
浅谈PyTorch的数据读取机制Dataloader与Dataset
Dataloader与DataSet数据读取方法
DataLoader与DataSet是PyTorch数据读取的核心。
“torch.utils.DataLoader”的作用是构建一个可迭代的数据装载器,每次执行循环的时候,就从中读取一批Batchsize大小的样本进行训练。
其主要参数有五项:
- dataset:隶属DataSet类,表示数据从哪里读取以及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
上述主要参数中num_works通常在单进程时默认为“0”,也可以在支持多进程的设备上设置为允许的“4 | 8 | 16”等。
shuffle则通常设置为使用乱序(True),以使得每次数据读取具有随机性。
这里颇为重要的是“Epoch、Iteration和Batchsize”之间的关系:
1)Epoch表示所有训练样本都已输入到模型中,记为一个Epoch;
2)Iteration表示一批样本输入到模型中,记为一个Iteration;
3)Batchsize表示批大小,决定一个Epoch中有多少个Iteration。当样本数可以被Batchsize整除时,三者成立关系,即全体样本分成Batchsize分批次输入模型,每批次记为一次Iteration。
若样本总数80个,当Batchsize=8时,可以知道“1 Epoch = 10 Iteration”。
若样本总数87个,当Batchsize-8时,可以知道:1)若“drop_last=True”,则“1 Epoch = 10 Iteration”;2)
若“drop_last=False”,则“1 Epoch = 11 Iteration”,其最后一个Iteration时样本个数为7,小于既定Batchsize。
“torch.utils.data.Dataset”主要用于定义数据从哪里读取以及如何读取的问题。其定义为DataSet抽象类,所有自定义的Dataset都需要继承它,并复写“getitem()”内构函数,该函数接受一个索引,并返回一个样本。

DataLoader与DataSet数据读取机制
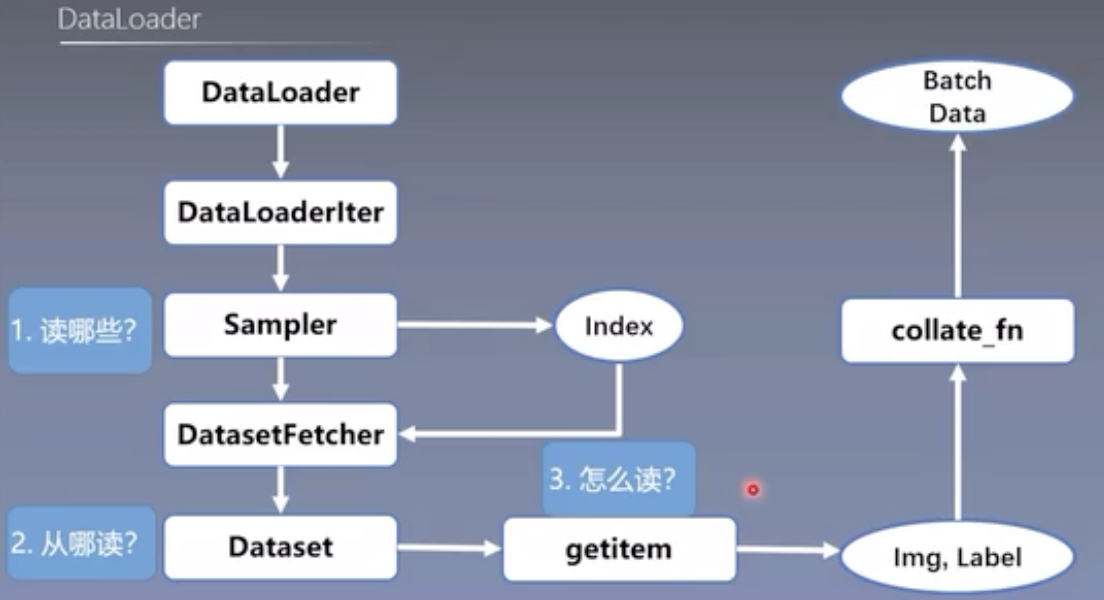
PyTorch的数据读取机制通常围绕三个核心问题展开,即:
读取哪些数据?从哪里读取数据?怎么读取数据?
事实上,通过在PyCharm中进行代码调试,我们可以简要回答上述问题:
1)通过Sampler取样器按序或随机挑选出Batchsize数量的索引列表;
2)使用DataSet中的data_dir指定硬盘上的数据访问路径;
3)使用DataSet中自定义的getitem()方法,基于Sampler返回的索引列表读取相应数据和标签,并拼接成新的列表数据。

