
Python实现多条件筛选Excel数据并批量绘制直方图
本文介绍基于Python,读取Excel数据,以一列数据的值为标准,对这一列数据处于指定范围的所有行,再用其他几列数据数值,加以筛选与剔除;同时,对筛选与剔除前、后的数据分别绘制若干直方图,并将结果数据导出保存为一个新的Excel表格文件的方法。
首先,我们来明确一下本文的具体需求。现有一个Excel表格文件,在本文中我们就以 .csv 格式的文件为例;其中,如下图所示,这一文件中有一列(在本文中也就是 days 这一列)数据,我们将其作为基准数据,希望首先取出 days 数值处于 0 至 45 、 320 至 365 范围内的所有样本(一行就是一个样本),进行后续的操作。
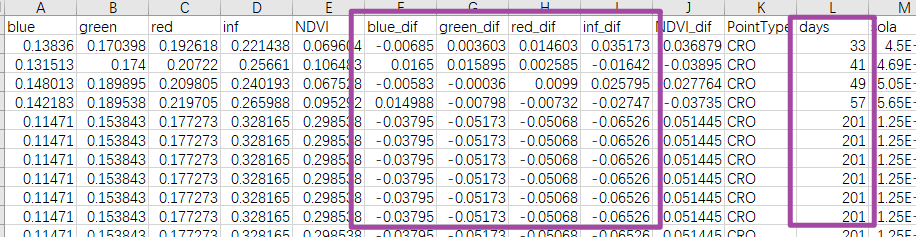
其次,对于取出的样本,再依据其他 4 列(在本文中也就是 blue_dif 、 green_dif 、 red_dif 与 inf_dif 这 4 列)数据,将这 4 列数据不在指定数值区域内的行删除。在这一过程中,我们还希望绘制在数据删除前、后,这 4 列(也就是 blue_dif 、 green_dif 、 red_dif 与 inf_dif 这 4 列)数据各自的直方图,一共是 8 张图。最后,我们还希望将删除上述数据后的数据保存为一个新的Excel表格文件。
知道了需求,我们就可以撰写代码。本文所用的代码如下所示。
# -*- coding: utf-8 -*- """ Created on Tue Sep 12 07:55:40 2023 @author: fkxxgis """ import numpy as np import pandas as pd import matplotlib.pyplot as plt original_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/Train_Model_0715_Main_Over_NIR.csv" # original_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/TEST.csv" result_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/Train_Model_0715_Main_Over_NIR_New.csv" df = pd.read_csv(original_file_path) blue_original = df[(df['blue_dif'] >= -0.08) & (df['blue_dif'] <= 0.08)]['blue_dif'] green_original = df[(df['green_dif'] >= -0.08) & (df['green_dif'] <= 0.08)]['green_dif'] red_original = df[(df['red_dif'] >= -0.08) & (df['red_dif'] <= 0.08)]['red_dif'] inf_original = df[(df['inf_dif'] >= -0.1) & (df['inf_dif'] <= 0.1)]['inf_dif'] mask = ((df['days'] >= 0) & (df['days'] <= 45)) | ((df['days'] >= 320) & (df['days'] <= 365)) range_min = -0.03 range_max = 0.03 df.loc[mask, 'blue_dif'] = df.loc[mask, 'blue_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x])) df.loc[mask, 'green_dif'] = df.loc[mask, 'green_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x])) df.loc[mask, 'red_dif'] = df.loc[mask, 'red_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x])) df.loc[mask, 'inf_dif'] = df.loc[mask, 'inf_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x], p =[0.9, 0.1])) df = df.dropna() blue_new = df[(df['blue_dif'] >= -0.08) & (df['blue_dif'] <= 0.08)]['blue_dif'] green_new = df[(df['green_dif'] >= -0.08) & (df['green_dif'] <= 0.08)]['green_dif'] red_new = df[(df['red_dif'] >= -0.08) & (df['red_dif'] <= 0.08)]['red_dif'] inf_new = df[(df['inf_dif'] >= -0.1) & (df['inf_dif'] <= 0.1)]['inf_dif'] plt.figure(0) plt.hist(blue_original, bins = 50) plt.figure(1) plt.hist(green_original, bins = 50) plt.figure(2) plt.hist(red_original, bins = 50) plt.figure(3) plt.hist(inf_original, bins = 50) plt.figure(4) plt.hist(blue_new, bins = 50) plt.figure(5) plt.hist(green_new, bins = 50) plt.figure(6) plt.hist(red_new, bins = 50) plt.figure(7) plt.hist(inf_new, bins = 50) df.to_csv(result_file_path, index=False)
首先,我们通过 pd.read_csv 函数从指定路径的 .csv 文件中读取数据,并将其存储在名为 df 的DataFrame中。
