
Python lxml库的简单介绍及基本使用讲解
更新时间:2020年12月22日 14:59:21 作者:pinuscembra
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据,本文重点给大家介绍Python lxml库的简单介绍及基本使用讲解,感兴趣的朋友跟随小编一起看看吧
1.lxml库介绍
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观
XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容
2.安装lxml方法
方法1:
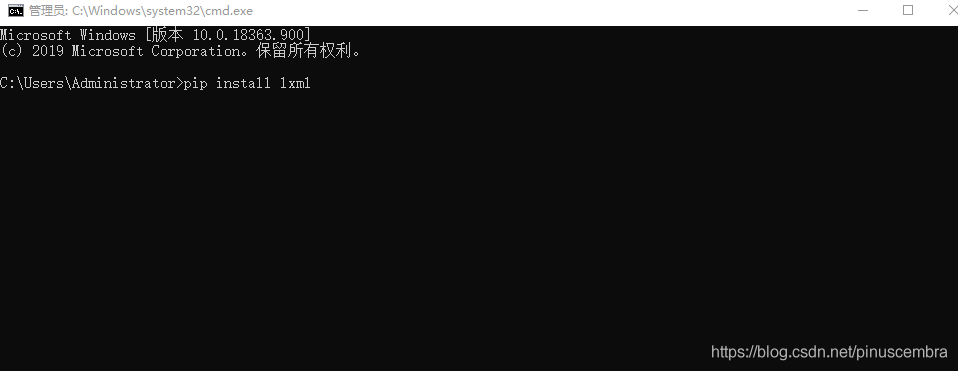
在cmd运行窗口中输入:pip install lxml
方法2:
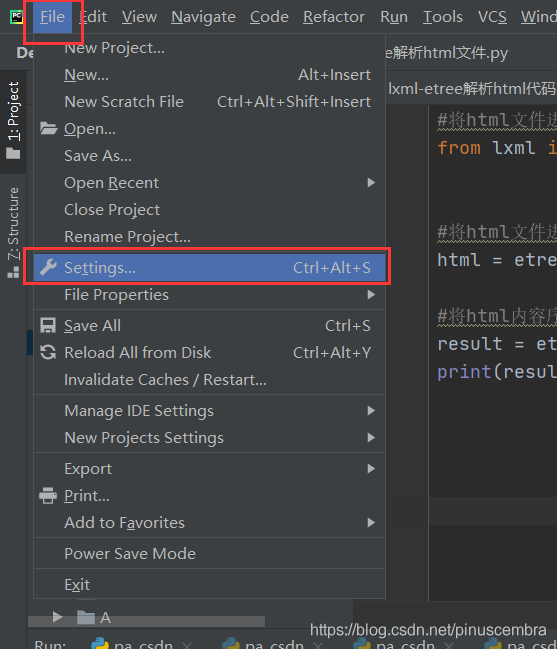
在Pycharm中下载
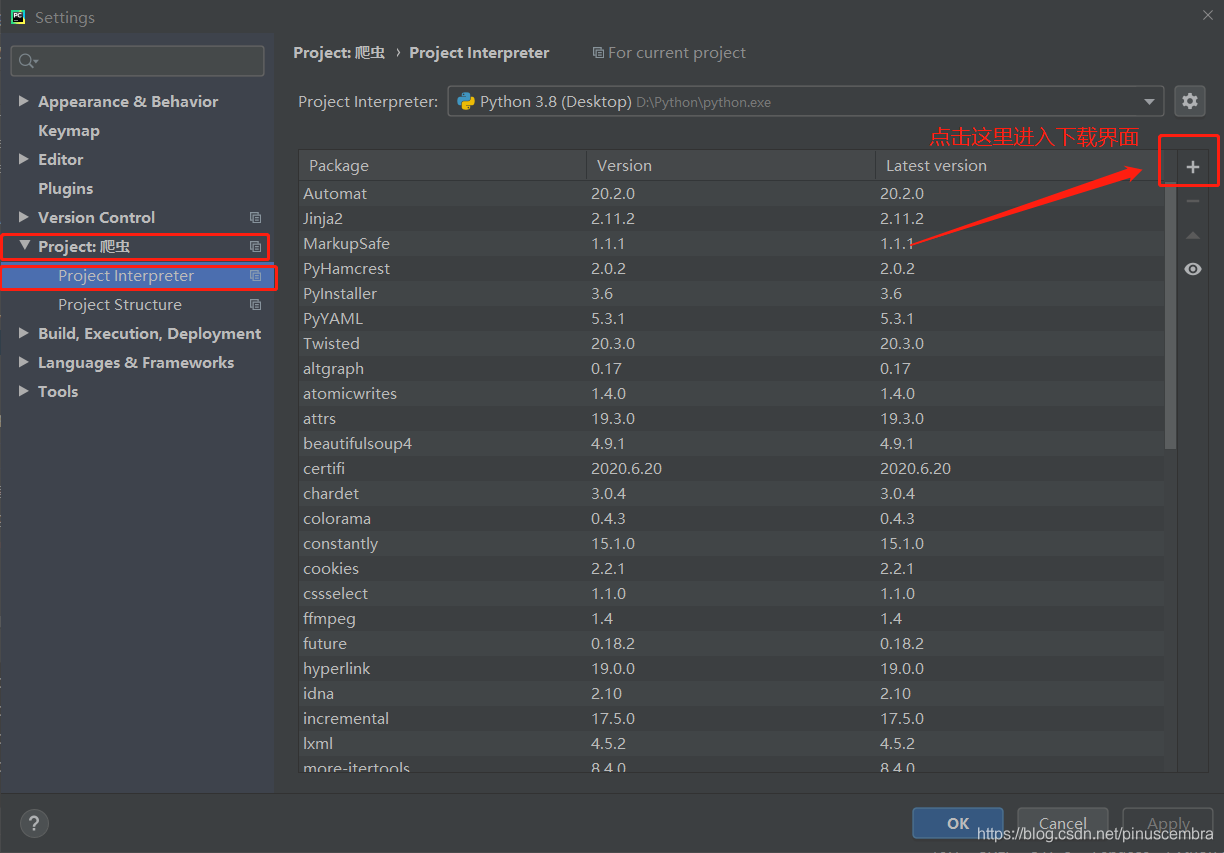
File–Setting–Project–Project Interpreter–点击右上角的“+”—
第1步
第2步
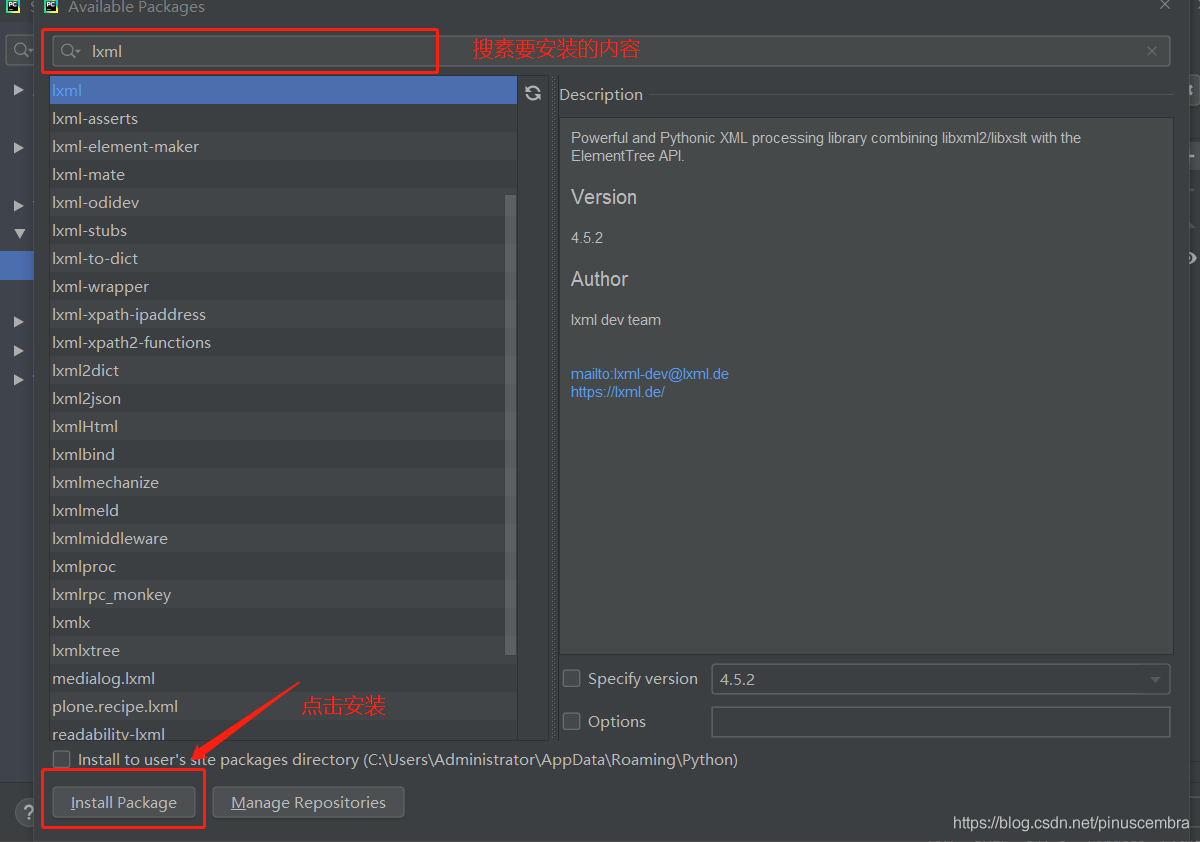
第3步
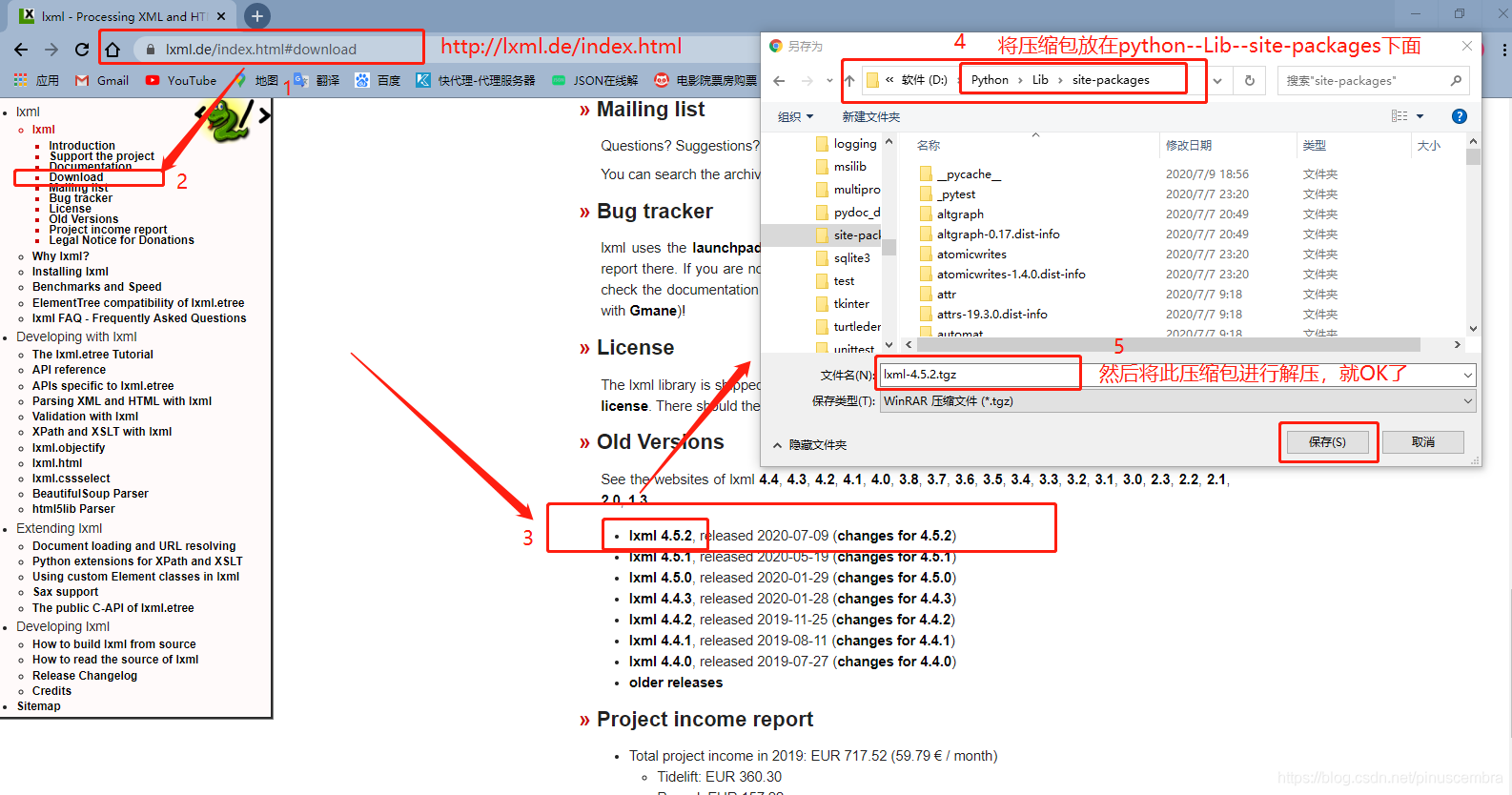
方法3:
进入这个网站进行下载:https://lxml.de/index.html
3.基本使用
我们可以利用他解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范或者不完整,lxml解析器会自动修复或补全代码,从而提高效率
实例1:
解析HTML代码块
#提取html中的数据
from lxml import etree
text = '''
<html>
<div class="clearfix">
<div class="nav_com">
<ul>
<li class="active"><a href="/" rel="external nofollow" >推荐</a></li>
