
使用python实现knn算法
更新时间:2017年12月20日 10:47:17 作者:chenge_j
这篇文章主要为大家详细介绍了使用python实现knn算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本文实例为大家分享了python实现knn算法的具体代码,供大家参考,具体内容如下
knn算法描述
对需要分类的点依次执行以下操作:
1.计算已知类别数据集中每个点与该点之间的距离
2.按照距离递增顺序排序
3.选取与该点距离最近的k个点
4.确定前k个点所在类别出现的频率
5.返回前k个点出现频率最高的类别作为该点的预测分类
knn算法实现
数据处理
#从文件中读取数据,返回的数据和分类均为二维数组
def loadDataSet(filename):
dataSet = []
labels = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(",")
dataSet.append([float(lineArr[0]),float(lineArr[1])])
labels.append([float(lineArr[2])])
return dataSet , labels
knn算法
#计算两个向量之间的欧氏距离
def calDist(X1 , X2):
sum = 0
for x1 , x2 in zip(X1 , X2):
sum += (x1 - x2) ** 2
return sum ** 0.5
def knn(data , dataSet , labels , k):
n = shape(dataSet)[0]
for i in range(n):
dist = calDist(data , dataSet[i])
#只记录两点之间的距离和已知点的类别
labels[i].append(dist)
#按照距离递增排序
labels.sort(key=lambda x:x[1])
count = {}
#统计每个类别出现的频率
for i in range(k):
key = labels[i][0]
if count.has_key(key):
count[key] += 1
else : count[key] = 1
#按频率递减排序
sortCount = sorted(count.items(),key=lambda item:item[1],reverse=True)
return sortCount[0][0]#返回频率最高的key,即label
结果测试
已知类别数据(来源于西瓜书+虚构)
0.697,0.460,1
0.774,0.376,1
0.720,0.330,1
0.634,0.264,1
0.608,0.318,1
0.556,0.215,1
0.403,0.237,1
0.481,0.149,1
0.437,0.211,1
0.525,0.186,1
0.666,0.091,0
0.639,0.161,0
0.657,0.198,0
0.593,0.042,0
0.719,0.103,0
0.671,0.196,0
0.703,0.121,0
0.614,0.116,0
绘图方法
def drawPoints(data , dataSet, labels):
xcord1 = [];
ycord1 = [];
xcord2 = [];
ycord2 = [];
for i in range(shape(dataSet)[0]):
if labels[i][0] == 0:
xcord1.append(dataSet[i][0])
ycord1.append(dataSet[i][1])
if labels[i][0] == 1:
xcord2.append(dataSet[i][0])
ycord2.append(dataSet[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='blue', marker='s',label=0)
ax.scatter(xcord2, ycord2, s=30, c='green',label=1)
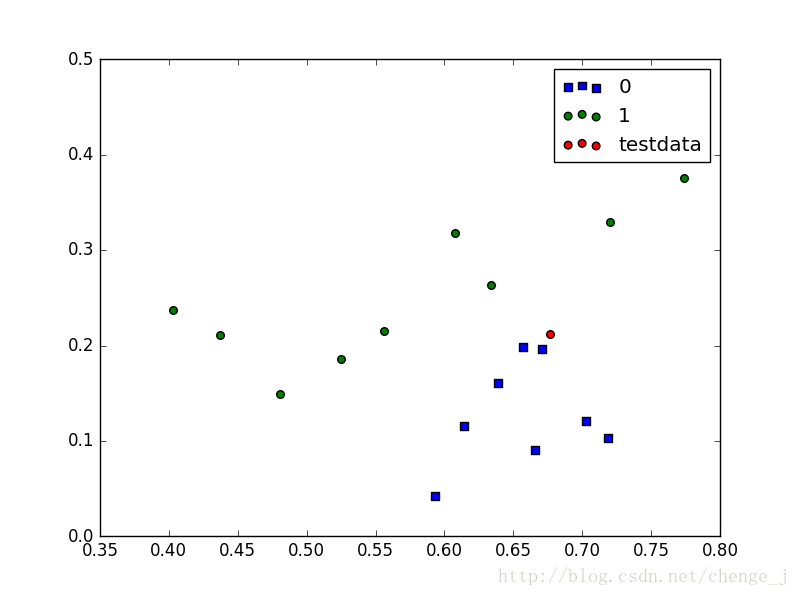
ax.scatter(data[0], data[1], s=30, c='red',label="testdata")
plt.legend(loc='upper right')
plt.show()
测试代码
dataSet , labels = loadDataSet('dataSet.txt')
data = [0.6767,0.2122]
drawPoints(data , dataSet, labels)
