
python 自动化数据提取之正则表达式
前 言
我们在做接口自动化的时候,处理接口依赖的相关数据时,通常会使用正则表达式来进行提取相关的数据,今天在这边和大家聊聊如何在python中使用正则表达式。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。按某种规则匹配的表达式被称之为正则表达式,在python使用正则表达式,可以使用官方库re来实现,学习re模块之前,我们先来了解一下正则表达式的基本语法。
正 则 表 达 式 语 法
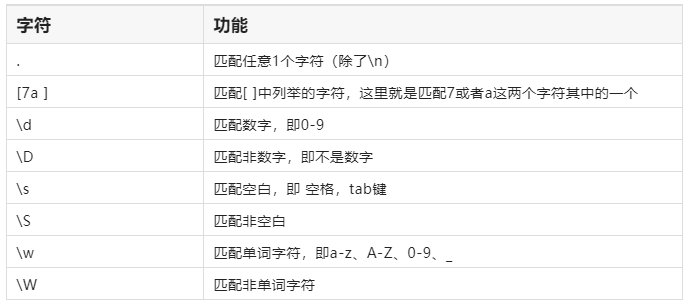
表示单字符
单字符:即表示一个单独的字符,比如匹配数字用\d ,匹配非数字使用\D,具体规则如下:
表示数量
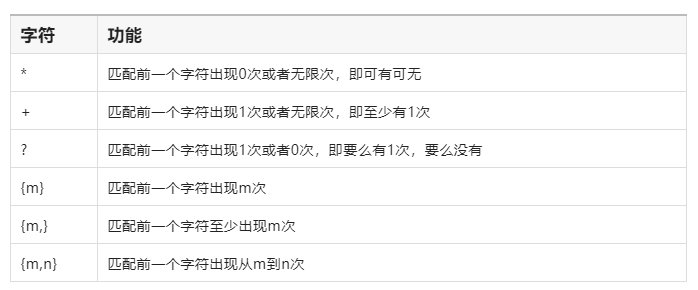
如果要匹配某个字符多次,就可以在字符后面加上数量进行表示,具体规则如下:
表示边界
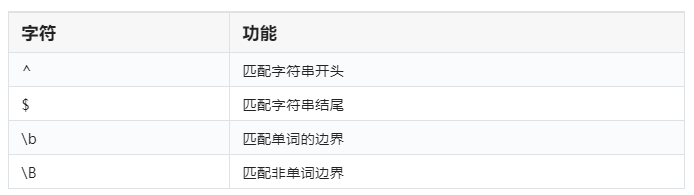
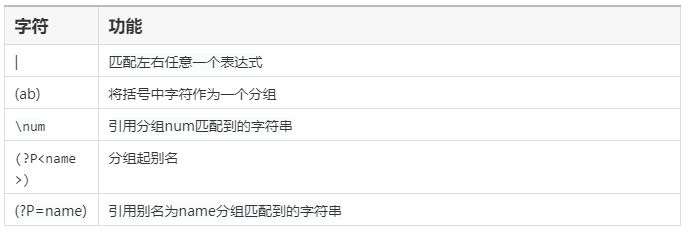
匹配分组
贪婪模式
贪婪模式:Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;
如下案例:有一个字符串s,我们需要在字符串中匹配3个以上的数字,字符串中数字有8个,贪婪模式会尽可能匹配更多字符,3个以上,8个也是3个以上,那么这里匹配的结果就是8个数字。
非贪婪模式:总是尝试匹配尽可能少的字符,在"*“,”?“,”+“,”",后面加上?,可以关闭贪婪模式
关闭贪婪模式之后,尽可能获取更少的,如下,只获取到最前面的3个数值(至少3个,非贪婪就是最前面的3个)
r e 模 块 的 使 用
在python中使用正则表达式,需要用到re模块来进行操作,这边给大家介绍几个re模块中常用的方法。
No.1 re.match函数
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
re.match尝试从字符串的起始位置匹配一个模式,匹配成功 返回的是一个匹配对象(这个对象包含了我们匹配的信息),如果不是起始位置匹配成功的话,match()返回的就是空。
No.2 re.search 方法
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
re.search 扫描整个字符串并返回第一个成功的匹配。
re.match与re.search的区别
re.match从字符串的开始位置进行匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回空;
而re.search匹配整个字符串,直到找到一个匹配成功的则进行返回,如果整个字符串中都没有找到匹配成功的,则返回空。
No.3 findall 方法
参数说明:接收两个参数,
第一个是匹配的规则,
第二个是匹配的目标字符串,
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意:match 和 search 是匹配一个结果, findall 匹配处所有符合规则的结果。
No.4 sub 方法
替换字符串中的某些字符,可以用正则表达式来匹配被选子串。
re.sub(pattern, repl, string, count=0 )
参数:
pattern:匹配的规则;
repl:匹配之后替换的新内容;
string:需要按规则替换的字符串;
count:替换的次数,可以不传参,默认替换所有符合规则的。
案 例 演 示
需求:整个正则表达式提取如下接口登录之后返回的token值。
接口地址:http://47.112.233.130/users/login/
请求参数:
返回结果:
{'refresh': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ0b2tlbl90eXBlIjoicmVmcmVzaCIsImV4cCI6MTY1Mzk4MzMyNSwiaWF0IjoxNjUzODk2OTI1LCJqdGkiOiI2NTE2MTE0OGFhMDY0NWNjYWY2ZWE4YmYzYzY1YjE1ZSIsInVzZXJfaWQiOjJ9.fMkJfOdhczbr1MqvYE5b0qYlC5GewBlFZbrteMOLUv0', 'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ0b2tlbl90eXBlIjoiYWNjZXNzIiwiZXhwIjoxNjUzOTgzMzI1LCJpYXQiOjE2NTM4OTY5MjUsImp0aSI6ImQ3Nzg1ZjY0YTk2YzQwYzliZDcwMmUxMDgzNjVkNWU5IiwidXNlcl9pZCI6Mn0.UNmLRQsXnZBltgL7QQVuBON2UEBQav87NSGy5Iqbnws'}
实现代码
