
ol7.7安装部署4节点spark3.0.0分布式集群的详细教程
更新时间:2020年07月10日 11:42:30 作者:九命猫幺
这篇文章主要介绍了安装部署4节点spark3.0.0分布式集群,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包
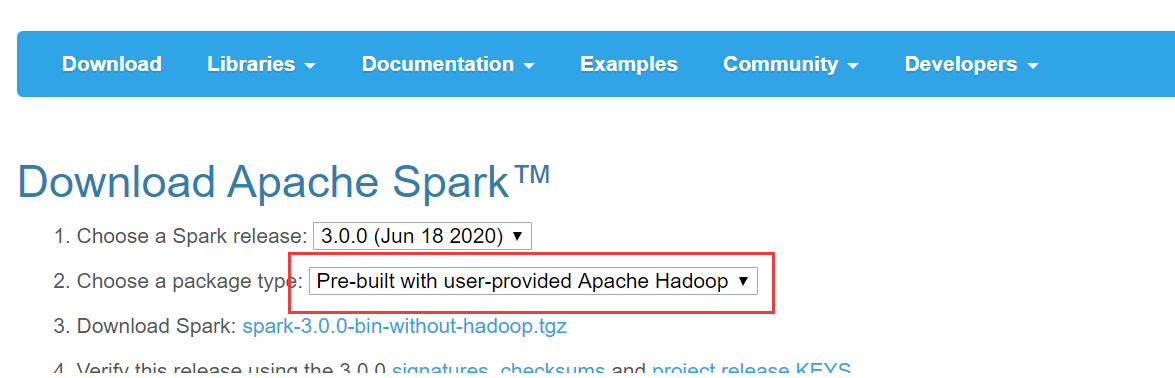
解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群
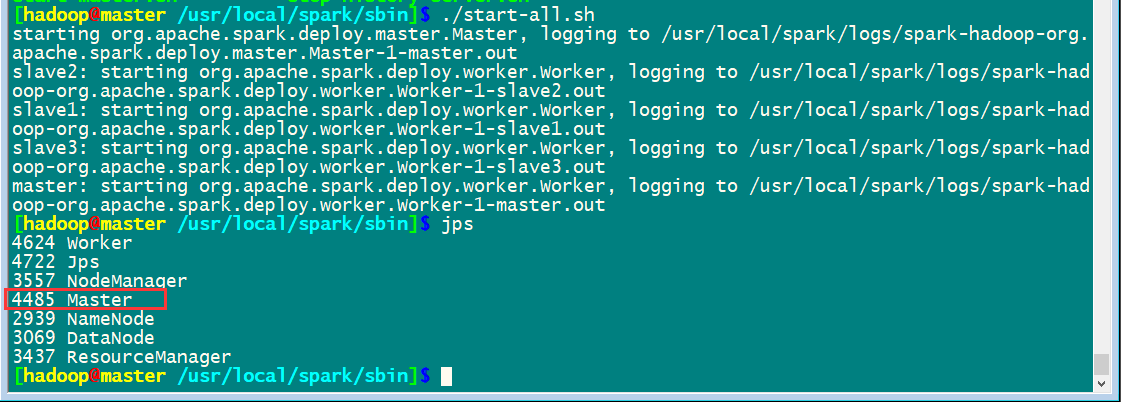
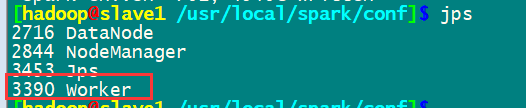
通过master8080端口监控
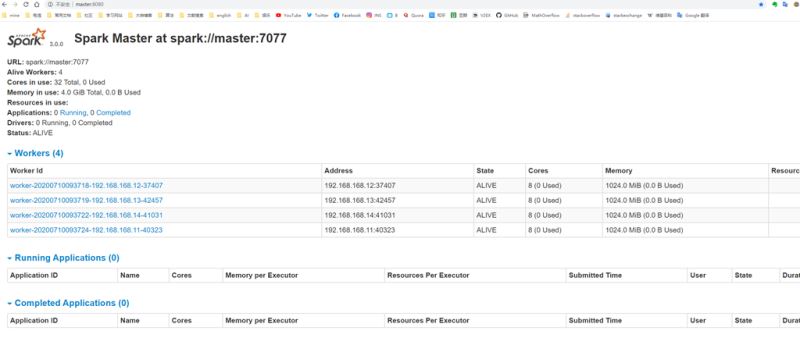
完成安装
到此这篇关于ol7.7安装部署4节点spark3.0.0分布式集群的详细教程的文章就介绍到这了,更多相关ol7.7安装部署spark集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了OAuth 2.0授权协议详解,本文对OAuth协议做了详解讲解,对OAuth协议的各个方面做了分解,读完本文你就会知道到底啥是OAuth了,需要的朋友可以参考下2014-09-09
这篇文章主要介绍了OAuth 2.0授权协议详解,本文对OAuth协议做了详解讲解,对OAuth协议的各个方面做了分解,读完本文你就会知道到底啥是OAuth了,需要的朋友可以参考下2014-09-09
Win10中Dreamweaver等软件界面字太小的问题解决
最近发现Win10系统中Dreamweaver等软件界面字太小,所以下面这篇文章主要给大家介绍了关于Win10中Dreamweaver等软件界面字太小的问题解决办法,文中通过图文介绍的非常详细,需要的朋友可以参考下2007-10-10 AERGO SHIP:用于开发智能合约的包管理器,用于构建、测试和部署分布式应用程序的客户端框架和开发环境2018-11-11
AERGO SHIP:用于开发智能合约的包管理器,用于构建、测试和部署分布式应用程序的客户端框架和开发环境2018-11-11
Deepseek R1模型本地化部署+API接口调用详细教程(释放AI生产力)
