
Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码
更新时间:2020年05月28日 09:22:50 作者:smart_num_1
这篇文章主要介绍了Python selenium 加载并保存QQ群成员 去除其群主、管理员信息的示例代码,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧
一位伙计自己开了个游戏室,想在群里拉点人,就用所学知识帮帮忙,于是就有了这篇文章,今天小编特此通过实例代码给大家介绍下Python selenium 加载并保存QQ群成员去除其群主、管理员信息的示例代码
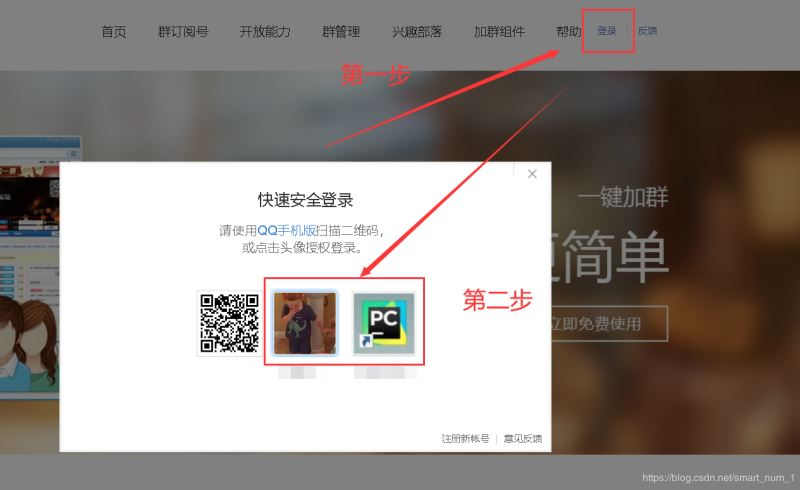
模拟登陆页面
页面分析
思路:
点击登陆按钮
选择要登陆的账号
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def login(driver = None):
already_dic = {}
# 创建一个字典,保存电脑登陆的QQ
login_button = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//p[@class="user-info"]/a')))
login_button.click()
# 点击登录,获取电脑登陆的QQ
already_login_number = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//div[@id="loginWin"]/iframe')))
driver.get(url = already_login_number.get_attribute('src'))
# 此步骤目的,是因为登录框是一个子页面,在上一级页面中获得到的这个子页面
already_login_numbers = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[contains(@class,"nick")]')))
# 获取电脑登陆的QQ
print('在以下账号中选择所需账号')
for already_login_number in already_login_numbers:
already_dic[already_login_number.get_attribute('innerText')] = already_login_number
print(already_login_number.get_attribute('innerText'))
QQ_NeedToLogin = input('需要登陆: ')
# 通过获取键名,在 already_dic 获得相应的键值
already_dic[QQ_NeedToLogin].click()
# 模拟点击要登陆的QQ,达到登陆的效果
time.sleep(1)
if __name__ == '__main__':
start_url = 'https://qun.qq.com/index.html#click'
# 群首页,用来登陆账号
driver = webdriver.Chrome(executable_path = './chromedriver.exe')
# 因为selenium 需要用到浏览器、浏览器驱动,但是还要配置环境变量,很麻烦,如果这样指定 webdriver 路径的话,就可以省去那一步
driver.get(url=start_url)
login(driver=driver)
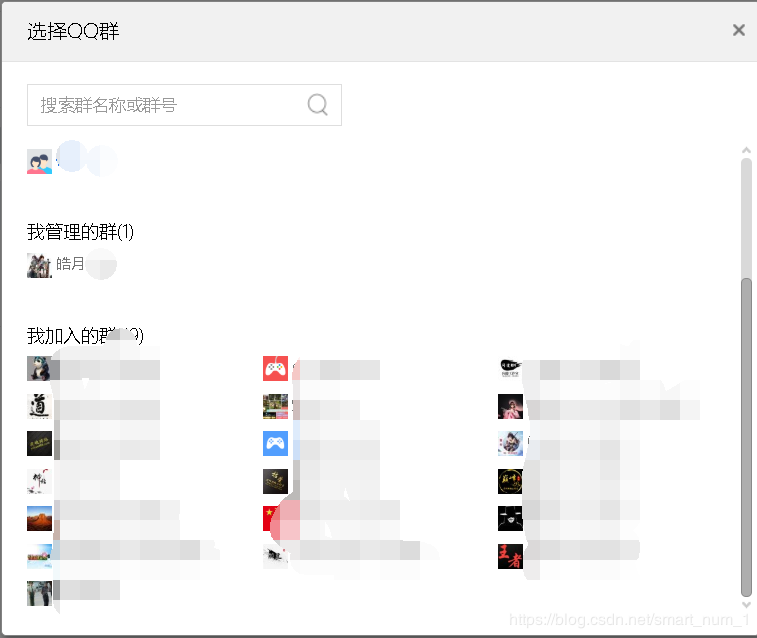
选择所需加载群
页面分析
打开群管理界面,会看到这样的信息,我们的目的是爬取已加入群的成员信息
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
def get_group_number(driver = None):
group_number_dic = {}
# 同样的,利用字典储存信息
my_group_list = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//ul[@class="my-group-list"]/li')))
# 获取每个已加入群的节点信息
print('在以下群中选择:')
i = 1
for my_group in my_group_list:
try:
group_number_dic[str(i)] = my_group
print('第 %s 个--- '%str(i) + my_group.get_attribute('title') + ' ' + my_group.get_attribute('data-id'))
i += 1
except:
continue
# 打印出获得的群信息,获取所有的目标群
group = input('获取群编号 : ')
# 通过键名获取键值,得到要点击的目标
group_number_dic[group].click()
return driver
if __name__ == '__main__':
member_url_test = 'https://qun.qq.com/member.html'
driver.get(url = member_url_test)
driver = get_group_number(driver=driver)
保存所需信息
页面分析
可以看到,是个动态加载的页面,因为用的是selenium,所以就没必要分析到底是通过请求那个url得到的信息,直接模拟滚动获取就可以了

代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
def get_group_member(driver = None):
driver.refresh()
# 刷新一下界面,防止上一步点击过后,页面不更新的情况
elem_end = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//td[@class="td-user-nick"]/img')))
# 添加了等待,这个定位可以随便的选择,确保页面加载完毕的
for i in range(10):
time.sleep(0.5)
driver.execute_script("var action=document.documentElement.scrollTop=10000")
print('加载中······')
# 这个滚动范围可以任选,因为每次会加载21个信息,我看过我加的群,在10次过后的成员基本属于潜水的人了,要不要的就无所谓了
group_members = driver.find_elements_by_xpath('//tr[contains(@class,"mb")]')
for group_member in group_members:
try:
data = group_member.text.split('\n')[2].split(' ')[0]
