
python+selenium爬取微博热搜存入Mysql的实现方法
更新时间:2021年01月27日 11:45:00 作者:也曾rgnxhw
这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
最终的效果
废话不多少,直接上图
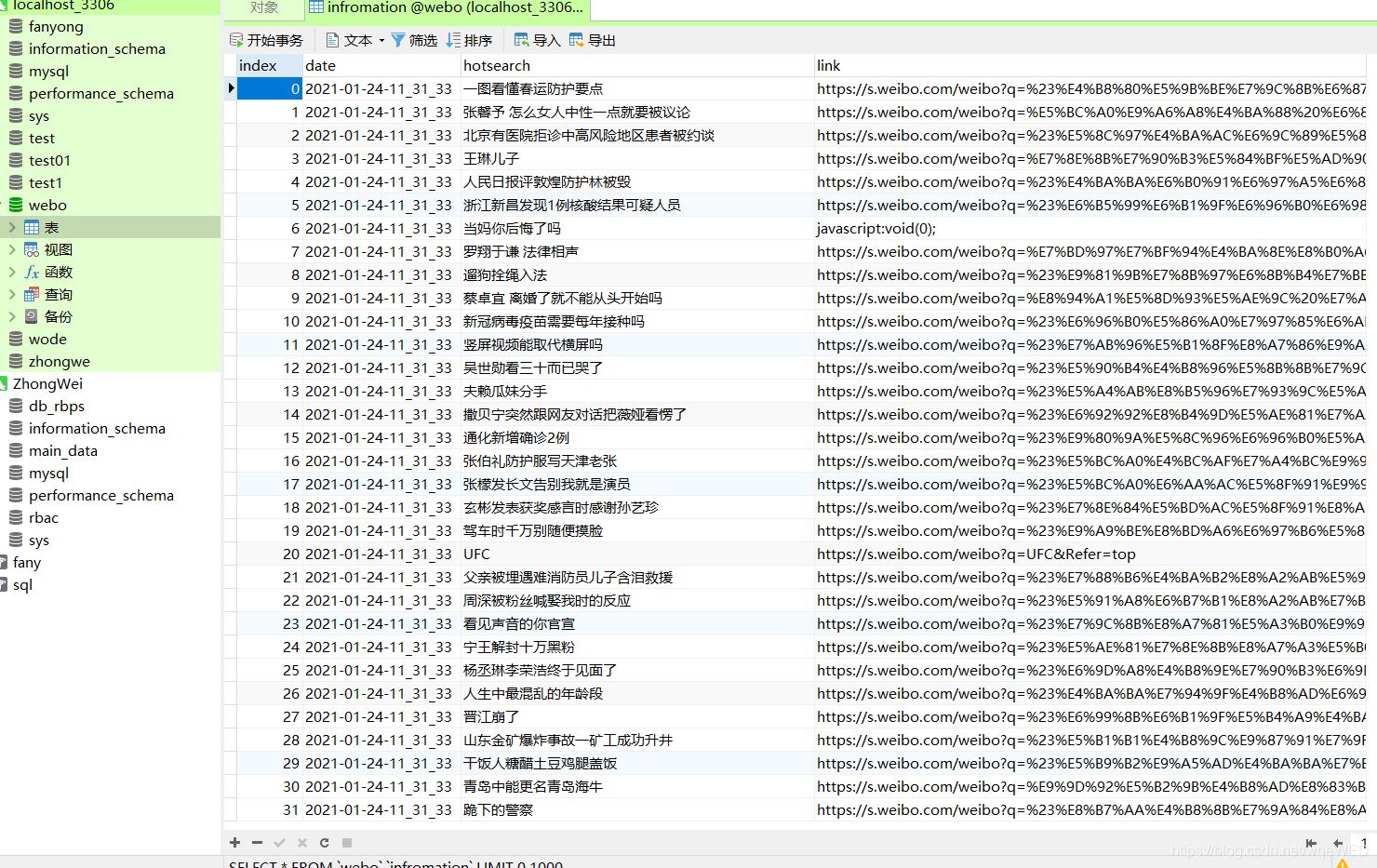
这里可以清楚的看到,数据库里包含了日期,内容,和网站link
下面我们来分析怎么实现
使用的库
import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
目标分析
这是微博热搜的link:点我可以到目标网页

首先我们使用selenium对目标网页进行请求
然后我们使用xpath对网页元素进行定位,遍历获得所有数据
然后使用pandas生成一个Dataframe对像,直接存入数据库
一:得到数据
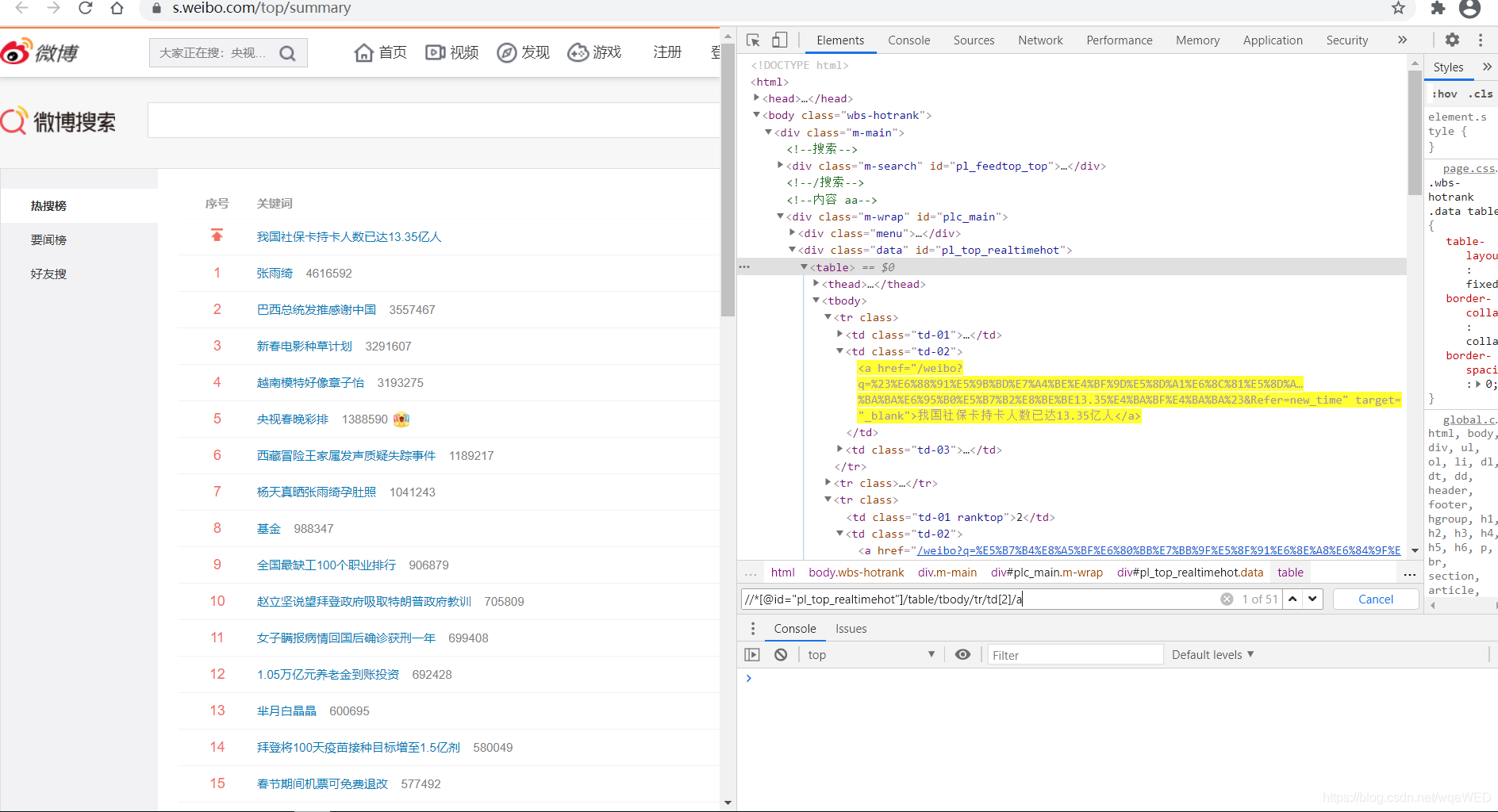
我们看到,使用xpath可以得到51条数据,这就是各热搜,从中我们可以拿到链接和标题内容
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link
然后我们再使用zip函数,将date,context,links合并
zip函数是将几个列表合成一个列表,并且按index对分列表的数据合并成一个元组,这个可以生产pandas对象。
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
其中date可以使用time模块获得
二:链接数据库
这个很容易
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
总代码
from selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx)
