
Python利用lxml模块爬取豆瓣读书排行榜的方法与分析
前言
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢。本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快。
本次爬取的豆瓣书籍排行榜的首页地址是:
https://www.douban.com/doulist/1264675/?start=0&sort=time&playable=0&sub_type=
该排行榜一共有22页,且发现更改网址的 start=0 的 0 为25、50就可以跳到排行榜的第二、第三页,所以后面只需更改这个数字然后通过遍历就可以爬取整个排行榜的书籍信息。
本次爬取的内容有书名、评分、评价数、出版社、出版年份以及书籍封面图,封面图保存为图片,其他数据存为csv文件,方面后面读取分析。
本次的项目步骤:一、分析网页,确定爬取数据
二、使用lxml库爬取内容并保存
三、读取数据并选择部分内容进行分析
步骤一:
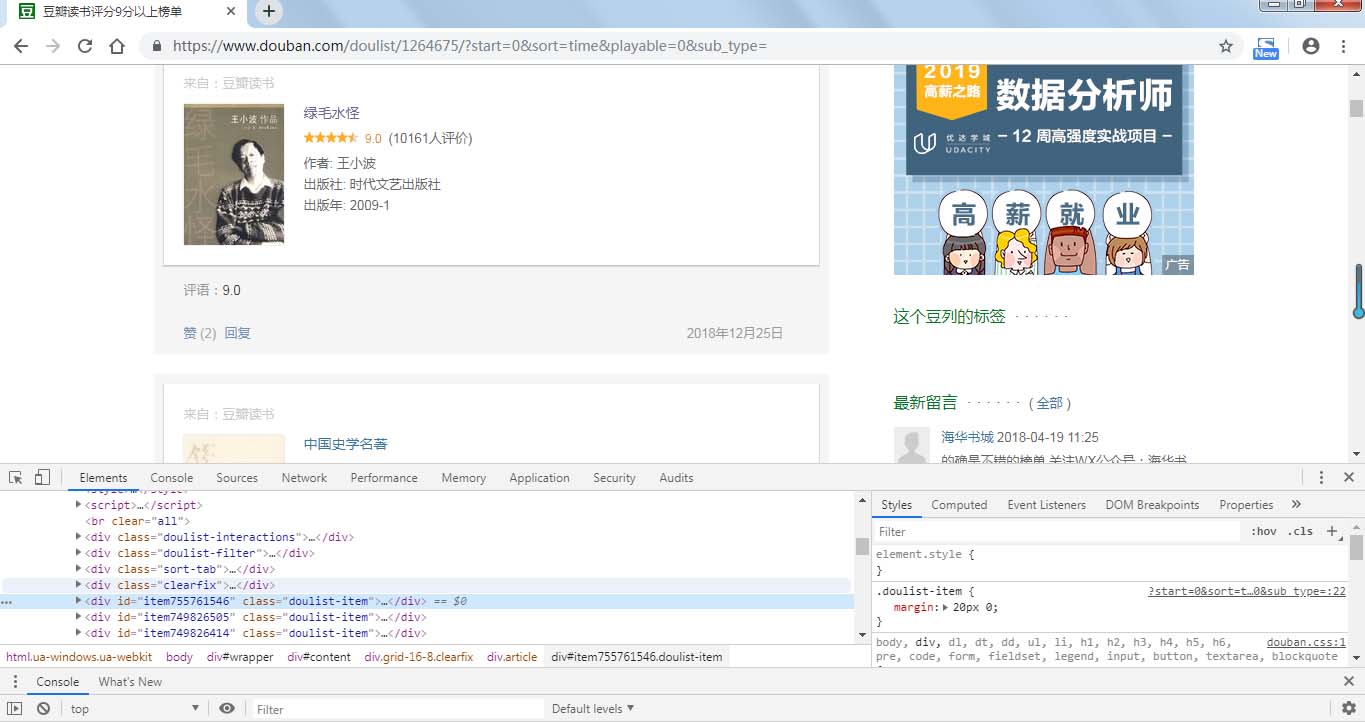
分析网页源代码可以看到,书籍信息在属性为的div标签中,打开发现,我们需要爬取的信息都在标签内部,通过xpath语法我们可以很简便的爬取所需内容。
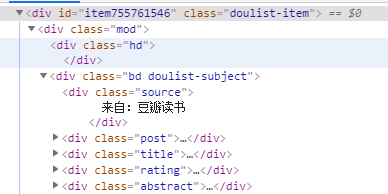
(书籍各类信息所在标签)
所需爬取的内容在 class为post、title、rating、abstract的div标签中。
步骤二:
先定义爬取函数,爬取所需内容执行函数,并存入csv文件
具体代码如下:
import requests
from lxml import etree
import time
import csv
#信息头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#定义爬取函数
def douban_booksrank(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
contents = selector.xpath('//div[@class="article"]/div[contains(@class,"doulist-item")]') #循环点
for content in contents:
try:
title = content.xpath('div/div[2]/div[3]/a/text()')[0] #书名
scores = content.xpath('div/div[2]/div[4]/span[2]/text()') #评分
scores.append('9.0') #因为有一些书没有评分,导致列表为空,此处添加一个默认评分,若无评分则默认为9.0
score = scores[0]
comments = content.xpath('div/div[2]/div[4]/span[3]/text()')[0] #评论数量
author = content.xpath('div/div[2]/div[5]/text()[1]')[0] #作者
publishment = content.xpath('div/div[2]/div[5]/text()[2]')[0] #出版社
pub_year = content.xpath('div/div[2]/div[5]/text()[3]')[0] #出版时间
img_url = content.xpath('div/div[2]/div[2]/a/img/@src')[0] #书本图片的网址
