
在python环境下运用kafka对数据进行实时传输的方法
背景:
为了满足各个平台间数据的传输,以及能确保历史性和实时性。先选用kafka作为不同平台数据传输的中转站,来满足我们对跨平台数据发送与接收的需要。
kafka简介:
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
总之:kafka做为中转站有以下功能:
1.生产者(产生数据或者说是从外部接收数据)
2.消费着(将接收到的数据转花为自己所需用的格式)
环境:
1.python3.5.x
2.kafka1.4.3
3.pandas
准备开始:
1.kafka的安装
pip install kafka-python
2.检验kafka是否安装成功
3.pandas的安装
pip install pandas
4.kafka数据的传输
直接撸代码:
# -*- coding: utf-8 -*-
'''
@author: 真梦行路
@file: kafka.py
@time: 2018/9/3 10:20
'''
import sys
import json
import pandas as pd
import os
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "xxx.xxx.x.xxx" #服务器端口地址
KAFAKA_PORT = 9092 #端口号
KAFAKA_TOPIC = "topic0" #topic
data=pd.read_csv(os.getcwd()+'\\data\\1.csv')
key_value=data.to_json()
class Kafka_producer():
'''
生产模块:根据不同的key,区分消息
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.key = key
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort)
)
def sendjsondata(self, params):
try:
parmas_message = params #注意dumps
producer = self.producer
producer.send(self.kafkatopic, key=self.key, value=parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print(e)
class Kafka_consumer():
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid,key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.key = key
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort)
)
def consume_data(self):
try:
for message in self.consumer:
yield message
except KeyboardInterrupt as e:
print(e)
def sortedDictValues(adict):
items = adict.items()
items=sorted(items,reverse=False)
return [value for key, value in items]
def main(xtype, group, key):
'''
测试consumer和producer
'''
if xtype == "p":
# 生产模块
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, key)
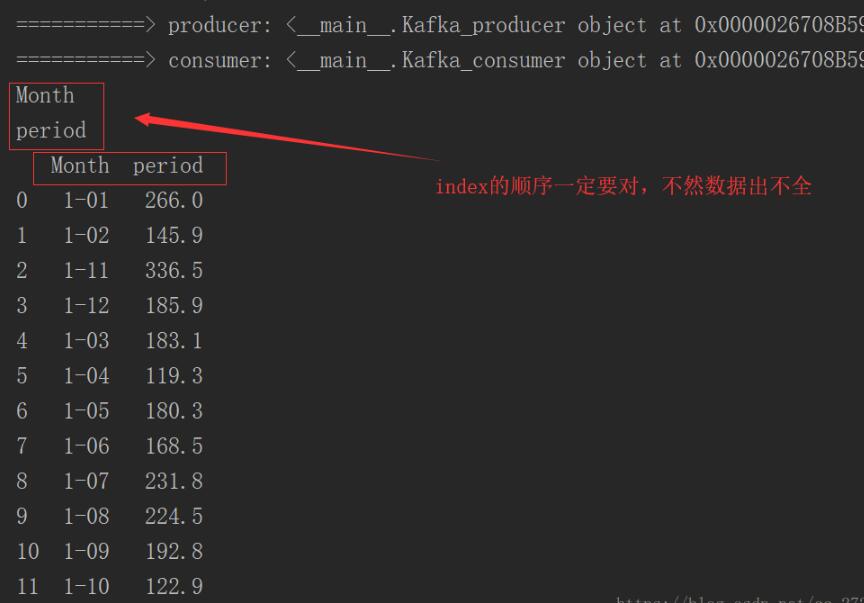
print("===========> producer:", producer)
params =key_value
producer.sendjsondata(params)
if xtype == 'c':
# 消费模块
consumer = Kafka_consumer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, group,key)
print("===========> consumer:", consumer)
message = consumer.consume_data()
for msg in message:
msg=msg.value.decode('utf-8')
python_data=json.loads(msg) ##这是一个字典
key_list=list(python_data)
test_data=pd.DataFrame()
for index in key_list:
print(index)
if index=='Month':
a1=python_data[index]
data1 = sortedDictValues(a1)
test_data[index]=data1
else:
a2 = python_data[index]
data2 = sortedDictValues(a2)
test_data[index] = data2
print(test_data)
