
.NET做人脸识别并分类的实现示例
在游乐场、玻璃天桥、滑雪场等娱乐场所,经常能看到有摄影师在拍照片,令这些经营者发愁的一件事就是照片太多了,客户在成千上万张照片中找到自己可不是件容易的事。在一次游玩等活动或家庭聚会也同理,太多了照片导致挑选十分困难。
还好有.NET,只需少量代码,即可轻松找到人脸并完成分类。
本文将使用Microsoft Azure云提供的认知服务(Cognitive Services)API来识别并进行人脸分类,可以免费使用,注册地址是:https://portal.azure.com。注册完成后,会得到两个密钥,通过这个密钥即可完成本文中的所有代码,这个密钥长这个样子(非真实密钥):
fa3a7bfd807ccd6b17cf559ad584cbaa
使用方法
首先安装NuGet包Microsoft.Azure.CognitiveServices.Vision.Face,目前最新版是2.5.0-preview.1,然后创建一个FaceClient:
string key = "fa3a7bfd807ccd6b17cf559ad584cbaa"; // 替换为你的key
using var fc = new FaceClient(new ApiKeyServiceClientCredentials(key))
{
Endpoint = "https://southeastasia.api.cognitive.microsoft.com",
};
然后识别一张照片:
using var file = File.OpenRead(@"C:\Photos\DSC_996ICU.JPG"); IList<DetectedFace> faces = await fc.Face.DetectWithStreamAsync(file);
其中返回的faces是一个IList结构,很显然一次可以识别出多个人脸,其中一个示例返回结果如下(已转换为JSON):
[
{
"FaceId": "9997b64e-6e62-4424-88b5-f4780d3767c6",
"RecognitionModel": null,
"FaceRectangle": {
"Width": 174,
"Height": 174,
"Left": 62,
"Top": 559
},
"FaceLandmarks": null,
"FaceAttributes": null
},
{
"FaceId": "8793b251-8cc8-45c5-ab68-e7c9064c4cfd",
"RecognitionModel": null,
"FaceRectangle": {
"Width": 152,
"Height": 152,
"Left": 775,
"Top": 580
},
"FaceLandmarks": null,
"FaceAttributes": null
}
]
可见,该照片返回了两个DetectedFace对象,它用FaceId保存了其Id,用于后续的识别,用FaceRectangle保存了其人脸的位置信息,可供对其做进一步操作。RecognitionModel、FaceLandmarks、FaceAttributes是一些额外属性,包括识别性别、年龄、表情等信息,默认不识别,如下图API所示,可以通过各种参数配置,非常好玩,有兴趣的可以试试:

最后,通过.GroupAsync来将之前识别出的多个faceId进行分类:
var faceIds = faces.Select(x => x.FaceId.Value).ToList(); GroupResult reslut = await fc.Face.GroupAsync(faceIds);
返回了一个GroupResult,其对象定义如下:
public class GroupResult
{
public IList<IList<Guid>> Groups
{
get;
set;
}
public IList<Guid> MessyGroup
{
get;
set;
}
// ...
}
包含了一个Groups对象和一个MessyGroup对象,其中Groups是一个数据的数据,用于存放人脸的分组,MessyGroup用于保存未能找到分组的FaceId。
有了这个,就可以通过一小段简短的代码,将不同的人脸组,分别复制对应的文件夹中:
void CopyGroup(string outputPath, GroupResult result, Dictionary<Guid, (string file, DetectedFace face)> faces)
{
foreach (var item in result.Groups
.SelectMany((group, index) => group.Select(v => (faceId: v, index)))
.Select(x => (info: faces[x.faceId], i: x.index + 1)).Dump())
{
string dir = Path.Combine(outputPath, item.i.ToString());
Directory.CreateDirectory(dir);
File.Copy(item.info.file, Path.Combine(dir, Path.GetFileName(item.info.file)), overwrite: true);
}
string messyFolder = Path.Combine(outputPath, "messy");
Directory.CreateDirectory(messyFolder);
foreach (var file in result.MessyGroup.Select(x => faces[x].file).Distinct())
{
File.Copy(file, Path.Combine(messyFolder, Path.GetFileName(file)), overwrite: true);
}
}
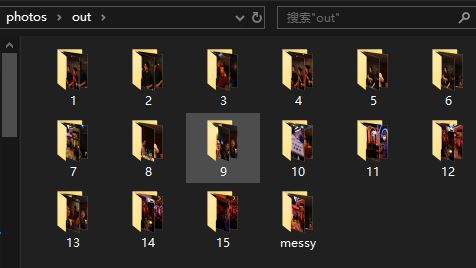
然后就能得到运行结果,如图,我传入了102张照片,输出了15个分组和一个“未找到队友”的分组:
还能有什么问题?
就两个API调用而已,代码一把梭,感觉太简单了?其实不然,还会有很多问题。
图片太大,需要压缩
毕竟要把图片上传到云服务中,如果上传网速不佳,流量会挺大,而且现在的手机、单反、微单都能轻松达到好几千万像素,jpg大小轻松上10MB,如果不压缩就上传,一来流量和速度遭不住。
二来……其实Azure也不支持,文档(https://docs.microsoft.com/en-us/rest/api/cognitiveservices/face/face/detectwithstream)显示,最大仅支持6MB的图片,且图片大小应不大于1920x1080的分辨率:
- JPEG, PNG, GIF (the first frame), and BMP format are supported. The allowed image file size is from 1KB to 6MB.
- The minimum detectable face size is 36x36 pixels in an image no larger than 1920x1080 pixels. Images with dimensions higher than 1920x1080 pixels will need a proportionally larger minimum face size.
因此,如果图片太大,必须进行一定的压缩(当然如果图片太小,显然也没必要进行压缩了),使用.NET的Bitmap,并结合C# 8.0的switch expression,这个判断逻辑以及压缩代码可以一气呵成:
byte[] CompressImage(string image, int edgeLimit = 1920)
{
using var bmp = Bitmap.FromFile(image);
using var resized = (1.0 * Math.Max(bmp.Width, bmp.Height) / edgeLimit) switch
{
var x when x > 1 => new Bitmap(bmp, new Size((int)(bmp.Size.Width / x), (int)(bmp.Size.Height / x))),
_ => bmp,
};
using var ms = new MemoryStream();
resized.Save(ms, ImageFormat.Jpeg);
return ms.ToArray();
}
竖立的照片
相机一般都是3:2的传感器,拍出来的照片一般都是横向的。但偶尔寻求一些构图的时候,我们也会选择纵向构图。虽然现在许多API都支持正负30度的侧脸,但竖着的脸API基本都是不支持的,如下图(实在找不到可以授权使用照片的模特了😂):

还好照片在拍摄后,都会保留exif信息,只需读取exif信息并对照片做相应的旋转即可:
void HandleOrientation(Image image, PropertyItem[] propertyItems)
{
const int exifOrientationId = 0x112;
PropertyItem orientationProp = propertyItems.FirstOrDefault(i => i.Id == exifOrientationId);
if (orientationProp == null) return;
int val = BitConverter.ToUInt16(orientationProp.Value, 0);
RotateFlipType rotateFlipType = val switch
{
2 => RotateFlipType.RotateNoneFlipX,
3 => RotateFlipType.Rotate180FlipNone,
4 => RotateFlipType.Rotate180FlipX,
5 => RotateFlipType.Rotate90FlipX,
6 => RotateFlipType.Rotate90FlipNone,
7 => RotateFlipType.Rotate270FlipX,
8 => RotateFlipType.Rotate270FlipNone,
_ => RotateFlipType.RotateNoneFlipNone,
};
if (rotateFlipType != RotateFlipType.RotateNoneFlipNone)
{
image.RotateFlip(rotateFlipType);
}
}
旋转后,我的照片如下:

这样竖拍的照片也能识别出来了。
并行速度
前文说过,一个文件夹可能会有成千上万个文件,一个个上传识别,速度可能慢了点,它的代码可能长这个样子:
Dictionary<Guid, (string file, DetectedFace face)> faces = GetFiles(inFolder)
.Select(file =>
{
byte[] bytes = CompressImage(file);
var result = (file, faces: fc.Face.DetectWithStreamAsync(new MemoryStream(bytes)).GetAwaiter().GetResult());
(result.faces.Count == 0 ? $"{file} not detect any face!!!" : $"{file} detected {result.faces.Count}.").Dump();
return (file, faces: result.faces.ToList());
})
.SelectMany(x => x.faces.Select(face => (x.file, face)))
.ToDictionary(x => x.face.FaceId.Value, x => (file: x.file, face: x.face));
要想把速度变化,可以启用并行上传,有了C#/.NET的LINQ支持,只需加一行.AsParallel()即可完成:
Dictionary<Guid, (string file, DetectedFace face)> faces = GetFiles(inFolder)
.AsParallel() // 加的就是这行代码
.Select(file =>
{
byte[] bytes = CompressImage(file);
var result = (file, faces: fc.Face.DetectWithStreamAsync(new MemoryStream(bytes)).GetAwaiter().GetResult());
(result.faces.Count == 0 ? $"{file} not detect any face!!!" : $"{file} detected {result.faces.Count}.").Dump();
return (file, faces: result.faces.ToList());
})
.SelectMany(x => x.faces.Select(face => (x.file, face)))
.ToDictionary(x => x.face.FaceId.Value, x => (file: x.file, face: x.face));
断点续传
也如上文所说,有成千上万张照片,如果一旦网络传输异常,或者打翻了桌子上的咖啡(谁知道呢?)……或者完全一切正常,只是想再做一些其它的分析,所有东西又要重新开始。我们可以加入下载中常说的“断点续传”机制。
其实就是一个缓存,记录每个文件读取的结果,然后下次运行时先从缓存中读取即可,缓存到一个json文件中:
Dictionary<Guid, (string file, DetectedFace face)> faces = GetFiles(inFolder)
.AsParallel() // 加的就是这行代码
.Select(file =>
{
byte[] bytes = CompressImage(file);
var result = (file, faces: fc.Face.DetectWithStreamAsync(new MemoryStream(bytes)).GetAwaiter().GetResult());
(result.faces.Count == 0 ? $"{file} not detect any face!!!" : $"{file} detected {result.faces.Count}.").Dump();
return (file, faces: result.faces.ToList());
})
.SelectMany(x => x.faces.Select(face => (x.file, face)))
.ToDictionary(x => x.face.FaceId.Value, x => (file: x.file, face: x.face));
注意代码下方有一个lock关键字,是为了保证多线程下载时的线程安全。
使用时,只需只需在Select中添加一行代码即可:
var cache = new Cache<List<DetectedFace>>(); // 重点
Dictionary<Guid, (string file, DetectedFace face)> faces = GetFiles(inFolder)
.AsParallel()
.Select(file => (file: file, faces: cache.GetOrCreate(file, () => // 重点
{
byte[] bytes = CompressImage(file);
var result = (file, faces: fc.Face.DetectWithStreamAsync(new MemoryStream(bytes)).GetAwaiter().GetResult());
(result.faces.Count == 0 ? $"{file} not detect any face!!!" : $"{file} detected {result.faces.Count}.").Dump();
return result.faces.ToList();
})))
.SelectMany(x => x.faces.Select(face => (x.file, face)))
.ToDictionary(x => x.face.FaceId.Value, x => (file: x.file, face: x.face));
将人脸框起来
照片太多,如果活动很大,或者合影中有好几十个人,分出来的组,将长这个样子:

完全不知道自己的脸在哪,因此需要将检测到的脸框起来。
注意框起来的过程,也很有技巧,回忆一下,上传时的照片本来就是压缩和旋转过的,因此返回的DetectedFace对象值,它也是压缩和旋转过的,如果不进行压缩和旋转,找到的脸的位置会完全不正确,因此需要将之前的计算过程重新演算一次:
using var bmp = Bitmap.FromFile(item.info.file);
HandleOrientation(bmp, bmp.PropertyItems);
using (var g = Graphics.FromImage(bmp))
{
using var brush = new SolidBrush(Color.Red);
using var pen = new Pen(brush, 5.0f);
var rect = item.info.face.FaceRectangle;
float scale = Math.Max(1.0f, (float)(1.0 * Math.Max(bmp.Width, bmp.Height) / 1920.0));
g.ScaleTransform(scale, scale);
g.DrawRectangle(pen, new Rectangle(rect.Left, rect.Top, rect.Width, rect.Height));
}
bmp.Save(Path.Combine(dir, Path.GetFileName(item.info.file)));
使用我上面的那张照片,检测结果如下(有点像相机对焦时人脸识别的感觉):