img = requests.get(img_url) #解析图片网址,为下面下载图片
img_name_file = 'C:/Users/lenovo/Desktop/douban_books/{}.png'.format((title.strip())[:3]) #图片存储位置,图片名只取前3
#写入csv
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as fp: #newline 使不隔行
writer = csv.writer(fp)
writer.writerow((title, score, comments, author, publishment, pub_year, img_url))
#下载图片,为防止图片名导致格式错误,加入try...except
try:
with open(img_name_file, 'wb')as imgf:
imgf.write(img.content)
except FileNotFoundError or OSError:
pass
time.sleep(0.5) #睡眠0.5s
except IndexError:
pass
#执行程序
if __name__=='__main__':
#爬取所有书本,共22页的内容
urls = ['https://www.douban.com/doulist/1264675/?start={}&sort=time&playable=0&sub_type='.format(str(i))for i in range(0,550,25)]
#写csv首行
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as f:
writer = csv.writer(f)
writer.writerow(('title', 'score', 'comment', 'author', 'publishment', 'pub_year', 'img_url'))
#遍历所有网页,执行爬取程序
for url in urls:
douban_booksrank(url)
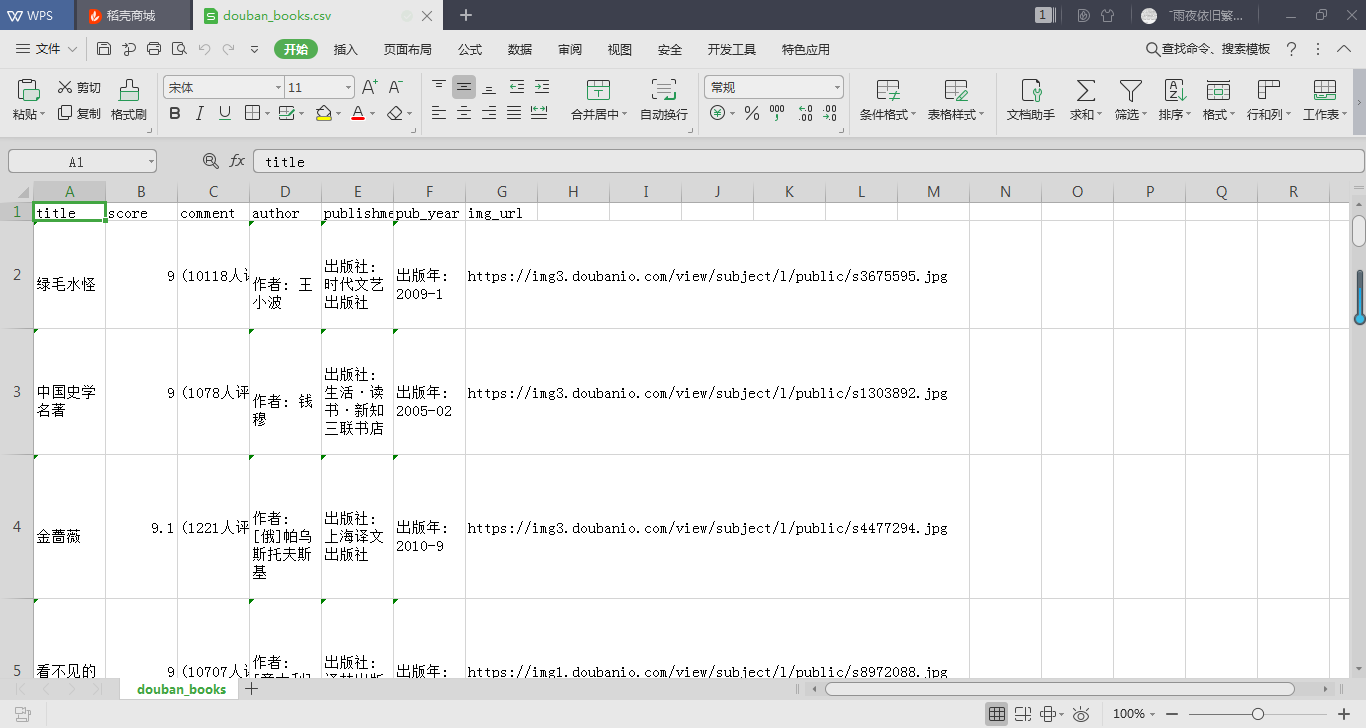
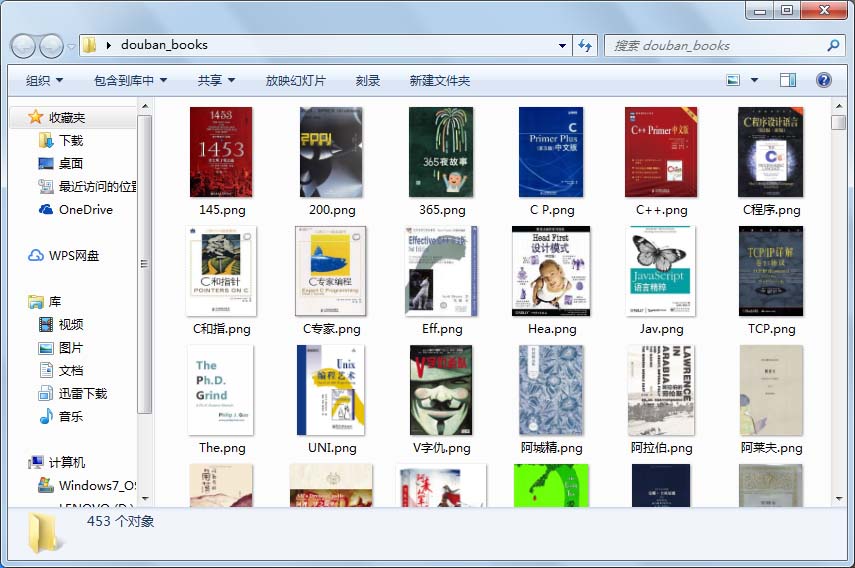
爬取结果截图如下:
步骤三:
本次使用Python常用的数据分析库pandas来提取所需内容。pandas的read_csv()函数可以读取csv文件并根据文件格式转换为Series、DataFrame或面板对象。
此处我们提取的数据转变为DataFrame(数据帧)对象,然后通过Matplotlib绘图库来进行绘图。
具体代码如下:
from matplotlib import pyplot as plt
import pandas as pd
import re
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.subplots_adjust(wsapce=0.5, hspace=0.5) #调整subplot子图间的距离
pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示
df = pd.read_csv('C:\\Users\lenovo\Desktop\\douban_books.csv') #读取csv文件,并赋为dataframe对象
