
Django结合使用Scrapy爬取数据入库的方法示例
更新时间:2021年03月23日 10:47:19 作者:shiguanggege
这篇文章主要介绍了Django结合使用Scrapy爬取数据入库的方法示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
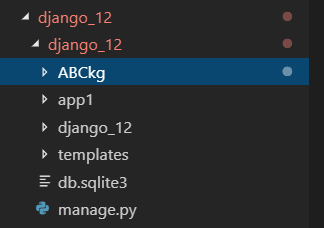
在django项目根目录位置创建scrapy项目,django_12是django项目,ABCkg是scrapy爬虫项目,app1是django的子应用
2.在Scrapy的settings.py中加入以下代码
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath('.')))
os.environ['DJANGO_SETTINGS_MODULE'] = 'django_12.settings' # 项目名.settings
import django
django.setup()
3.编写爬虫,下面代码以ABCkg为例,abckg.py
# -*- coding: utf-8 -*-
import scrapy
from ABCkg.items import AbckgItem
class AbckgSpider(scrapy.Spider):
name = 'abckg' #爬虫名称
allowed_domains = ['www.abckg.com'] # 允许爬取的范围
start_urls = ['http://www.abckg.com/'] # 第一次请求的地址
def parse(self, response):
print('返回内容:{}'.format(response))
"""
解析函数
:param response: 响应内容
:return:
"""
listtile = response.xpath('//*[@id="container"]/div/div/h2/a/text()').extract()
listurl = response.xpath('//*[@id="container"]/div/div/h2/a/@href').extract()
for index in range(len(listtile)):
item = AbckgItem()
item['title'] = listtile[index]
item['url'] = listurl[index]
yield scrapy.Request(url=listurl[index],callback=self.parse_content,method='GET',dont_filter=True,meta={'item':item})
# 获取下一页
nextpage = response.xpath('//*[@id="container"]/div[1]/div[10]/a[last()]/@href').extract_first()
print('即将请求:{}'.format(nextpage))
yield scrapy.Request(url=nextpage,callback=self.parse,method='GET',dont_filter=True)
# 获取详情页
def parse_content(self,response):
item = response.meta['item']
item['content'] = response.xpath('//*[@id="post-1192"]/dd/p').extract()
print('内容为:{}'.format(item))
yield item
4.scrapy中item.py 中引入django模型类
pip install scrapy-djangoitem
from app1 import models from scrapy_djangoitem import DjangoItem class AbckgItem(DjangoItem): # define the fields for your item here like: # name = scrapy.Field() # 普通scrapy爬虫写法 # title = scrapy.Field() # url = scrapy.Field() # content = scrapy.Field() django_model = models.ABCkg # 注入django项目的固定写法,必须起名为django_model =django中models.ABCkg表
5.pipelines.py中调用save()
import json
from pymongo import MongoClient
# 用于接收parse函数发过来的item
class AbckgPipeline(object):
# i = 0
def open_spider(self,spider):
# print('打开文件')
if spider.name == 'abckg':
self.f = open('abckg.json',mode='w')
def process_item(self, item, spider):
# # print('ABC管道接收:{}'.format(item))
# if spider.name == 'abckg':
# self.f.write(json.dumps(dict(item),ensure_ascii=False))
# # elif spider.name == 'cctv':
# # img = requests.get(item['img'])
# # if img != '':
# # with open('图片\%d.png'%self.i,mode='wb')as f:
# # f.write(img.content)
# # self.i += 1
item.save()
return item # 将item传给下一个管道执行
def close_spider(self,spider):
# print('关闭文件')
self.f.close()
6.在django中models.py中一个模型类,字段对应爬取到的数据,选择适当的类型与长度
class ABCkg(models.Model):
title = models.CharField(max_length=30,verbose_name='标题')
url = models.CharField(max_length=100,verbose_name='网址')
content = models.CharField(max_length=200,verbose_name='内容')
class Meta:
verbose_name_plural = '爬虫ABCkg'
def __str__(self):
return self.title
7.通过命令启动爬虫:scrapy crawl 爬虫名称
8.django进入admin后台即可看到爬取到的数据。
到此这篇关于Django结合使用Scrapy爬取数据入库的方法示例的文章就介绍到这了,更多相关Django Scrapy爬取数据入库内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了YOLOv5车牌识别实战教程(一)引言与准备工作,在这个教程中,我们将一步步教你如何使用YOLOv5进行车牌识别,帮助你快速掌握YOLOv5车牌识别技能,需要的朋友可以参考下2023-04-04
这篇文章主要介绍了YOLOv5车牌识别实战教程(一)引言与准备工作,在这个教程中,我们将一步步教你如何使用YOLOv5进行车牌识别,帮助你快速掌握YOLOv5车牌识别技能,需要的朋友可以参考下2023-04-04 这篇文章主要介绍了Python实现聚类K-means算法详解,K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差,具体详解需要的朋友可以参考一下2022-07-07
这篇文章主要介绍了Python实现聚类K-means算法详解,K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差,具体详解需要的朋友可以参考一下2022-07-07 这篇文章主要介绍了python PIL Image 图像处理基本操作实例包括图片加载、灰度图,图像通道分离和合并,在图像上输出文字,图像缩放,图像阈值分割、 二值化,图像裁剪需要的朋友可以参考下2022-04-04
这篇文章主要介绍了python PIL Image 图像处理基本操作实例包括图片加载、灰度图,图像通道分离和合并,在图像上输出文字,图像缩放,图像阈值分割、 二值化,图像裁剪需要的朋友可以参考下2022-04-04 这篇文章主要介绍了Django用户登录与注册系统的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06
这篇文章主要介绍了Django用户登录与注册系统的实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06 这篇文章主要为大家介绍了python数字图像处理之图像的批量处理示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06
这篇文章主要为大家介绍了python数字图像处理之图像的批量处理示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-06-06 这篇文章主要介绍了Python中获取当前文件路径和目录的方法,包括使用__file__关键字、os.path.abspath、os.path.realpath以及sys.path,文中还介绍了在使用这些函数时需要注意的事项,需要的朋友可以参考下2025-01-01
这篇文章主要介绍了Python中获取当前文件路径和目录的方法,包括使用__file__关键字、os.path.abspath、os.path.realpath以及sys.path,文中还介绍了在使用这些函数时需要注意的事项,需要的朋友可以参考下2025-01-01
Python使用cn2an实现中文数字与阿拉伯数字的相互转换
这篇文章主要介绍了Python使用cn2an实现中文数字与阿拉伯数字的相互转换,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03 从Python3.2引入的concurrent.futures模块,Python2.5以上需要在pypi中安装futures包。future指一种对象,表示异步执行的操作。这个概念的作用很大,是concurrent.futures模块和asyncio包的基础2023-02-02
从Python3.2引入的concurrent.futures模块,Python2.5以上需要在pypi中安装futures包。future指一种对象,表示异步执行的操作。这个概念的作用很大,是concurrent.futures模块和asyncio包的基础2023-02-02 这篇文章主要介绍了python数字图像处理之骨架提取与分水岭算法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-04-04
这篇文章主要介绍了python数字图像处理之骨架提取与分水岭算法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-04-04 这篇文章是python教程篇,主要为大家介绍了Python中命名元组的示例分析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2021-09-09
这篇文章是python教程篇,主要为大家介绍了Python中命名元组的示例分析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2021-09-09










最新评论