
Pytorch实现LSTM和GRU示例
为了解决传统RNN无法长时依赖问题,RNN的两个变体LSTM和GRU被引入。
LSTM
Long Short Term Memory,称为长短期记忆网络,意思就是长的短时记忆,其解决的仍然是短时记忆问题,这种短时记忆比较长,能一定程度上解决长时依赖。
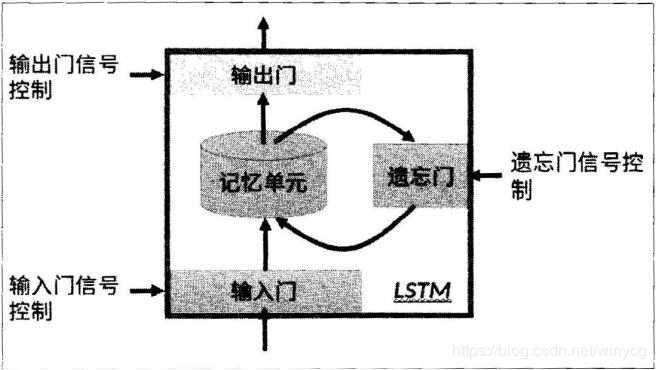
上图为LSTM的抽象结构,LSTM由3个门来控制,分别是输入门、遗忘门和输出门。输入门控制网络的输入,遗忘门控制着记忆单元,输出门控制着网络的输出。最为重要的就是遗忘门,可以决定哪些记忆被保留,由于遗忘门的作用,使得LSTM具有长时记忆的功能。对于给定的任务,遗忘门能够自主学习保留多少之前的记忆,网络能够自主学习。
具体看LSTM单元的内部结构:
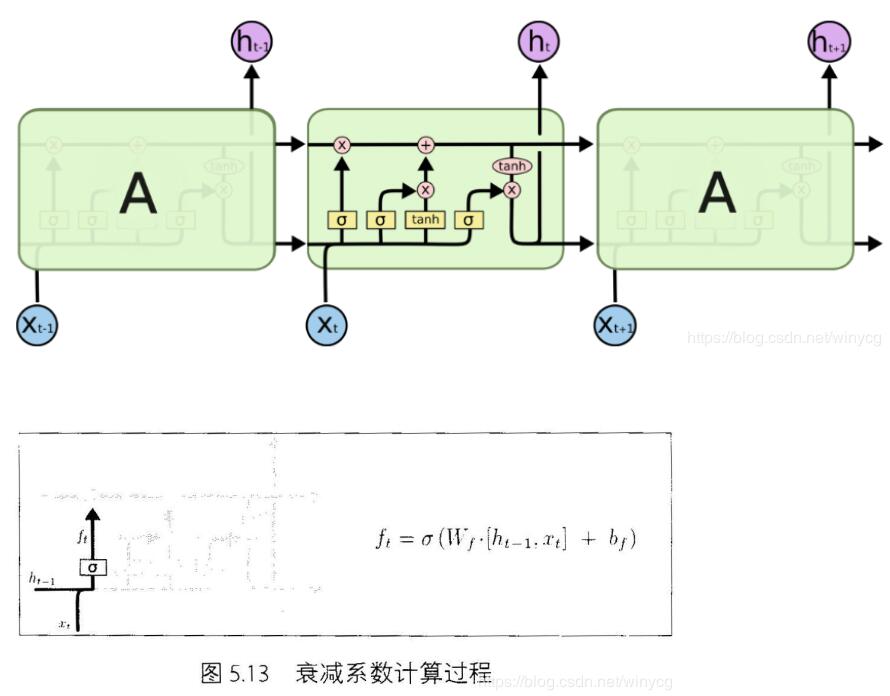

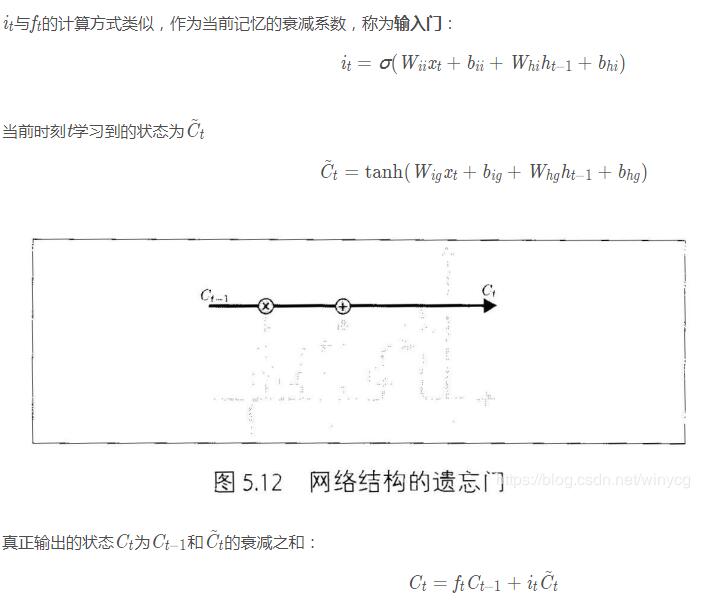
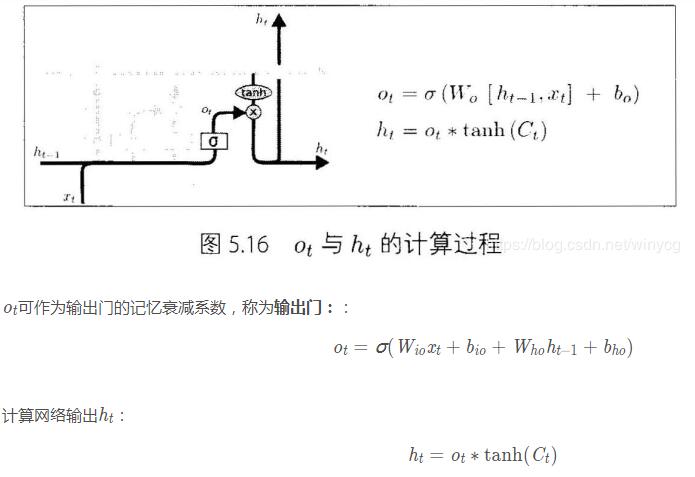
在每篇文章中,作者都会使用和标准LSTM稍微不同的版本,针对特定的任务,特定的网络结构往往表现更好。
GRU