事实上,PyTorch的数据读取经过了诸多函数的跳转。在for循环中首先调用了“DataLoader”,进而使用Sampler、Dataset和getitem解决“数据读哪些?从哪读?怎么读?”的问题。
最后,我们提供一份PyTorch中DataLoader数据读取机制的函数跳转流程图,供大家参考学习。
到此这篇关于浅谈PyTorch的数据读取机制Dataloader与Dataset的文章就介绍到这了,更多相关PyTorch的Dataloader与Dataset内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇对python中for 、if、 while的区别与比较方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇对python中for 、if、 while的区别与比较方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 本篇文章介绍了Python基础中所出现的异常报错总结,这是Python日常所常见的错误,现在总结出来给大家。2016-11-11
本篇文章介绍了Python基础中所出现的异常报错总结,这是Python日常所常见的错误,现在总结出来给大家。2016-11-11 这篇文章主要介绍了Python正则表达式和元字符详解,需要的朋友可以参考下2018-11-11
这篇文章主要介绍了Python正则表达式和元字符详解,需要的朋友可以参考下2018-11-11 在本篇内容里小编给大家分享的是关于python中while和for的区别以及相关知识点,需要的朋友们可以学习下。2019-06-06
在本篇内容里小编给大家分享的是关于python中while和for的区别以及相关知识点,需要的朋友们可以学习下。2019-06-06 这篇文章主要介绍了用Python爬虫+数据分析+数据可视化,分析《雪中悍刀行》弹幕,本文很适合初学python的同学入门阅读,需要的朋友可以参考下2022-01-01
这篇文章主要介绍了用Python爬虫+数据分析+数据可视化,分析《雪中悍刀行》弹幕,本文很适合初学python的同学入门阅读,需要的朋友可以参考下2022-01-01 这篇文章主要介绍了keras 简单 lstm实例(基于one-hot编码),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-07-07
这篇文章主要介绍了keras 简单 lstm实例(基于one-hot编码),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-07-07 本文主要对通过Python爬虫代理IP快速增加博客阅读量的方法进行分析介绍。具有很好的参考价值,需要的朋友一起来看下吧2016-12-12
本文主要对通过Python爬虫代理IP快速增加博客阅读量的方法进行分析介绍。具有很好的参考价值,需要的朋友一起来看下吧2016-12-12 这篇文章主要介绍web应用框架如何添加动态路由,在我们编写的框架中,我们添加动态路由,是使用了正则表达式,同时在注册的时候,需要注明该路由是请求路由,文中有详细的代码示例,需要的朋友可以参考下2023-05-05
这篇文章主要介绍web应用框架如何添加动态路由,在我们编写的框架中,我们添加动态路由,是使用了正则表达式,同时在注册的时候,需要注明该路由是请求路由,文中有详细的代码示例,需要的朋友可以参考下2023-05-05 这篇文章主要介绍了Python中那些 Pythonic的写法详解,一份优雅、干净、整洁的代码通常自带文档和注释属性,读代码即是读作者的思路,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了Python中那些 Pythonic的写法详解,一份优雅、干净、整洁的代码通常自带文档和注释属性,读代码即是读作者的思路,需要的朋友可以参考下2019-07-07 这篇文章主要介绍了Python全局变量与global关键字常见错误解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了Python全局变量与global关键字常见错误解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10










最新评论