
Python实现k-means算法
更新时间:2018年02月23日 10:25:06 作者:the_Chain_Warden
这篇文章主要为大家详细介绍了Python实现k-means算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本文实例为大家分享了Python实现k-means算法的具体代码,供大家参考,具体内容如下
这也是周志华《机器学习》的习题9.4。
数据集是西瓜数据集4.0,如下
编号,密度,含糖率
1,0.697,0.46
2,0.774,0.376
3,0.634,0.264
4,0.608,0.318
5,0.556,0.215
6,0.403,0.237
7,0.481,0.149
8,0.437,0.211
9,0.666,0.091
10,0.243,0.267
11,0.245,0.057
12,0.343,0.099
13,0.639,0.161
14,0.657,0.198
15,0.36,0.37
16,0.593,0.042
17,0.719,0.103
18,0.359,0.188
19,0.339,0.241
20,0.282,0.257
21,0.784,0.232
22,0.714,0.346
23,0.483,0.312
24,0.478,0.437
25,0.525,0.369
26,0.751,0.489
27,0.532,0.472
28,0.473,0.376
29,0.725,0.445
30,0.446,0.459
算法很简单,就不解释了,代码也不复杂,直接放上来:
# -*- coding: utf-8 -*-
"""Excercise 9.4"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sys
import random
data = pd.read_csv(filepath_or_buffer = '../dataset/watermelon4.0.csv', sep = ',')[["密度","含糖率"]].values
########################################## K-means #######################################
k = int(sys.argv[1])
#Randomly choose k samples from data as mean vectors
mean_vectors = random.sample(data,k)
def dist(p1,p2):
return np.sqrt(sum((p1-p2)*(p1-p2)))
while True:
print mean_vectors
clusters = map ((lambda x:[x]), mean_vectors)
for sample in data:
distances = map((lambda m: dist(sample,m)), mean_vectors)
min_index = distances.index(min(distances))
clusters[min_index].append(sample)
new_mean_vectors = []
for c,v in zip(clusters,mean_vectors):
new_mean_vector = sum(c)/len(c)
#If the difference betweenthe new mean vector and the old mean vector is less than 0.0001
#then do not updata the mean vector
if all(np.divide((new_mean_vector-v),v) < np.array([0.0001,0.0001]) ):
new_mean_vectors.append(v)
else:
new_mean_vectors.append(new_mean_vector)
if np.array_equal(mean_vectors,new_mean_vectors):
break
else:
mean_vectors = new_mean_vectors
#Show the clustering result
total_colors = ['r','y','g','b','c','m','k']
colors = random.sample(total_colors,k)
for cluster,color in zip(clusters,colors):
density = map(lambda arr:arr[0],cluster)
sugar_content = map(lambda arr:arr[1],cluster)