<li class=""><a href="/nav/python" rel="external nofollow" >Python</a></li>
<li class=""><a href="/nav/java" rel="external nofollow" >Java</a></li>
<li class=""><a href="/nav/web" rel="external nofollow" >前端</a></li>
<li class=""><a href="/nav/arch" rel="external nofollow" >架构</a></li>
<li class=""><a href="/nav/db" rel="external nofollow" >数据库</a></li>
<li class=""><a href="/nav/5g" rel="external nofollow" >5G</a></li>
<li class=""><a href="/nav/game" rel="external nofollow" >游戏开发</a></li>
<li class=""><a href="/nav/mobile" rel="external nofollow" >移动开发</a></li>
<li class=""><a href="/nav/ops" rel="external nofollow" >运维</a></li>
</ul>
</div>
</div>
</html>>
</html>>
'''
#将字符串解析为html文档
html = etree.HTML(text)
#print(html)
#将字符串序列化为html
result = etree.tostring(html).decode('utf-8')
print(result)
实例2:
读取并解析html文件
#将html文件进行解析
from lxml import etree
#将html文件进行读取
html = etree.parse('data.html')
#将html内容序列化
result = etree.tostring(html).decode('utf-8')
print(result)
到此这篇关于Python lxml库的简单介绍及基本使用讲解的文章就介绍到这了,更多相关Python lxml库使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了举例详解Python中的split()函数的使用方法,split()函数的使用是Python学习当中的基础知识,通常用于将字符串切片并转换为列表,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了举例详解Python中的split()函数的使用方法,split()函数的使用是Python学习当中的基础知识,通常用于将字符串切片并转换为列表,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了利用python3 的pygame模块实现塔防游戏,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了利用python3 的pygame模块实现塔防游戏,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12 PycURl是一个C语言写的libcurl的python绑定库。libcurl 是一个自由的,并且容易使用的用在客户端的 URL 传输库。它的功能很强大,PycURL 是一个非常快速(参考多并发操作)和丰富完整特性的,但是有点复杂的接口。2018-04-04
PycURl是一个C语言写的libcurl的python绑定库。libcurl 是一个自由的,并且容易使用的用在客户端的 URL 传输库。它的功能很强大,PycURL 是一个非常快速(参考多并发操作)和丰富完整特性的,但是有点复杂的接口。2018-04-04
Python threading Local()函数用法案例详解
这篇文章主要介绍了Python threading Local()函数用法案例详解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-09-09
pytorch中获取模型input/output shape实例
