
Python基于requests库爬取网站信息
更新时间:2020年03月02日 11:15:14 作者:江武555
这篇文章主要介绍了python基于requests库爬取网站信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
requests库是一个简介且简单的处理HTTP请求的第三方库
get()是获取网页最常用的方式,其基本使用方式如下
使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML
下面这段代码便是爬取百度的信息并简单输出百度的界面信息
import requests
from bs4 import BeautifulSoup
r=requests.get('http://www.baidu.com')
r.encoding=None
result=r.text
bs=BeautifulSoup(result,'html.parser')
print(bs.title)
print(bs.title.text)
import requests
from bs4 import BeautifulSoup
#用来解决乱码现象,所以编写爬取信息的代码最好带上(输出出现乱码或者UnicodeEncodeError:'gbk'codec can't encode character)
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
#用来防止反爬取,可以了解一下
headers={"User-Agent" : "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.6)",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "en-us",
"Connection" : "keep-alive",
"Accept-Charset" : "GB2312,utf-8;q=0.7,*;q=0.7"
}
#获取51job网站的基本信息
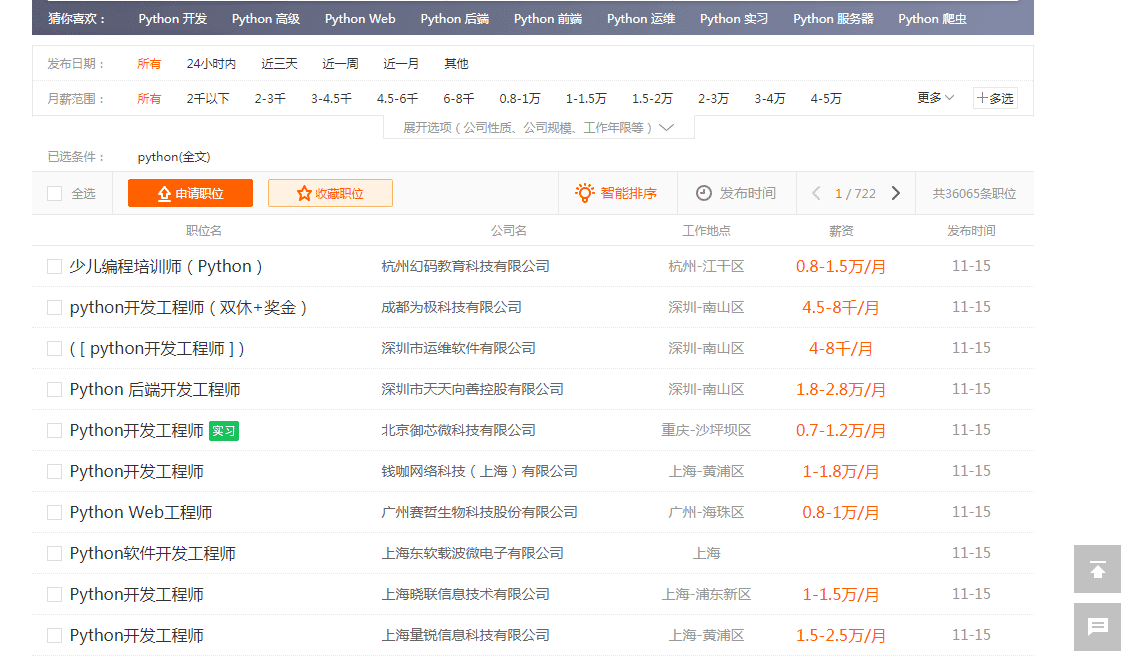
r=requests.get('https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=')
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser')
print(bs.prettify())
u1=bs.find_all('u1',attrs={'class':'item_con_list'}) #这部分代码便是我们爬取的目标,51job网站上关于python职业的薪资
print(len(u1))
li=bs.find_all('span',attrs={'class':'t4'})
for l in li:
print(l.text)
上面这段代码便是爬取51job网站上的与python相关职业的薪资

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要为大家详细介绍了Python如何利用Tkinter编写一个RGB数值转换为16进制码的小工具,文中的示例代讲解详细,感兴趣的小伙伴可以了解一下2023-01-01
这篇文章主要为大家详细介绍了Python如何利用Tkinter编写一个RGB数值转换为16进制码的小工具,文中的示例代讲解详细,感兴趣的小伙伴可以了解一下2023-01-01 年年双十一,年年抢不到,今年小编自制Python淘宝秒杀抢购脚本,百分百中,下面小编把我的实现思路分享给大家,有兴趣的朋友借鉴下吧2021-11-11
年年双十一,年年抢不到,今年小编自制Python淘宝秒杀抢购脚本,百分百中,下面小编把我的实现思路分享给大家,有兴趣的朋友借鉴下吧2021-11-11 我们整理了一篇关于引入Python文件的一个基础知识点内容,如果你是一个python的学习者,参考一下吧。2018-12-12
我们整理了一篇关于引入Python文件的一个基础知识点内容,如果你是一个python的学习者,参考一下吧。2018-12-12 今天小编就为大家分享一篇python 实现矩阵上下/左右翻转,转置的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇python 实现矩阵上下/左右翻转,转置的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 这篇文章主要为大家介绍了python计算机视觉opencv卡号识别的实现示例详解,有需要的朋友可以借鉴参考下 希望能够有所帮助,祝大家多多进步2021-11-11
这篇文章主要为大家介绍了python计算机视觉opencv卡号识别的实现示例详解,有需要的朋友可以借鉴参考下 希望能够有所帮助,祝大家多多进步2021-11-11 在使用Flask编写后端接口时,如果设置的接口返回格式是JSON,可能会遇到中文编码问题,这篇文章主要介绍了json中文编码问题的相关资料,需要的朋友可以参考下2025-03-03
在使用Flask编写后端接口时,如果设置的接口返回格式是JSON,可能会遇到中文编码问题,这篇文章主要介绍了json中文编码问题的相关资料,需要的朋友可以参考下2025-03-03 LyScript插件中提供了三种基本的堆栈操作方法,其中push_stack用于入栈,pop_stack用于出栈,peek_stac可用于检查指定堆栈位置处的内存参数。所以本文将利用这一特性实现对内存堆栈扫描,感兴趣的可以了解一下2022-08-08
LyScript插件中提供了三种基本的堆栈操作方法,其中push_stack用于入栈,pop_stack用于出栈,peek_stac可用于检查指定堆栈位置处的内存参数。所以本文将利用这一特性实现对内存堆栈扫描,感兴趣的可以了解一下2022-08-08 本文主要接好了python接口自动化的接口概念、接口用例设计及登录,跟随本文章来进行一个接口用例设计及登录接口测试实战,有需要的朋友可以参考下2021-08-08
本文主要接好了python接口自动化的接口概念、接口用例设计及登录,跟随本文章来进行一个接口用例设计及登录接口测试实战,有需要的朋友可以参考下2021-08-08 这篇文章主要介绍了Python模块对Redis数据库的连接与使用,通过实例代码给大家介绍了Python连接Redis数据库方法,Python使用连接池连接Redis数据库方法,感兴趣的朋友跟随小编一起看看吧2021-07-07
这篇文章主要介绍了Python模块对Redis数据库的连接与使用,通过实例代码给大家介绍了Python连接Redis数据库方法,Python使用连接池连接Redis数据库方法,感兴趣的朋友跟随小编一起看看吧2021-07-07 这篇文章主要为大家详细介绍了python利用文件读写编写一个博客,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-08-08
这篇文章主要为大家详细介绍了python利用文件读写编写一个博客,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-08-08










最新评论