plt.scatter(density,sugar_content,c = color)
plt.show()
运行方式:在命令行输入 python k_means.py 4。其中4就是k。
下面是k分别等于3,4,5的运行结果,因为一开始的均值向量是随机的,所以每次运行结果会有不同。
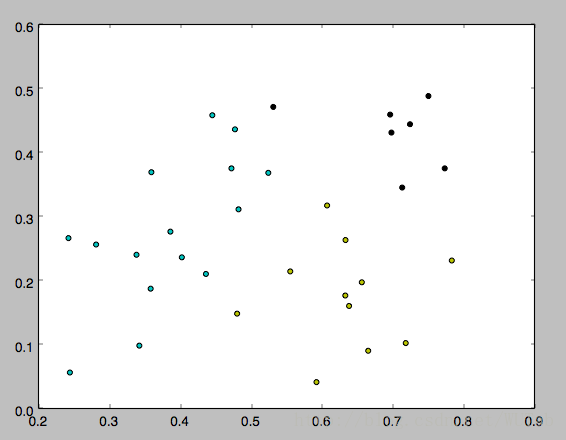
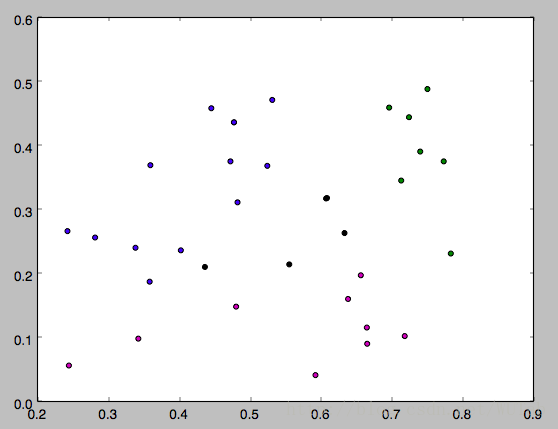

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了Python中的xml与dict的转换方法详解,xml 是指可扩展标记语言,一种标记语言类似html,作用是传输数据,而且不是显示数据。可以自定义标签,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了Python中的xml与dict的转换方法详解,xml 是指可扩展标记语言,一种标记语言类似html,作用是传输数据,而且不是显示数据。可以自定义标签,需要的朋友可以参考下2023-07-07 这篇文章主要介绍了postman发送文件请求并以python服务接收方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-07-07
这篇文章主要介绍了postman发送文件请求并以python服务接收方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-07-07 本文实例讲述了Python中统计代码片段、函数运行耗时的几种方法,分享给大家,仅供参考。2021-04-04
本文实例讲述了Python中统计代码片段、函数运行耗时的几种方法,分享给大家,仅供参考。2021-04-04 这篇文章主要介绍了Python数据结构之翻转链表的相关资料,需要的朋友可以参考下2017-02-02
这篇文章主要介绍了Python数据结构之翻转链表的相关资料,需要的朋友可以参考下2017-02-02 这篇文章主要为大家详细介绍了python2.7实现邮件发送功能包,含文本、附件、正文图片等,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12
这篇文章主要为大家详细介绍了python2.7实现邮件发送功能包,含文本、附件、正文图片等,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12 在处理和分析PDF文档时,获取文本和图片在页面上的精确位置是一个重要的操作,通过确定这些元素的具体坐标,我们可以实现对PDF内容的更精细控制和理解,本文将介绍如何使用Python获取PDF文本和图片在页面上的位置坐标,需要的朋友可以参考下2024-12-12
在处理和分析PDF文档时,获取文本和图片在页面上的精确位置是一个重要的操作,通过确定这些元素的具体坐标,我们可以实现对PDF内容的更精细控制和理解,本文将介绍如何使用Python获取PDF文本和图片在页面上的位置坐标,需要的朋友可以参考下2024-12-12 这篇文章主要为大家详细介绍了Python OpenCV利用笔记本摄像头实现人脸检测,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04
这篇文章主要为大家详细介绍了Python OpenCV利用笔记本摄像头实现人脸检测,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04 这篇文章主要为大家详细介绍了python如何在终端里面显示一张图片的方法,感兴趣的小伙伴们可以参考一下2016-08-08
这篇文章主要为大家详细介绍了python如何在终端里面显示一张图片的方法,感兴趣的小伙伴们可以参考一下2016-08-08
Python3自定义http/https请求拦截mitmproxy脚本实例
这篇文章主要介绍了Python3自定义http/https请求拦截mitmproxy脚本实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05 学点数据爬虫基础能让繁琐的数据CV工作(Ctrl+C,Ctrl+V)成为自动化就足够了.作为一名数据分析师而并非开发工程师,需要掌握的爬虫必备的知识内容,能获取需要的数据即可 ,需要的朋友可以参考下2021-06-06
学点数据爬虫基础能让繁琐的数据CV工作(Ctrl+C,Ctrl+V)成为自动化就足够了.作为一名数据分析师而并非开发工程师,需要掌握的爬虫必备的知识内容,能获取需要的数据即可 ,需要的朋友可以参考下2021-06-06










最新评论