
python爬虫今日热榜数据到txt文件的源码
更新时间:2021年02月23日 10:27:08 作者:一个超会写Bug的安太狼
这篇文章主要介绍了python爬虫今日热榜数据到txt文件的源码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
今日热榜:https://tophub.today/
爬取数据及保存格式:
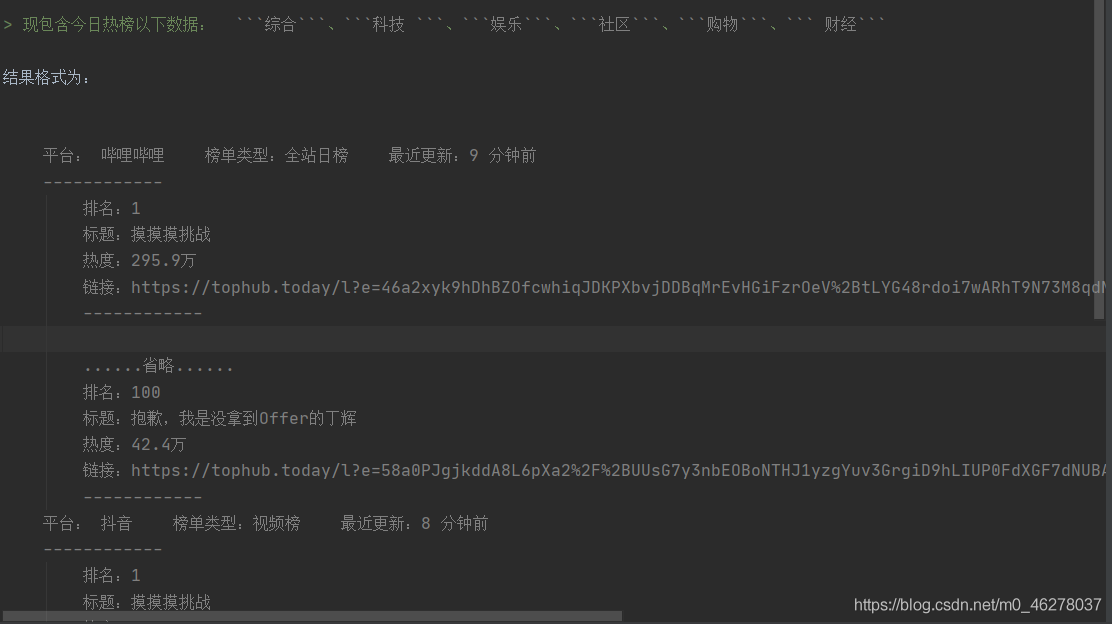
爬取后保存为.txt文件:
部分内容:
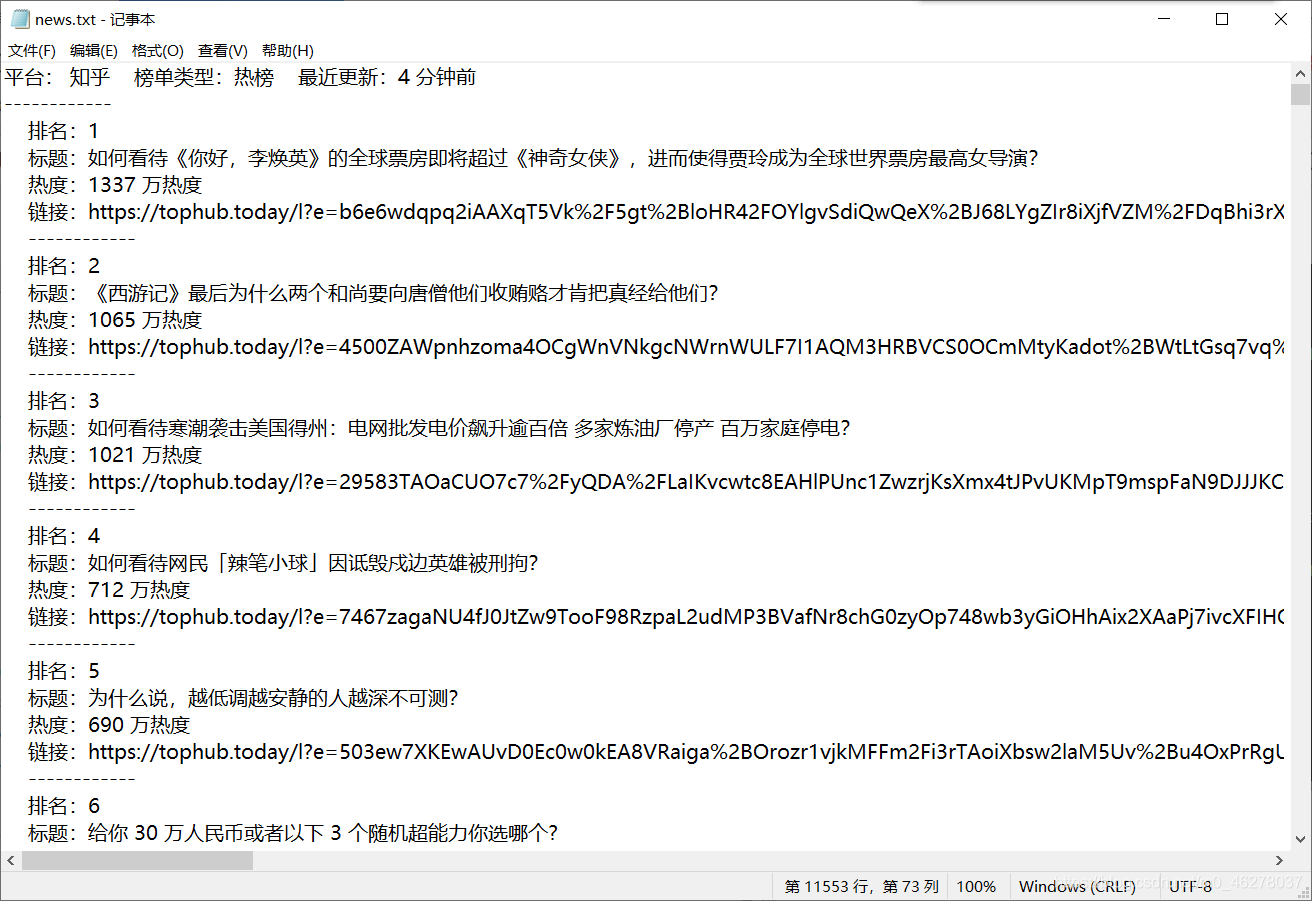
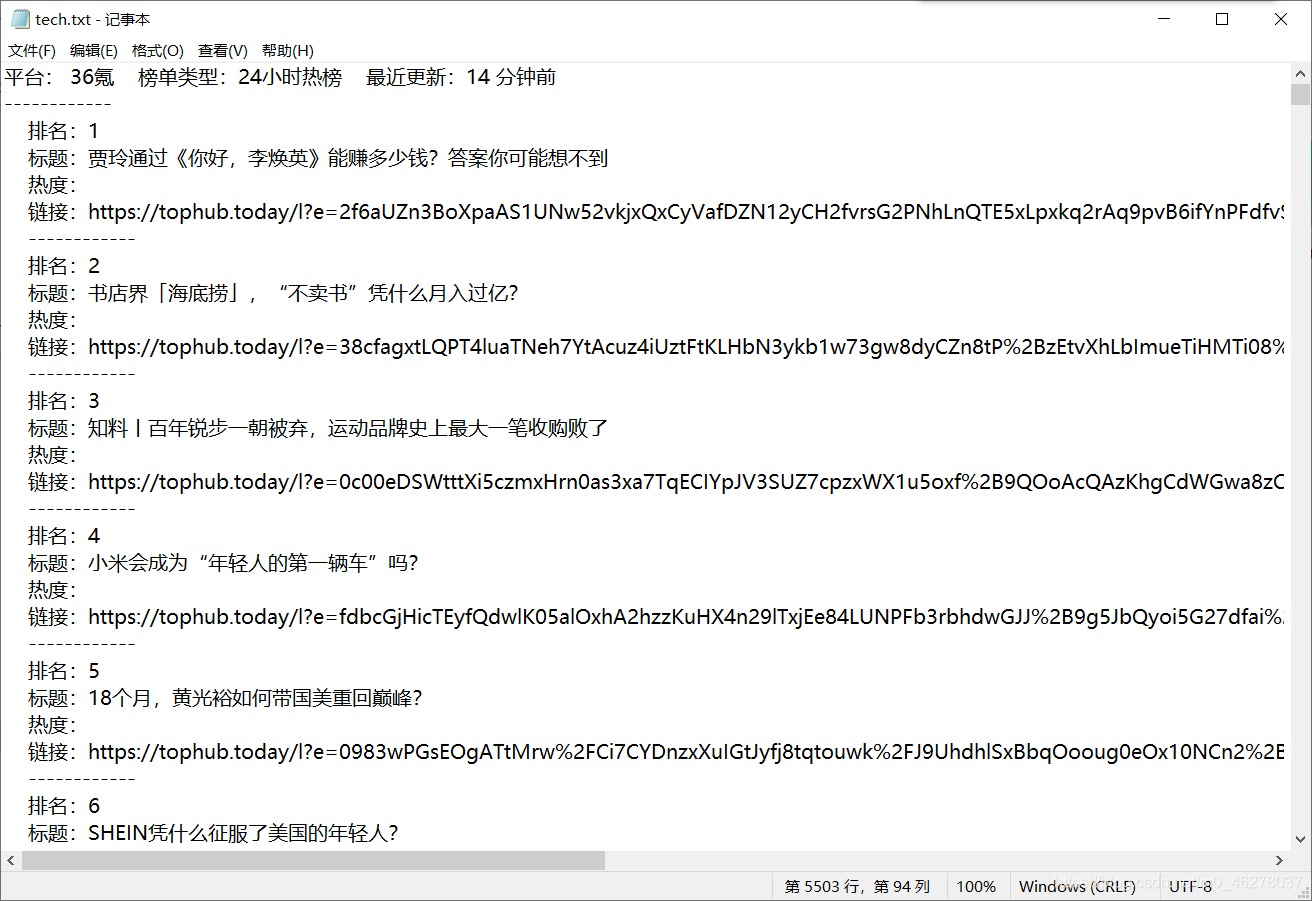
源码及注释:
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
try:
r = requests.get(url,timeout = 30,headers=headers)
return r.text
except:
return "please inspect your url or setup"
def get_content(html,tag):
output = """ 排名:{}\n 标题:{} \n 热度:{}\n 链接:{}\n ------------\n"""
output2 = """平台:{} 榜单类型:{} 最近更新:{}\n------------\n"""
num=[]
title=[]
hot=[]
href=[]
soup = BeautifulSoup(html, 'html.parser')
con = soup.find('div',attrs={'class':'bc-cc'})
con_list = con.find_all('div', class_="cc-cd")
for i in con_list:
author = i.find('div', class_='cc-cd-lb').get_text() # 获取平台名字
time = i.find('div', class_='i-h').get_text() # 获取最近更新
link = i.find('div', class_='cc-cd-cb-l').find_all('a') # 获取所有链接
gender = i.find('span', class_='cc-cd-sb-st').get_text() # 获取类型
save_txt(tag,output2.format(author, gender,time))
for k in link:
href.append(k['href'])