# 这一步,得到一个列表,从第一位开始分别是成员、群昵称、QQ号、性别、Q龄、入群时间、等级(积分)、最后发言,在这里我是只需要QQ号码
#对于其他信息,根据自己需要,添加代码即可
if data.isdigit() == True:
with open('./record.txt','a',encoding = 'utf-8') as record:
record.write(data + '@qq.com')
record.write('\n')
except:
continue
print('Loaded')
完整代码
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options
import time
import random
import os
def get_group_member(driver = None):
driver.refresh()
elem_end = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//td[@class="td-user-nick"]/img')))
for i in range(10):
time.sleep(0.5)
driver.execute_script("var action=document.documentElement.scrollTop=10000")
print('加载中······')
group_members = driver.find_elements_by_xpath('//tr[contains(@class,"mb")]')
for group_member in group_members:
try:
data = group_member.text.split('\n')[2].split(' ')[0]
if data.isdigit() == True:
with open('./record.txt','a',encoding = 'utf-8') as record:
record.write(data + '@qq.com')
record.write('\n')
except:
continue
print('Loaded')
def get_group_number(driver = None):
group_number_dic = {}
my_group_list = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//ul[@class="my-group-list"]/li')))
print('在以下群中选择:')
i = 1
for my_group in my_group_list:
try:
group_number_dic[str(i)] = my_group
print('第 %s 个--- '%str(i) + my_group.get_attribute('title') + ' ' + my_group.get_attribute('data-id'))
i += 1
except:
continue
group = input('获取群编号 : ')
group_number_dic[group].click()
return driver
def login(driver = None):
already_dic = {}
login_button = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//p[@class="user-info"]/a')))
login_button.click()
already_login_number = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//div[@id="loginWin"]/iframe')))
driver.get(url = already_login_number.get_attribute('src'))
already_login_numbers = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[contains(@class,"nick")]')))
print('在以下账号中选择所需账号')
for already_login_number in already_login_numbers:
already_dic[already_login_number.get_attribute('innerText')] = already_login_number
print(already_login_number.get_attribute('innerText'))
QQ_NeedToLogin = input('需要登陆: ')
already_dic[QQ_NeedToLogin].click()
time.sleep(1)
def start(driver = None,url = None):
print('Please wait for loading\n')
driver.get(url = url)
driver = get_group_number(driver=driver)
print('Please wait for loading\n')
get_group_member(driver=driver)
if __name__ == '__main__':
print('Please wait for loading')
chrome_options=Options()
chrome_options.add_argument('--headless')
try:
random.seed(time.time())
QQ_number = '738334209'
start_url = 'https://qun.qq.com/index.html#click'
member_url = 'https://qun.qq.com/member.html#gid=%s'%QQ_number
member_url_test = 'https://qun.qq.com/member.html'
driver = webdriver.Chrome(executable_path = './chromedriver.exe',chrome_options=chrome_options)
try:
driver.get(url=start_url)
login(driver=driver)
while True:
start(driver = driver,url = member_url_test)
flag = input('是否继续爬取? yes or no : ')
if flag == 'no':
break
os.system('cls')
driver.quit()
except:
print('Something wrong')
driver.quit()
except:
print('Something wrong!!!!!!')