# print('value---------------->', python_data)
# print('msg---------------->', msg)
# print('key---------------->', msg.kry)
# print('offset---------------->', msg.offset)
if __name__ == '__main__':
main(xtype='p',group='py_test',key=None)
main(xtype='c',group='py_test',key=None)
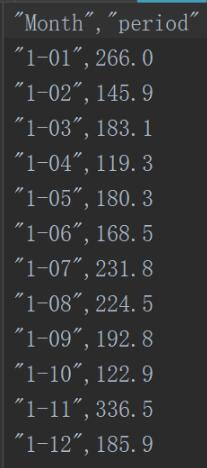
数据1.csv如下所示:
几点注意:
1、一定要有一个服务器的端口地址,不要用本机的ip或者乱写一个ip不然程序会报错。(我开始就是拿本机ip怼了半天,总是报错)
2、注意数据的传输格式以及编码问题(二进制传输),数据先转成json数据格式传输,然后将json格式转为需要格式。(不是json格式的注意dumps)
例中,dataframe->json->dataframe
3、例中dict转dataframe,也可以用简单方法直接转。
eg: type(data) ==>dict,data=pd.Dateframe(data)
以上这篇在python环境下运用kafka对数据进行实时传输的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 这个天气预报采集是从中国天气网提取广东省内主要城市的天气并回显。本来是打算采集腾讯天气的,但是貌似它的数据是用js写上去还是什么的,得到的html文本中不包含数据,所以就算了2012-10-10
这个天气预报采集是从中国天气网提取广东省内主要城市的天气并回显。本来是打算采集腾讯天气的,但是貌似它的数据是用js写上去还是什么的,得到的html文本中不包含数据,所以就算了2012-10-10 下面小编就为大家分享一篇对Python字符串中的换行符和制表符介绍,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
下面小编就为大家分享一篇对Python字符串中的换行符和制表符介绍,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 这篇文章主要介绍了详解Python的Django框架中的模版继承,就像Python中面对对象的方法继承道理类似,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了详解Python的Django框架中的模版继承,就像Python中面对对象的方法继承道理类似,需要的朋友可以参考下2015-07-07 今天小编就为大家分享一篇python 随机打乱 图片和对应的标签方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇python 随机打乱 图片和对应的标签方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 在Django项目中会碰到一些需求就是查询某个表中的一些字段从某日到某日的数据,你可以像在SQL中那样使用SELECT语句来查找指定字段,本文就来介绍两种方法,感兴趣的可以了解一下2023-10-10
在Django项目中会碰到一些需求就是查询某个表中的一些字段从某日到某日的数据,你可以像在SQL中那样使用SELECT语句来查找指定字段,本文就来介绍两种方法,感兴趣的可以了解一下2023-10-10
python为tornado添加recaptcha验证码功能
tornado作为微框架,并没有自带验证码组件,recaptcha是著名的验证码解决方案,简单易用,被很多公司运用来防止恶意注册和评论。tornado添加recaptchaHA非常容易2014-02-02 这篇文章主要介绍了Python闭包和装饰器用法,结合实例形式详细分析了Python闭包和装饰器的相关概念、原理、使用技巧与相关操作注意事项,需要的朋友可以参考下2019-05-05
这篇文章主要介绍了Python闭包和装饰器用法,结合实例形式详细分析了Python闭包和装饰器的相关概念、原理、使用技巧与相关操作注意事项,需要的朋友可以参考下2019-05-05 这篇文章主要介绍了Python中的匿名函数的使用,lambda是各个现代编程语言中的重要功能,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python中的匿名函数的使用,lambda是各个现代编程语言中的重要功能,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了Python条件分支和循环用法,结合实例形式较为详细的分析了Python逻辑运算操作符,条件分支语句,循环语句等功能与基本用法,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了Python条件分支和循环用法,结合实例形式较为详细的分析了Python逻辑运算操作符,条件分支语句,循环语句等功能与基本用法,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了python调用机器喇叭发出蜂鸣声(Beep)的方法,实例分析了Python调用winsound模块的使用技巧,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了python调用机器喇叭发出蜂鸣声(Beep)的方法,实例分析了Python调用winsound模块的使用技巧,需要的朋友可以参考下2015-03-03










最新评论