num.append(k.find('span', class_='s').get_text())
title.append(str(k.find('span', class_='t').get_text()))
hot.append(str(k.find('span', class_='e').get_text()))
for h in range(len(num)):
save_txt(tag,output.format(num[h], title[h], hot[h], href[h]))
def save_txt(tag,*args):
for i in args:
with open(tag+'.txt', 'a', encoding='utf-8') as f:
f.write(i)
def main():
# 综合 科技 娱乐 社区 购物 财经
page=['news','tech','ent','community','shopping','finance']
for tag in page:
url = 'https://tophub.today/c/{}'.format(tag)
html = download_page(url)
get_content(html,tag)
if __name__ == '__main__':
main()
到此这篇关于python爬虫今日热榜数据到txt文件的源码的文章就介绍到这了,更多相关python爬虫今日热榜数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

关于jupyter lab安装及导入tensorflow找不到模块的问题
这篇文章主要介绍了关于jupyter lab安装及导入tensorflow找不到模块的问题,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-03-03 今天给大家带来的是关于Python的相关知识,文章围绕着如何用Python将GIF动图分解成多张静态图片展开,文中有非常详细的介绍,需要的朋友可以参考下2021-06-06
今天给大家带来的是关于Python的相关知识,文章围绕着如何用Python将GIF动图分解成多张静态图片展开,文中有非常详细的介绍,需要的朋友可以参考下2021-06-06 这篇文章主要介绍了Pygame做一期吃豆子游戏的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要介绍了Pygame做一期吃豆子游戏的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03 Python的 eval() 允许从基于字符串或基于编译代码的输入中计算任意Python表达式。当从字符串或编译后的代码对象的任何输入中动态计算Python表达式时,此函数非常方便。本文将利用eval实现动态地计算数学表达式,需要的可以参考一下2022-09-09