上述的过程的线性变换没有使用偏置。隐藏状态参数不再是标准RNN的4倍,而是3倍,也就是GRU的参数要比LSTM的参数量要少,但是性能差不多。
Pytorch
在Pytorch中使用nn.LSTM()可调用,参数和RNN的参数相同。具体介绍LSTM的输入和输出:
输入: input, (h_0, c_0)
input:输入数据with维度(seq_len,batch,input_size)
h_0:维度为(num_layers*num_directions,batch,hidden_size),在batch中的
初始的隐藏状态.
c_0:初始的单元状态,维度与h_0相同
输出:output, (h_n, c_n)
output:维度为(seq_len, batch, num_directions * hidden_size)。
h_n:最后时刻的输出隐藏状态,维度为 (num_layers * num_directions, batch, hidden_size)
c_n:最后时刻的输出单元状态,维度与h_n相同。
LSTM的变量:

以MNIST分类为例实现LSTM分类
MNIST图片大小为28×28,可以将每张图片看做是长为28的序列,序列中每个元素的特征维度为28。将最后输出的隐藏状态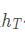 作为抽象的隐藏特征输入到全连接层进行分类。最后输出的
作为抽象的隐藏特征输入到全连接层进行分类。最后输出的
导入头文件:
import torch import torch.nn as nn import torch.optim as optim import torchvision from torchvision import transforms
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_classes):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
self.classifier = nn.Linear(hidden_dim, n_classes)
def forward(self, x):
out, (h_n, c_n) = self.lstm(x)
# 此时可以从out中获得最终输出的状态h
# x = out[:, -1, :]
x = h_n[-1, :, :]
x = self.classifier(x)
return x
训练和测试代码:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
net = Rnn(28, 10, 2, 10)
net = net.to('cpu')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
# Training
def train(epoch):
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
optimizer.zero_grad()
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
def test(epoch):
global best_acc
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
for epoch in range(200):
train(epoch)
test(epoch)
以上这篇Pytorch实现LSTM和GRU示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段,下面这篇文章主要给大家介绍了关于python语法教程之def()函数定义及用法的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-01-01
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段,下面这篇文章主要给大家介绍了关于python语法教程之def()函数定义及用法的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2023-01-01 这篇文章主要为大家详细介绍了python+pygame实现坦克大战,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09
这篇文章主要为大家详细介绍了python+pygame实现坦克大战,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09 这篇文章主要介绍了如何用python 批量操作redis数据库,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了如何用python 批量操作redis数据库,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03 这篇文章主要介绍了Django路由层URLconf作用及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09
这篇文章主要介绍了Django路由层URLconf作用及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-09-09
Python爬虫库BeautifulSoup的介绍与简单使用实例
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,本文为大家介绍下Python爬虫库BeautifulSoup的介绍与简单使用实例其中包括了,BeautifulSoup解析HTML,BeautifulSoup获取内容,BeautifulSoup节点操作,BeautifulSoup获取CSS属性等实例2020-01-01 在图像处理领域,背景移除是一个常见且重要的任务,Python中的rembg库就是一个强大的工具,它基于深度学习技术,能够准确、快速地移除图像背景,本文将结合多个实际案例,详细介绍rembg库的安装、基本用法、高级功能以及在实际项目中的应用,需要的朋友可以参考下2024-09-09
在图像处理领域,背景移除是一个常见且重要的任务,Python中的rembg库就是一个强大的工具,它基于深度学习技术,能够准确、快速地移除图像背景,本文将结合多个实际案例,详细介绍rembg库的安装、基本用法、高级功能以及在实际项目中的应用,需要的朋友可以参考下2024-09-09
Python运行报错UnicodeDecodeError的解决方法
本文给大家分享的是在Python项目中经常遇到的关于编码问题的一个小bug的解决方法以及分析方法,有相同遭遇的小伙伴可以来参考下2016-06-06 这篇文章主要介绍了Python3.7安装pyaudio教程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了Python3.7安装pyaudio教程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
Python Numpy运行报错:IndexError: too many in
在使用Numpy进行数组操作时,经常会遇到各种错误,其中,IndexError: too many indices for array是一种常见的错误,它通常发生在尝试使用一个过多维度的索引来访问一个较低维度的数组时,本文介绍了Python Numpy报错的解决办法,需要的朋友可以参考下2024-07-07 这篇文章主要介绍了Python爬虫之requests基础用法详解,虽然Python的标准库中urllib模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人感觉不太友好,而requests库使用更简洁方便,需要的朋友可以参考下2023-10-10
这篇文章主要介绍了Python爬虫之requests基础用法详解,虽然Python的标准库中urllib模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人感觉不太友好,而requests库使用更简洁方便,需要的朋友可以参考下2023-10-10










最新评论