1000个脸的限制
.GroupAsync方法一次只能检测1000个FaceId,而上次活动800多张照片中有超过2000个FaceId,因此需要做一些必要的分组。
分组最简单的方法,就是使用System.Interactive包,它提供了Rx.NET那样方便快捷的API(这些API在LINQ中未提供),但又不需要引入Observable<T>那样重量级的东西,因此使用起来很方便。
这里我使用的是.Buffer(int)函数,它可以将IEnumerable<T>按指定的数量(如1000)进行分组,代码如下:
foreach (var buffer in faces
.Buffer(1000)
.Select((list, groupId) => (list, groupId))
{
GroupResult group = await fc.Face.GroupAsync(buffer.list.Select(x => x.Key).ToList());
var folder = outFolder + @"\gid-" + buffer.groupId;
CopyGroup(folder, group, faces);
}
总结
文中用到的完整代码,全部上传了到我的博客数据Github,只要输入图片和key,即可直接使用和运行:
https://github.com/sdcb/blog-data/tree/master/2019/20191122-dotnet-face-detection
这个月我参加了上海的.NET Conf,我上述代码对.NET Conf的800多张照片做了分组,识别出了2000多张人脸,我将其中我的照片的前三张找出来,结果如下:



......
总的来说,这个效果还挺不错,渣渣分辨率的照片的脸都被它找到了😂。
注意,不一定非得用Azure Cognitive Services来做人脸识别,国内还有阿里云等厂商也提供了人脸识别等服务,并提供了.NET接口,无非就是调用API,注意其限制,代码总体差不多。
另外,如有离线人脸识别需求,Luxand提供了还有离线版人脸识别SDK,名叫Luxand FaceSDK,同样提供了.NET接口。因为无需网络调用,其识别更快,匹配速度更是可达每秒5千万个人脸数据,精度也非常高,亲测好用,目前最新版是v7.1.0,授权昂贵(但百度有惊喜)。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
- opencv 做人脸识别 opencv 人脸匹配分析
- 基于OpenCV的PHP图像人脸识别技术
- Android camera实时预览 实时处理,人脸识别示例
- python实现人脸识别经典算法(一) 特征脸法
- JavaScript人脸识别技术及脸部识别JavaScript类库Tracking.js
- android实现人脸识别技术的示例代码
- 微信小程序实现人脸识别
- PHP使用Face++接口开发微信公众平台人脸识别系统的方法
- 人脸识别经典算法一 特征脸方法(Eigenface)
- python3+dlib实现人脸识别和情绪分析
- 详解如何用OpenCV + Python 实现人脸识别
- Python3结合Dlib实现人脸识别和剪切
相关文章
 ashx中获取session值的方法,大家参考使用吧2013-12-12
ashx中获取session值的方法,大家参考使用吧2013-12-12 .net6有自带的logging组件,还有很多优秀的开源log组件,如NLog,serilog,这里我们使用serilog组件来构建日志模块,这篇文章主要介绍了如何在.Net6 web api中记录每次接口请求的日志,需要的朋友可以参考下2023-06-06
.net6有自带的logging组件,还有很多优秀的开源log组件,如NLog,serilog,这里我们使用serilog组件来构建日志模块,这篇文章主要介绍了如何在.Net6 web api中记录每次接口请求的日志,需要的朋友可以参考下2023-06-06 js 父页单选按钮取值函数2008-12-12
js 父页单选按钮取值函数2008-12-12 asp.net下利用JS实现对后台CS代码的调用方法...2007-04-04
asp.net下利用JS实现对后台CS代码的调用方法...2007-04-04 这篇文章介绍了ASP.NET MVC获取多级类别组合下产品的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09
这篇文章介绍了ASP.NET MVC获取多级类别组合下产品的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09 ASP.NET 图片加水印防盗链实现代码,需要的朋友可以参考下。2011-12-12
ASP.NET 图片加水印防盗链实现代码,需要的朋友可以参考下。2011-12-12 获取字符串中汉字原理是判断汉字编码然后进行判断是汉字还是数字了,还有就是利用正则表达式,同样是以汉字ascii为标准来获取2014-02-02
获取字符串中汉字原理是判断汉字编码然后进行判断是汉字还是数字了,还有就是利用正则表达式,同样是以汉字ascii为标准来获取2014-02-02 一直以来,我都在思考,一些繁琐的操作,比如我们一般的管理后台,很多都是数据的添加、修改与删除,列表的操作,而且一般我们都是用.aspx文件去做的。2009-04-04
一直以来,我都在思考,一些繁琐的操作,比如我们一般的管理后台,很多都是数据的添加、修改与删除,列表的操作,而且一般我们都是用.aspx文件去做的。2009-04-04 本文详细讲解了.Net反向代理组件Yarp的用法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09
本文详细讲解了.Net反向代理组件Yarp的用法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09 本文详细讲解了在.NET MAUI应用中配置应用生命周期事件的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-03-03
本文详细讲解了在.NET MAUI应用中配置应用生命周期事件的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-03-03










最新评论