接下来,通过一系列条件筛选操作,从原始数据中选择满足特定条件的子集。具体来说,我们筛选出了在 blue_dif 、 green_dif 、 red_dif 与 inf_dif 这 4 列中数值在一定范围内的数据,并将这些数据存储在名为 blue_original 、 green_original 、 red_original 和 inf_original 的新Series中,这些数据为我们后期绘制直方图做好了准备。
其次,创建一个名为 mask 的布尔掩码,该掩码用于筛选满足条件的数据。在这里,它筛选出了 days 列的值在 0 到 45 之间或在 320 到 365 之间的数据。
随后,我们使用 apply 函数和 lambda 表达式,对于 days 列的值在 0 到 45 之间或在 320 到 365 之间的行,如果其 blue_dif 、 green_dif 、 red_dif 与 inf_dif 这 4 列的数据不在指定范围内,那么就将这列的数据随机设置为NaN, p =[0.9, 0.1] 则是指定了随机替换为NaN的概率。这里需要注意,如果我们不给出 p =[0.9, 0.1] 这样的概率分布,那么程序将依据均匀分布的原则随机选取数据。
最后,我们使用 dropna 函数,删除包含NaN值的行,从而得到筛选处理后的数据。其次,我们依然根据这四列的筛选条件,计算出处理后的数据的子集,存储在 blue_new 、 green_new 、 red_new 和 inf_new 中。紧接着,使用Matplotlib创建直方图来可视化原始数据和处理后数据的分布;这些直方图被分别存储在 8 个不同的图形中。
代码的最后,将处理后的数据保存为新的 .csv 文件,该文件路径由 result_file_path 指定。
运行上述代码,我们将得到 8 张直方图,如下图所示。且在指定的文件夹中看到结果文件。
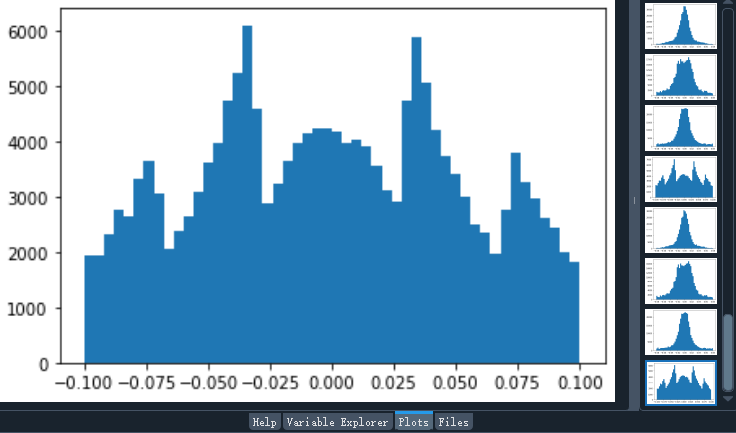
至此,大功告成。
以上就是Python实现多条件筛选Excel数据并批量绘制直方图的详细内容,更多关于Python绘制直方图的资料请关注脚本之家其它相关文章!
相关文章

Linux下升级安装python3.8并配置pip及yum的教程
这篇文章主要介绍了Linux下升级安装python3.8并配置pip及yum的教程,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-01-01 今天小编就为大家分享一篇Python3 实现爬取网站下所有URL方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01
今天小编就为大家分享一篇Python3 实现爬取网站下所有URL方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-01-01 PSUtil是一个跨平台的Python库,用于检索有关正在运行的进程和系统利用率(CPU,内存,磁盘,网络,传感器)的信息。本文就来用PsUtil实现实时监控系统状态,感兴趣的可以跟随小编一起学习一下2023-04-04
PSUtil是一个跨平台的Python库,用于检索有关正在运行的进程和系统利用率(CPU,内存,磁盘,网络,传感器)的信息。本文就来用PsUtil实现实时监控系统状态,感兴趣的可以跟随小编一起学习一下2023-04-04 这篇文章主要介绍了Python+OpenCV实现实时眼动追踪的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-11-11
这篇文章主要介绍了Python+OpenCV实现实时眼动追踪的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-11-11
使用jupyter notebook输出显示不完全的问题及解决
这篇文章主要介绍了使用jupyter notebook输出显示不完全的问题及解决方案,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02 本文主要介绍了python提取字符串中的数字的实现,主要介绍了几种常见的方法,具有一定的参考价值,感兴趣的可以了解一下2023-10-10
本文主要介绍了python提取字符串中的数字的实现,主要介绍了几种常见的方法,具有一定的参考价值,感兴趣的可以了解一下2023-10-10 这篇文章主要介绍了python高阶函数map()和reduce()实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03
这篇文章主要介绍了python高阶函数map()和reduce()实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-03-03
深入浅析Python获取对象信息的函数type()、isinstance()、dir()
这篇文章主要介绍了Python获取对象信息的函数type()、isinstance()、dir()的相关知识,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-09-09 看了许多关于PyTorch的入门文章,大抵是从torchvision.datasets中自带的数据集进行训练,导致很难把PyTorch运用于自己的数据集上,真正地灵活运用PyTorch,本文详细介绍了怎么利用Pytorch实现猫狗分类,需要的朋友可以参考下2021-06-06
看了许多关于PyTorch的入门文章,大抵是从torchvision.datasets中自带的数据集进行训练,导致很难把PyTorch运用于自己的数据集上,真正地灵活运用PyTorch,本文详细介绍了怎么利用Pytorch实现猫狗分类,需要的朋友可以参考下2021-06-06 在写代码的时候,往往会漏掉日志这个关键因素,导致功能在使用的时候出错却无法溯源。这个时候只要利用日志装饰器就能解决,本文将用Python自制一个简单实用的日志装饰器,需要的可以参考一下2022-05-05
在写代码的时候,往往会漏掉日志这个关键因素,导致功能在使用的时候出错却无法溯源。这个时候只要利用日志装饰器就能解决,本文将用Python自制一个简单实用的日志装饰器,需要的可以参考一下2022-05-05










最新评论