今天小编就为大家分享一篇pytorch中获取模型input/output shape实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 今天小编就为大家分享一篇利用Python实现手机短信监控通知的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
今天小编就为大家分享一篇利用Python实现手机短信监控通知的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
tf.nn.conv2d与tf.layers.conv2d的区别及说明
这篇文章主要介绍了tf.nn.conv2d与tf.layers.conv2d的区别及说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了python中squeeze的超详细解释,squeeze操作用于去除张量或数组中大小为1的维度,简化数据结构,在PyTorch和NumPy中都有类似的功能,需要的朋友可以参考下2025-03-03
这篇文章主要介绍了python中squeeze的超详细解释,squeeze操作用于去除张量或数组中大小为1的维度,简化数据结构,在PyTorch和NumPy中都有类似的功能,需要的朋友可以参考下2025-03-03 现在大家都知道,比较火的编程语言就是python了,很多朋友都想学习python编程,想上一个好的python培训班,小编今天给大家全面分析一下关于python编程培训方面的问题,希望能给你答疑解惑。2018-01-01
现在大家都知道,比较火的编程语言就是python了,很多朋友都想学习python编程,想上一个好的python培训班,小编今天给大家全面分析一下关于python编程培训方面的问题,希望能给你答疑解惑。2018-01-01 下面小编就为大家分享一篇python 实现在Excel末尾增加新行,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
下面小编就为大家分享一篇python 实现在Excel末尾增加新行,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05










最新评论