到此这篇关于python+selenium爬取微博热搜存入Mysql的实现方法的文章就介绍到这了,更多相关python selenium爬取微博热搜存入Mysql内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 venv 是 Python 里的一个标准工具,它的主要功能是帮助用户管理和控制虚拟环境,venv 的使用方法其实非常简单,下面我将详细介绍如何创建虚拟环境,如何激活虚拟环境,以及如何退出虚拟环境的操作步骤,需要的朋友可以参考下2024-03-03
venv 是 Python 里的一个标准工具,它的主要功能是帮助用户管理和控制虚拟环境,venv 的使用方法其实非常简单,下面我将详细介绍如何创建虚拟环境,如何激活虚拟环境,以及如何退出虚拟环境的操作步骤,需要的朋友可以参考下2024-03-03 LruCache 是 Android 的一个内部类,提供了基于内存实现的缓存,而下面这篇文章主要给大家介绍了关于LRUCache的实现原理以及利用python实现的方法,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。2017-11-11
LruCache 是 Android 的一个内部类,提供了基于内存实现的缓存,而下面这篇文章主要给大家介绍了关于LRUCache的实现原理以及利用python实现的方法,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧。2017-11-11 PDF文件是我们在日常工作和学习中常用的文档格式之一,但你知道吗,你可以将PDF文件转换为图像,让文档变得更加生动有趣,下面我们就来看看具体的实现方法吧2023-08-08
PDF文件是我们在日常工作和学习中常用的文档格式之一,但你知道吗,你可以将PDF文件转换为图像,让文档变得更加生动有趣,下面我们就来看看具体的实现方法吧2023-08-08 这篇文章主要介绍了Python通过len函数返回对象长度,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了Python通过len函数返回对象长度,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-10-10 python列表与元组详解实例,本文是基于python2.x的讲解,这点一定要注意。2013-11-11