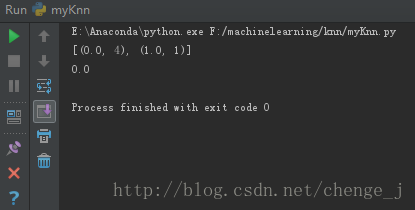
newlabels = knn(data, dataSet , labels , 5)
print newlabels
运行结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 在用谷歌在搜索技术文章时,总是时不时的打不开网页,于是写了一个python脚本,感觉用着还行,分享给大家2013-02-02
在用谷歌在搜索技术文章时,总是时不时的打不开网页,于是写了一个python脚本,感觉用着还行,分享给大家2013-02-02 这篇文章主要介绍了基于python+selenium的二次封装的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01
这篇文章主要介绍了基于python+selenium的二次封装的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01 今天为大家整理了十张动图GIFS,有助于认识循环、递归、二分检索等概念的具体运行情况。代码实例以Python语言编写,非常不错,感兴趣的朋友跟随小编一起学习吧2021-02-02
今天为大家整理了十张动图GIFS,有助于认识循环、递归、二分检索等概念的具体运行情况。代码实例以Python语言编写,非常不错,感兴趣的朋友跟随小编一起学习吧2021-02-02 本文主要为大家介绍了Python中一个优秀的可视化库—HoloViews,不仅能实现一些常见的统计图表绘制,而且其还拥有Matplotlib、Seaborn等库所不具备的交互效果,快跟随小编一起了解一下吧2022-02-02
本文主要为大家介绍了Python中一个优秀的可视化库—HoloViews,不仅能实现一些常见的统计图表绘制,而且其还拥有Matplotlib、Seaborn等库所不具备的交互效果,快跟随小编一起了解一下吧2022-02-02 这篇文章主要介绍了使用python中的openpyxl操作excel详解,openpyxl 模块是一个读写Excel文档的Python库,本文就来讲解如何使用openpyxl操作excel,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了使用python中的openpyxl操作excel详解,openpyxl 模块是一个读写Excel文档的Python库,本文就来讲解如何使用openpyxl操作excel,需要的朋友可以参考下2023-07-07 Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的套餐,其由Scikit-Learn API延伸而来,对模型选择过程其指导作用。这篇文章主要介绍了Python可视化神器Yellowbrick使用,需要的朋友可以参考下2019-11-11
Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的套餐,其由Scikit-Learn API延伸而来,对模型选择过程其指导作用。这篇文章主要介绍了Python可视化神器Yellowbrick使用,需要的朋友可以参考下2019-11-11 Python提供了一些库和工具可以用于图片的相似度比对,本文就详细的介绍了两种实现方法,感知哈希和结构相似性,下面就来介绍一下,感兴趣的可以了解一下2023-10-10
Python提供了一些库和工具可以用于图片的相似度比对,本文就详细的介绍了两种实现方法,感知哈希和结构相似性,下面就来介绍一下,感兴趣的可以了解一下2023-10-10 本文主要介绍了在Windows系统上解决pip命令找不到的问题的两种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-03-03
本文主要介绍了在Windows系统上解决pip命令找不到的问题的两种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-03-03
python PIL中ImageFilter模块图片滤波处理和使用方法
这篇文章主要介绍PIL中ImageFilter模块几种图片滤波处理和使用方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-11-11 这篇文章主要为大家详细介绍了python模拟实现图书管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03
这篇文章主要为大家详细介绍了python模拟实现图书管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03










最新评论