Python的 eval() 允许从基于字符串或基于编译代码的输入中计算任意Python表达式。当从字符串或编译后的代码对象的任何输入中动态计算Python表达式时,此函数非常方便。本文将利用eval实现动态地计算数学表达式,需要的可以参考一下2022-09-09 本文主要介绍了Python中使用lambda函数进行排序的六种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-01-01
本文主要介绍了Python中使用lambda函数进行排序的六种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2025-01-01 这篇文章主要介绍了Python之Django基本命令 ,需要的朋友可以参考下2018-07-07
这篇文章主要介绍了Python之Django基本命令 ,需要的朋友可以参考下2018-07-07
Python eval()函数和ast.literal_eval()的区别你知道吗
这篇文章主要为大家详细介绍了Python eval()函数和ast.literal_eval()的区,文中图片代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-02-02 这篇文章主要介绍了Python如何实现一个简单的抽奖刮刮卡,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07
这篇文章主要介绍了Python如何实现一个简单的抽奖刮刮卡,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下2020-07-07 这篇文章主要为大家介绍了python神经网络使用slim函数进行模型的训练及保存模型示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了python神经网络使用slim函数进行模型的训练及保存模型示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
Python首次安装后运行报错(0xc000007b)的解决方法
最近在安装完Python后运行发现居然报错了,错误代码是0xc000007b,于是通过往上查找发现是因为首次安装Python缺乏VC++库的原因,下面通过这篇文章看看如何解决这个问题吧。2016-10-10










最新评论