python列表与元组详解实例,本文是基于python2.x的讲解,这点一定要注意。2013-11-11 这篇文章主要介绍了Pycharm如何自动生成头文件注释,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11
这篇文章主要介绍了Pycharm如何自动生成头文件注释,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-11-11 这篇文章主要介绍了Python中zip()函数用法实例教程,对Python初学者有一定的借鉴价值,需要的朋友可以参考下2014-07-07
这篇文章主要介绍了Python中zip()函数用法实例教程,对Python初学者有一定的借鉴价值,需要的朋友可以参考下2014-07-07
Python使用DrissionPage中ChromiumPage进行自动化网页操作
DrissionPage 作为一款轻量级且功能强大的浏览器自动化库,为开发者提供了丰富的功能支持,本文将使用DrissionPage中ChromiumPage进行自动化网页操作,希望对大家有所帮助2025-03-03 这篇文章主要介绍了python中实现词云图的示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12
这篇文章主要介绍了python中实现词云图的示例,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12 Python中的循环结构是编程中的重要组成部分,本文详细介绍这两种循环的使用方法、它们之间的差异以及如何选择合适的循环类型,此外,我还将介绍一些高级循环控制技巧,如列表推导式和生成器表达式,感兴趣的朋友一起看看吧2024-01-01
Python中的循环结构是编程中的重要组成部分,本文详细介绍这两种循环的使用方法、它们之间的差异以及如何选择合适的循环类型,此外,我还将介绍一些高级循环控制技巧,如列表推导式和生成器表达式,感兴趣的朋友一起看看吧2024-01-01










最新评论