comment = re.findall('\((.*?)人评价', str(df.comment), re.S) #使用正则表达式获取评论人数
#将comment的元素化为整型
new_comment = []
for i in comment:
new_comment.append(int(i))
pub_year = re.findall(r'\d{4}', str(df.pub_year),re.S) #获取书籍出版年份
#同上
new_pubyear = []
for n in pub_year:
new_pubyear.append(int(n))
#绘图
#1、绘制书籍评分范围的直方图
plt.subplot(2,2,1)
plt.hist(df.score, bins=16, edgecolor='black')
plt.title('豆瓣书籍排行榜评分分布', fontweight=700)
plt.xlabel('scores')
plt.ylabel('numbers')
#绘制书籍评论数量的直方分布图
plt.subplot(222)
plt.hist(new_comment, bins=16, color='green', edgecolor='yellow')
plt.title('豆瓣书籍排行榜评价分布', fontweight=700)
plt.xlabel('评价数')
plt.ylabel('书籍数量(单位/本)')
#绘制书籍出版年份分布图
plt.subplot(2,2,3)
plt.hist(new_pubyear, bins=30, color='indigo',edgecolor='blue')
plt.title('书籍出版年份分布', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('书籍数量/本')
#寻找关系
plt.subplot(224)
plt.bar(new_pubyear,new_comment, color='red', edgecolor='white')
plt.title('书籍出版年份与评论数量的关系', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('评论数')
plt.savefig('C:\\Users\lenovo\Desktop\\douban_books_analysis.png') #保存图片
plt.show()
这里需要注意的是,使用了正则表达式来提取评论数和出版年份,将其中的符号和文字等剔除。
分析结果如下:
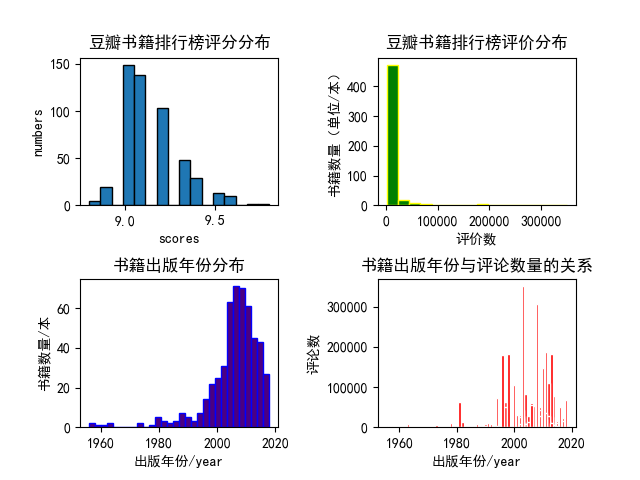
本次分析的内容也较为简单,从上面的几个图形中我们也能得出一些结论。
这些高分书籍中绝大多数的评论数量都在50000以下;多数排行榜上的高分书籍都出版在2000年以后;出版年份在2000年后的书籍有更多的评论数量。
以上数据也见解的说明了在进入二十世纪后我国的图书需求量更大了,网络更发达,更多人愿意发表自己的看法。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。
相关文章
 今天小编就为大家分享一篇python web自制框架之接受url传递过来的参数实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12
