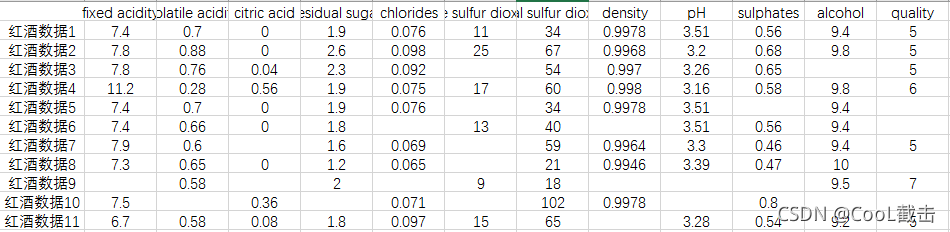
数据过滤
数据过滤dropna 语法格式如下:dropna(axis=0, how='any', thresh=None)
(1)axis=0 表示删除行变量;axis=1 表示删除列变量
(2)how 参数可选值为any或all ,all表删除全为 NaN的行
(3)thresh 为整数类型,表示删除的条件
import pandas as pd
dataset= pd.read_csv("red_wine_deficiency.csv")
data1=dataset.dropna() #删除所有的缺失值
data2=dataset.dropna(axis=1, thresh=9) #删除有效属性小于9的列
data3=dataset.drop("free sulfur dioxide", axis=1) #删除free sulfur dioxide的数据
print(data1,'\n---------------\n',data2,'\n---------------\n',data3)数据填充
当数据中出现缺失值时,可以用其他的数值进行填充,常用的方法是fillna,其语法格式为:fillna(value=None, method=None, axis=None,inplace=Flase)
其中value值除了基本类型外,还可以使用字典,实现对不同的列填充不同的值,method 表示采用填充数据的方法,常用“ffill”、“bfill”。
import pandas as pd
dataset= pd.read_csv("red_wine_deficiency.csv")
data1=dataset.fillna(0) #用0填补所有的缺失值
data2=dataset.fillna(method='ffill') #用前一行的值填补缺失值
data3=dataset.fillna(method='bfill') #用后一行的值填补缺失值,最后一行缺失不处理
data4=dataset.fillna(value={'pH':dataset.pH.mode()[0], #使用众数填补
'density':dataset.density.mean(), #使用均值填补
'alcohol':dataset.alcohol.median()}) #使用中位数填补
print(data1,'\n-----\n',data2,'\n-----\n',data3,'\n-----\n',data4)插值法
当出现缺失值时,也可以使用插值法来对缺失值进行插补,常见的方法为:'linear','nearest','zero','slinear','quadratic','cubic','spline','barycentric','polynomial'.
import pandas as pd
dataset= pd.read_csv("red_wine_deficiency.csv")
data=dataset.fillna(value={'pH':dataset.pH.mode()[0], #使用众数填补
'density':dataset.density.interpolate(method='polynomial',order=2),
#使用二项式插值填补
'alcohol':dataset.alcohol.interpolate()}) #使用线性插值填补
print(data)异常值处理
异常值是指那些远离正常值的观测值,异常值的出现会给模型的常见和预测产生严重的后果,但有时也会利用异常值进行异常数据查找。
对于异常值的检测,一般采用两种方法,一种是标准差法,另一种是箱线图判别法。标准差法的判别公式是outlier > x+nδ 或者outlier < x-nδ,其中x为样本均值,δ为样本标准差。当n=2时,满足条件的观测就是异常值;当n=3时,满足条件的观测就是极端异常值。箱线图的判别公式是outlier > Q3+nIQR 或者outlier < Q1-nIQR,其中Q1为下四分位数,Q3为上四分位数,IQR为上四分位数和下四分位数的差,当n=1.5时,满足条件的观测为异常值,当n=3时,满足条件的观测为极端异常值。
这两种方法的选择标准如下,如果数据近似服从正态分布,因为数据的分布相对比较对称,优先选择标准差法。否则优先选择箱线图法,因为分位数并不会受到极端值的影响。当数据存在异常时,若异常观测的比例不太大,一般可以使用删除法将异常值删除,也可以使用替换法,可以考虑使用低于判别上限的最大值替换上端异常值、高于判别下限的最小值替换下端异常值,或者使用均值、中位数替换

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset= pd.read_csv("red_wine_abnormal.csv")
dataset=dataset['fixed acidity']
mu=dataset.mean() #计算平均值
δ=dataset.std() #计算标准差
print('标准差法异常值上限检测:',any(dataset > mu+2*δ)) #输出:True
print('标准差法异常值下限检测:',any(dataset < mu-2*δ)) #输出:True
Q1=dataset.quantile(0.25) #计算下四分位数
Q3=dataset.quantile(0.75) #计算上四分位数
IQR=Q3-Q1
print('箱线图法异常值上限检测:',any(dataset > Q3+1.5*IQR)) #输出:True
