
Java爬虫技术框架之Heritrix框架详解
Heritrix是一个由Java开发的开源Web爬虫系统,用来获取完整的、精确的站点内容的深度复制,
具有强大的可扩展性,运行开发者任意选择或扩展各个组件,实现特定的抓取逻辑。
一、Heritrix介绍
Heritrix采用了模块化的设计,用户可以在运行时选择要用的模块。它由核心类(core classes)和插件模块(pluggable modules)构成。
核心类可以配置,但不能被覆盖,插件模块可以由第三方模块取代。所以我们就可以用实现了特定抓取逻辑的第三方模块来取代默认的插件模块,从而满足自己的抓取需要。
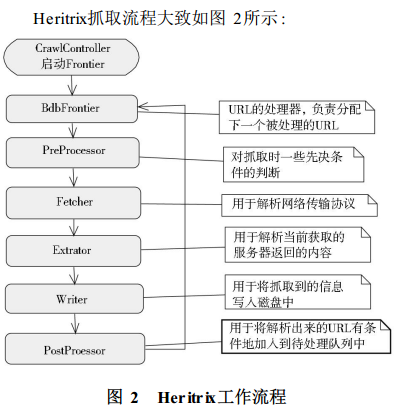
CrawlController(下载控制器)整个下载过程的总控制者,整个抓取工作的起点,决定整个抓取任务的开始和结束。每个URI都有一个独立的线程,它从边界控制器(Frontier)获取新的URI,然后传递给Processor chains(处理链)经过一系列Processor(处理器)处理。

二、Heritrix架构
中央控制器 CrawlController 是核心组件,决定了整个抓取任务的开始与结束。
用户在 Heritrix web UI 控制台设置抓取任务后,heritrix首先构造XMLSettingsHandler对象,然后调用CrawlController的构造函数,构造一个CrawlController实例并初始化,这样,CrawlController就具备了运行条件。
此时,只需调用 requestCrawlStart()方法就可以启动线程池和Frontier,以便向线程池中工作线程提供抓取用的URL链接。
Heritrix 3.x 的框架主要分为 Engine 和 Component
三、一些API
org.archive.crawler.framework.CrawlJob;
org.archive.crawler.postprocessor.CandidatesProcessor;
org.archive.modules.CrawlURI;
等等
抓取任务CrawlOrder类:是整个抓取工作的起点。一次抓取任务包括许多属性,建立一个任务的方式有很多种,最简单的一种就是根据默认的order.xml来配置。
中央控制器CrawlController:该类决定着抓取任务的开始和结束。它包含以下几个组件:
CrawlOrder:该类保存了order.xml的属性配置;
CrawlScope:决定当前抓取范围;
ProcessorChainList:处理器链;
Frontier:一次抓取任务需要设定一个Frontier,以此来不断为其每个线程提供URI;
ToePool:它是一个线程池,管理了所有在当前任务中抓取过的Host名称和Server名称。
中央控制器CrawlControllr的类结构如图所示:

Frontier链接制造工厂:它表示一种为线程提供链接的工具,通过一些特定的算法来决定哪个链接将接下来被送入处理器链中,同时,它本身也负责一定的日志和状态报告功能。
BdbFrontier类:它是用Berkeley DB 实现的,Berkeley DB 就是一个HashTable,它能够按“key/value”方式保存数据,能够为应用程序提供可伸缩的、高性能的、有事务保护功能的嵌入式数据库。
Heritrix的多线程ToeThread和ToePool:要想更快更有效地抓取网页,必须采用多线程,Heritrix则采用多线程机制,提供了一个标准的线程池ToePool,用于管理所有的抓取线程。
处理器链 Processor:包括PreProcessor、Fetcher、Extractor、Writer、PostProcessor五种。
四、应用
作为爬虫模块,爬取数据

到此这篇关于爬虫技术框架之Heritrix框架详解的文章就介绍到这了,更多相关爬虫技术框架 Heritrix内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
- Python爬虫实例——scrapy框架爬取拉勾网招聘信息
- Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
- Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
- Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
- Python爬虫框架scrapy实现的文件下载功能示例
- python爬虫框架scrapy实现模拟登录操作示例
- Python爬虫框架Scrapy常用命令总结
- Python爬虫框架Scrapy基本用法入门教程
- Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
- Python爬虫框架Scrapy实例代码
相关文章
 本节介绍 Python 中的另一个常用模块 —— statistics模块,该模块提供了用于计算数字数据的数理统计量的函数。这篇文章重点给大家介绍python statistics 模块的一些用法,感兴趣的朋友跟随小编一起看看吧2019-10-10
本节介绍 Python 中的另一个常用模块 —— statistics模块,该模块提供了用于计算数字数据的数理统计量的函数。这篇文章重点给大家介绍python statistics 模块的一些用法,感兴趣的朋友跟随小编一起看看吧2019-10-10 这篇文章主要介绍了OpenCV4.1.0+VS2017环境配置的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
这篇文章主要介绍了OpenCV4.1.0+VS2017环境配置的方法步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07 这篇文章主要介绍了Python项目跨域问题解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了Python项目跨域问题解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06 这篇文章主要给大家介绍在 cpython 当中一些比较花里胡哨的魔术方法,以帮助我们自己实现比较花哨的功能,当然这其中也包含一些也非常实用的魔术方法,需要的可以参考下2023-05-05
这篇文章主要给大家介绍在 cpython 当中一些比较花里胡哨的魔术方法,以帮助我们自己实现比较花哨的功能,当然这其中也包含一些也非常实用的魔术方法,需要的可以参考下2023-05-05 这篇文章主要介绍了详解python读取邮件数据并下载附件的实例的相关资料,这里提供实现实例,帮助大家学习理解这部分内容,需要的朋友可以参考下2017-08-08
这篇文章主要介绍了详解python读取邮件数据并下载附件的实例的相关资料,这里提供实现实例,帮助大家学习理解这部分内容,需要的朋友可以参考下2017-08-08 这篇文章主要介绍了Python变量的赋值、浅拷贝和深拷贝详解,python中为声明一个变量有三种方法:赋值、浅拷贝、深拷贝,相信每个pythoner或多或少都知道他们之间的区别,但在某些点上,还是会踩坑,这篇文章记录下所有关于这三者区别的疑问,需要的朋友可以参考下2023-11-11
这篇文章主要介绍了Python变量的赋值、浅拷贝和深拷贝详解,python中为声明一个变量有三种方法:赋值、浅拷贝、深拷贝,相信每个pythoner或多或少都知道他们之间的区别,但在某些点上,还是会踩坑,这篇文章记录下所有关于这三者区别的疑问,需要的朋友可以参考下2023-11-11 这篇文章主要介绍了Python SVM(支持向量机)实现方法,结合完整实例形式分析了基于Python实现向量机SVM算法的具体步骤与相关操作注意事项,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了Python SVM(支持向量机)实现方法,结合完整实例形式分析了基于Python实现向量机SVM算法的具体步骤与相关操作注意事项,需要的朋友可以参考下2018-06-06 这篇文章主要为大家详细介绍了python爬取网页转换为PDF文件,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
这篇文章主要为大家详细介绍了python爬取网页转换为PDF文件,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
Python通过Manager方式实现多个无关联进程共享数据的实现
这篇文章主要介绍了Python通过Manager方式实现多个无关联进程共享数据的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-11-11
对Python中DataFrame选择某列值为XX的行实例详解
今天小编就为大家分享一篇对Python中DataFrame选择某列值为XX的行实例详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01










最新评论