os.system('pause')
转载请标明出处:https://blog.csdn.net/smart_num_1/article/details/106326488
总结
到此这篇关于Python selenium 加载并保存QQ群成员 去除其群主、管理员信息的示例代码的文章就介绍到这了,更多相关Python selenium 加载并保存QQ群成员内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 灰度变换是指根据某种目标条件按一定变换关系逐点改变源图像中每个像素灰度值的方法。目的是改善画质,使图像显示效果更加清晰。图像的灰度变换处理是图像增强处理技术中的一种非常基础、直接的空间域图像处理方法,也是图像数字化软件和图像显示软件的一个重要组成部分2022-10-10
灰度变换是指根据某种目标条件按一定变换关系逐点改变源图像中每个像素灰度值的方法。目的是改善画质,使图像显示效果更加清晰。图像的灰度变换处理是图像增强处理技术中的一种非常基础、直接的空间域图像处理方法,也是图像数字化软件和图像显示软件的一个重要组成部分2022-10-10 Python画图主要用到matplotlib这个库,具体来说是pylab和pyplot这两个子库,这两个库可以满足基本的画图需求,下面这篇文章主要给大家介绍了关于Python Matplotlib绘制条形图的相关资料,需要的朋友可以参考下2021-10-10
Python画图主要用到matplotlib这个库,具体来说是pylab和pyplot这两个子库,这两个库可以满足基本的画图需求,下面这篇文章主要给大家介绍了关于Python Matplotlib绘制条形图的相关资料,需要的朋友可以参考下2021-10-10 这篇文章主要介绍了wxPython窗口中文乱码解决方法,在Python程序设计中比较常见,是非常实用的技巧,需要的朋友可以参考下2014-10-10
这篇文章主要介绍了wxPython窗口中文乱码解决方法,在Python程序设计中比较常见,是非常实用的技巧,需要的朋友可以参考下2014-10-10 本篇文章通过python写一个获取python文件扩展名和文件名的功能,并分享了代码,有兴趣的参考下。2018-02-02
本篇文章通过python写一个获取python文件扩展名和文件名的功能,并分享了代码,有兴趣的参考下。2018-02-02 这篇文章主要介绍了Python list append方法如何给列表追加元素,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11
这篇文章主要介绍了Python list append方法如何给列表追加元素,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要介绍了Django框架 信号调度原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了Django框架 信号调度原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09 这篇文章主要介绍了python读取html中指定元素生成excle文件示例,需要的朋友可以参考下2014-04-04
这篇文章主要介绍了python读取html中指定元素生成excle文件示例,需要的朋友可以参考下2014-04-04 Windows PowerShell 由数十个内置 cmdlet 组成,它们提供了丰富的功能集,本文将重点讨论从 Python 代码执行 PowerShell 逻辑,感兴趣的朋友跟随小编一起看看吧2023-10-10
Windows PowerShell 由数十个内置 cmdlet 组成,它们提供了丰富的功能集,本文将重点讨论从 Python 代码执行 PowerShell 逻辑,感兴趣的朋友跟随小编一起看看吧2023-10-10 这篇文章主要介绍了Python 字符串、列表、元组的截取与切片操作,结合实例形式分析了Python针对字符串、列表、元组的截取与切片相关操作技巧,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了Python 字符串、列表、元组的截取与切片操作,结合实例形式分析了Python针对字符串、列表、元组的截取与切片相关操作技巧,需要的朋友可以参考下2019-09-09 这篇文章主要介绍了python线程join方法原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了python线程join方法原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02










最新评论