今天小编就为大家分享一篇python web自制框架之接受url传递过来的参数实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 Python中的multipart/form-data是一种HTTP POST请求的数据格式,用于上传文件或二进制数据,下面这篇文章主要给大家介绍了关于python使用form-data形式上传文件请求的相关资料,需要的朋友可以参考下2023-04-04
Python中的multipart/form-data是一种HTTP POST请求的数据格式,用于上传文件或二进制数据,下面这篇文章主要给大家介绍了关于python使用form-data形式上传文件请求的相关资料,需要的朋友可以参考下2023-04-04 在我们学习python的过程中,学习序列是一门必修课。本文我们就来一起看一看Python是如何快速将变量插入有序数组的,感兴趣的可以了解一下2023-04-04
在我们学习python的过程中,学习序列是一门必修课。本文我们就来一起看一看Python是如何快速将变量插入有序数组的,感兴趣的可以了解一下2023-04-04 这篇文章主要为大家详细介绍了python判断设备是否联网的方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
这篇文章主要为大家详细介绍了python判断设备是否联网的方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06 有时候发微博时候,需要裁切图片为九宫格,但是ps或者其他工具都太麻烦。本文就来用Python编写一个一键切割九宫格的工具,希望对大家有所帮助2023-03-03
有时候发微博时候,需要裁切图片为九宫格,但是ps或者其他工具都太麻烦。本文就来用Python编写一个一键切割九宫格的工具,希望对大家有所帮助2023-03-03 这篇文章主要介绍了python 内置函数汇总详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了python 内置函数汇总详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09 本文主要介绍了Python字符串常规操作小结,如拼接字符串、截取字符串、格式化字符串等,下面将对Python中常用字符串操作方法进行介绍,感兴趣的可以了解一下2022-04-04
本文主要介绍了Python字符串常规操作小结,如拼接字符串、截取字符串、格式化字符串等,下面将对Python中常用字符串操作方法进行介绍,感兴趣的可以了解一下2022-04-04 今天小编就为大家分享一篇Python读写docx文件的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇Python读写docx文件的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 本文主要介绍如何利用Springboot框架调用python脚本,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-12-12
本文主要介绍如何利用Springboot框架调用python脚本,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-12-12
python GUI编程(Tkinter) 创建子窗口及在窗口上用图片绘图实例
这篇文章主要介绍了python GUI编程(Tkinter) 创建子窗口及在窗口上用图片绘图实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03










最新评论