print('箱线图法异常值下限检测:',any(dataset < Q1-1.5*IQR)) #输出:True
plt.style.use('ggplot')
dataset.plot(kind='hist',bins=30,density=True)
dataset.plot(kind='kde')
plt.show()
#替换异常值
UB=Q3+1.5*IQR
st=dataset[dataset < UB].max() #找出低于判断上限的最大值
dataset.loc[dataset >UB] = st
plt.style.use('ggplot')
dataset.plot(kind='hist',bins=30,density=True)
dataset.plot(kind='kde')
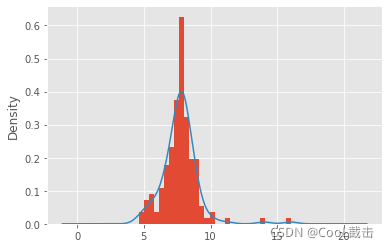
plt.show()运行不同dataset 得到的图像
(1)异常值处理前
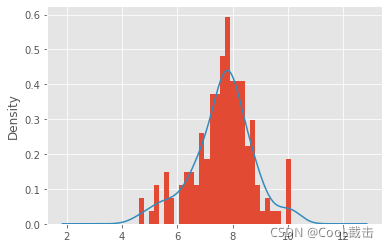
(2)替换异常值后
到此这篇关于Python常用的数据清洗方法详解的文章就介绍到这了,更多相关Python数据清洗方法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了如何解决PyTorch程序占用较高CPU问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了如何解决PyTorch程序占用较高CPU问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09 这篇文章主要和大家分享一个实用的Python脚本,可以实现从给定的网页中检索所有链接,并将其保存为txt文件,需要的小伙伴可以收藏一下2023-05-05
这篇文章主要和大家分享一个实用的Python脚本,可以实现从给定的网页中检索所有链接,并将其保存为txt文件,需要的小伙伴可以收藏一下2023-05-05 重复的任务总是耗费时间和枯燥的。如果逐一裁剪100张照片,或者做诸如Fetching APIs、纠正拼写和语法等任务,所有这些都需要大量的时间。为什么不把它们自动化呢?本文详细介绍了10个Python自动化脚本,感兴趣的小伙伴可以阅读一下2023-03-03
重复的任务总是耗费时间和枯燥的。如果逐一裁剪100张照片,或者做诸如Fetching APIs、纠正拼写和语法等任务,所有这些都需要大量的时间。为什么不把它们自动化呢?本文详细介绍了10个Python自动化脚本,感兴趣的小伙伴可以阅读一下2023-03-03 这篇文章主要介绍了详解Python中如何将数据存储为json格式的文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11
这篇文章主要介绍了详解Python中如何将数据存储为json格式的文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11 这篇文章主要介绍了python利用numpy存取文件案例教程,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了python利用numpy存取文件案例教程,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了flask框架json数据的拿取和返回操作,结合实例形式分析了flask框架针对json格式数据的解析、数据库操作与输出等相关操作技巧,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了flask框架json数据的拿取和返回操作,结合实例形式分析了flask框架针对json格式数据的解析、数据库操作与输出等相关操作技巧,需要的朋友可以参考下2019-11-11 这篇文章主要为大家介绍了python 的while循环嵌套,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12
这篇文章主要为大家介绍了python 的while循环嵌套,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12 这篇文章主要介绍了如何使用Python 绘制瀑布图,我们一起了解瀑布图的重要性,以及如何使用不同的绘图库绘制瀑布图。瀑布图是一种二维图表,专门用于了解随着时间或多个步骤或变量的增量正负变化的影响,下文更多详细内容需要的小伙伴可以参考一下2022-05-05
这篇文章主要介绍了如何使用Python 绘制瀑布图,我们一起了解瀑布图的重要性,以及如何使用不同的绘图库绘制瀑布图。瀑布图是一种二维图表,专门用于了解随着时间或多个步骤或变量的增量正负变化的影响,下文更多详细内容需要的小伙伴可以参考一下2022-05-05 为了方便不会python的朋友也能够使用,本文将用pyqt5将制作一个带界面的无线网连接器,文中的示例代码讲解详细,感兴趣的可以了解一下2022-08-08
为了方便不会python的朋友也能够使用,本文将用pyqt5将制作一个带界面的无线网连接器,文中的示例代码讲解详细,感兴趣的可以了解一下2022-08-08 这篇文章主要介绍了Python闭包和装饰器用法,结合实例形式详细分析了Python闭包和装饰器的相关概念、原理、使用技巧与相关操作注意事项,需要的朋友可以参考下2019-05-05
这篇文章主要介绍了Python闭包和装饰器用法,结合实例形式详细分析了Python闭包和装饰器的相关概念、原理、使用技巧与相关操作注意事项,需要的朋友可以参考下2019-05-05










最新评论