本文介绍了本地部署DeepSeekR1模型和通过API调用将其集成到VSCode中的过程,作者详细步骤展示了如何下载和部署DeepSeekR1模型,并提供了解决下载问题的建议,最后,作者解释了如何在VSCode中使用Cline插件调用DeepSeekAPI,以实现智能编码辅助,感兴趣的朋友一起看看吧2025-02-02
解决使用IDE Run运行出错package pack/test is not in GOROOT (/usr/loca
这篇文章主要介绍了解决使用IDE Run运行出错package pack/test is not in GOROOT (/usr/local/go/src/pack/test),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-11-11 多种语言下获取当前页完整URL及其参数...2007-04-04
多种语言下获取当前页完整URL及其参数...2007-04-04 这篇文章主要介绍了Flyway数据库版本控制的教程,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2015-07-07
这篇文章主要介绍了Flyway数据库版本控制的教程,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2015-07-07 这篇文章主要介绍了ToDesk安装与使用教程,ToDesk非常好用而且是全平台支持,喜欢的朋友跟随小编一起看看吧2024-08-08
这篇文章主要介绍了ToDesk安装与使用教程,ToDesk非常好用而且是全平台支持,喜欢的朋友跟随小编一起看看吧2024-08-08 大家被新型冠状病毒搞的人心慌慌,每天宅在家里那也去不了,今天小编给大家分享2019-nCoV 全国新型肺炎疫情每日动态趋势可视图,需要的朋友可以参考下2020-02-02
大家被新型冠状病毒搞的人心慌慌,每天宅在家里那也去不了,今天小编给大家分享2019-nCoV 全国新型肺炎疫情每日动态趋势可视图,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了resty的1.2.0-SNAPSHOT版本更新,可以通过header控制api的版本实现数据源读写分离,有需要的朋友可以借鉴参考下,希望能够有所帮助<BR>,2022-03-03
这篇文章主要介绍了resty的1.2.0-SNAPSHOT版本更新,可以通过header控制api的版本实现数据源读写分离,有需要的朋友可以借鉴参考下,希望能够有所帮助<BR>,2022-03-03










最新评论