
基于Python快速处理PDF表格数据
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来。

使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下:
pip install pdfplumber
安装完之后,将需要使用的模块导入
import pdfplumberimport pandas as pd
然后打开PDF文件
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf:
# pages[0]表示取第1页
page = pdf.pages[0]
我们来打印输出下获取到的文本,这句语句只是帮我们验证下是否成功获取到PDF里的内容
print(page.extract_text())
执行的结果如下,看来是成功了

然后可以使用extract_table()函数获取表格,如果有多个表格,可以使用extract_tables()函数,就是多了个s
d1=page.extract_table()
执行代码后,将得到一个列表,还不是数据框
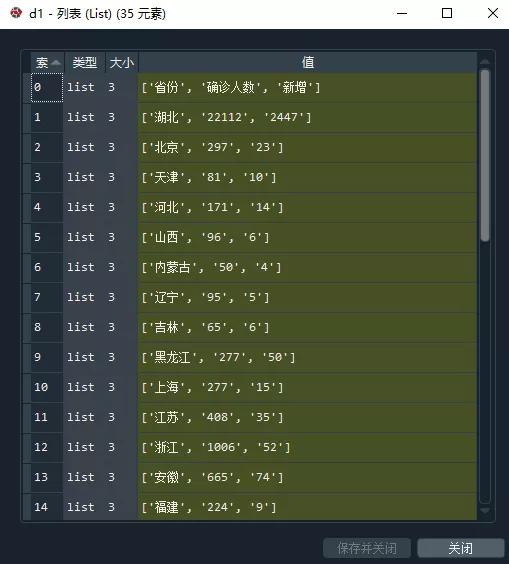
所以最后一步就是将列表转为数据框就可以了,代码如下:
df = pd.DataFrame(d1[1:], columns=d1[0])
执行代码后,将得到了df数据框

有几个注意事项要提醒下:
1.pdf表格中的数据,对于同一个数据或内容,不要有换行,如果换行,可能被识别为2个数据;
2.pdf中的表格一定要有边框,没有边框的话,否则使用extract_table()函数就无法获取表格数据,extract_text()还是可以获取文本信息的,不要问我是怎么知道的,说多了都是泪。
我们现在有一份PDF数据,里面有三页,每页都有一样数据结构但数据不同的数据表,现在需要使用Python将它批量提取出来。



有了上回经验,我们就直接上代码:
import pdfplumber
import pandas as pd
# 创建一个空数据框
df = pd.DataFrame()
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\5.pdf") as pdf:
# 使用for循环遍历每个pages
for page in pdf.pages:
# 取出当前页表格,结果为列表
d=page.extract_table()
# 将列表转为数据框
df1 = pd.DataFrame(d[1:], columns=d[0])
#添加至df数据框中
df = df.append(df1)
执行代码后,将得到了df数据框

是不是so easy 呢?
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了Python中pow()和math.pow()函数用法,结合具体实例形式分析了Python使用pow()和math.pow()函数进行幂运算的相关操作技巧,需要的朋友可以参考下2018-02-02
这篇文章主要介绍了Python中pow()和math.pow()函数用法,结合具体实例形式分析了Python使用pow()和math.pow()函数进行幂运算的相关操作技巧,需要的朋友可以参考下2018-02-02 这篇文章主要介绍了python3两数相加的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04
这篇文章主要介绍了python3两数相加的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-04-04 在本篇文章中小编给各位整理了一篇关于python中翻译功能translate模块实现方法,有需要的朋友们可以参考下。2020-12-12
在本篇文章中小编给各位整理了一篇关于python中翻译功能translate模块实现方法,有需要的朋友们可以参考下。2020-12-12 这篇文章主要介绍了Pytorch生成随机数Tensor的方法汇总,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09
这篇文章主要介绍了Pytorch生成随机数Tensor的方法汇总,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-09-09 在本篇文章里小编给大家整理了关于win10下python2和python3共存问题解决方法,有兴趣的朋友们参考下。2019-12-12
在本篇文章里小编给大家整理了关于win10下python2和python3共存问题解决方法,有兴趣的朋友们参考下。2019-12-12
如何使用python的ctypes调用医保中心的dll动态库下载医保中心的账单
这篇文章主要介绍了如何使用python的ctypes调用医保中心的dll动态库下载医保中心的账单,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-05-05 这篇文章主要为大家详细介绍了Python中的对象拷贝和内存布局的相关知识,文中的示例代码讲解详细,对我们学习Python有一定的帮助,需要的可以参考一下2022-12-12
这篇文章主要为大家详细介绍了Python中的对象拷贝和内存布局的相关知识,文中的示例代码讲解详细,对我们学习Python有一定的帮助,需要的可以参考一下2022-12-12
Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题
这篇文章主要介绍了Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-02-02 这篇文章主要教大家用python画一个玫瑰和一个爱心,作为女生节礼物,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08
这篇文章主要教大家用python画一个玫瑰和一个爱心,作为女生节礼物,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08 这篇文章主要介绍了Python编程实现控制cmd命令行显示颜色的方法,结合实例形式分析了Python针对命令行字符串显示颜色属性相关操作技巧,需要的朋友可以参考下2017-08-08
这篇文章主要介绍了Python编程实现控制cmd命令行显示颜色的方法,结合实例形式分析了Python针对命令行字符串显示颜色属性相关操作技巧,需要的朋友可以参考下2017-08-08










最新评论