import requests
import re
# 登录接口
login_url = 'http://47.112.233.130:8888/users/login/'
# 请求登录接口,进行登录
params = {
"username": "test",
"password": "123456"
}
response = requests.post(url=login_url, json=params)
#使用正则表达式提取token
result = re.search(r'token":"(.+?)"',response.text)
token = result.group(1)
到此这篇关于python 自动化数据提取之正则表达式的文章就介绍到这了,更多相关python 数据提取正则表达式内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 今天小编就为大家分享一篇关于Pytorch图像分类器的文章,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-10-10
今天小编就为大家分享一篇关于Pytorch图像分类器的文章,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-10-10 这篇文章主要介绍了如何基于matlab相机标定导出xml文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了如何基于matlab相机标定导出xml文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11 这篇文章主要为大家介绍了Pandas字符串操作的各种方法及速度测试,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08
这篇文章主要为大家介绍了Pandas字符串操作的各种方法及速度测试,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-08-08 文章讲述了如何使用Python批量创建后缀为.md的文件夹,生成100个,代码中需要修改的路径、前缀和后缀名,并提供了注意事项和代码示例,感兴趣的朋友跟随小编一起看看吧2025-01-01
文章讲述了如何使用Python批量创建后缀为.md的文件夹,生成100个,代码中需要修改的路径、前缀和后缀名,并提供了注意事项和代码示例,感兴趣的朋友跟随小编一起看看吧2025-01-01 这篇文章主要介绍了python第三方库pygame的使用,pygame一般用来做游戏,在这需要注意在使用pygame提供的功能之前,需要调用init方法,本文给大家介绍的非常详细,需要的朋友可以参考下2022-08-08
这篇文章主要介绍了python第三方库pygame的使用,pygame一般用来做游戏,在这需要注意在使用pygame提供的功能之前,需要调用init方法,本文给大家介绍的非常详细,需要的朋友可以参考下2022-08-08 这篇文章主要介绍了Python seaborn barplot画图案例,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-07-07
这篇文章主要介绍了Python seaborn barplot画图案例,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-07-07 这篇文章主要介绍了Python多进程同步简单实现代码,涉及Python基于Process与Lock模块运行进程与锁机制实现多进程同步的相关技巧,需要的朋友可以参考下2016-04-04
这篇文章主要介绍了Python多进程同步简单实现代码,涉及Python基于Process与Lock模块运行进程与锁机制实现多进程同步的相关技巧,需要的朋友可以参考下2016-04-04 下面小编就为大家带来一篇基于python 字符编码的理解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-09-09
下面小编就为大家带来一篇基于python 字符编码的理解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-09-09
termux中matplotlib无法显示中文问题的解决方法
这篇文章主要介绍了termux中matplotlib无法显示中文问题的解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-01-01
Python如何使用k-means方法将列表中相似的句子归类
这篇文章主要介绍了Python如何使用k-means方法将列表中相似的句子聚为一类,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08










最新评论