
Jmeter 使用Json提取请求数据的方法
使用Json提取器可以提取请求响应数据
Json提取器
位置: 后置处理器-》Json提取器
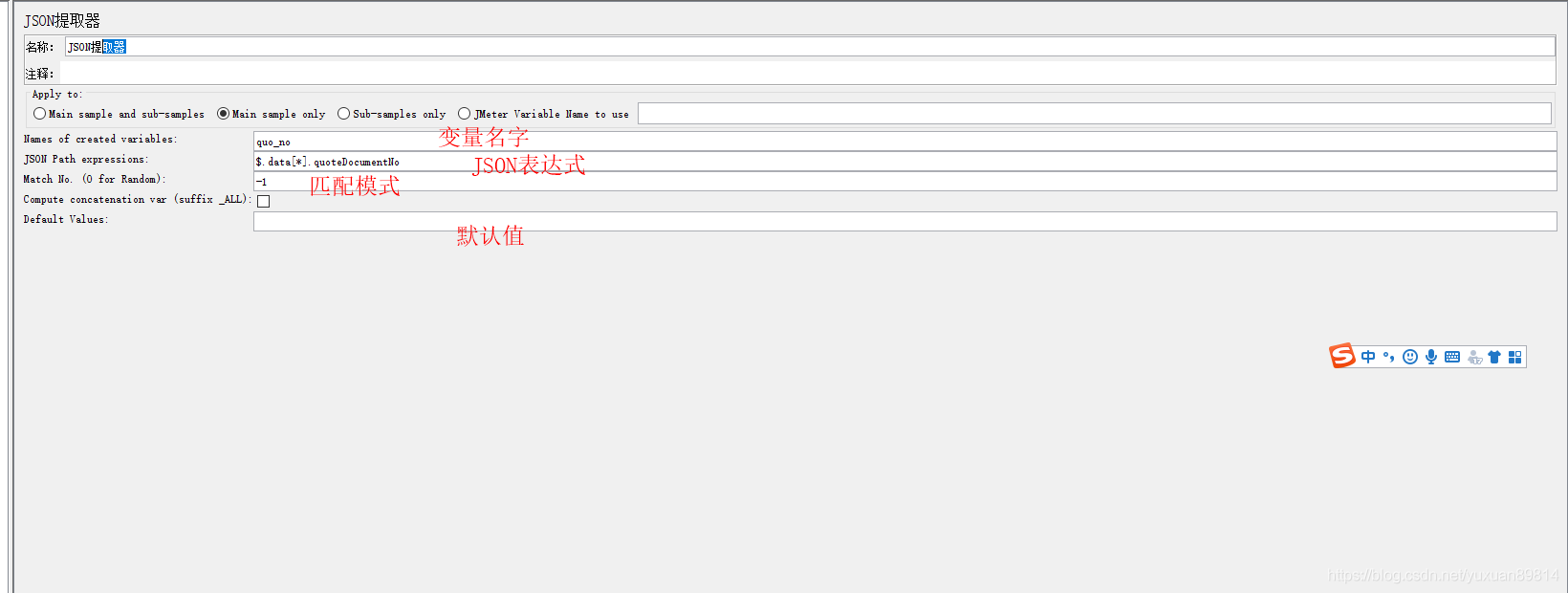
使用介绍
1,变量名
变量名,其他部分引用方式: ${变量名}
若提取多个变量,多个之间使用分号";"分割
2,Json表达式
$表示响应的根对象
.表示对象的下一级子对象或者属性
取数组加[],数组索引从0开始,*表示数组所有值
若响应结构为:{“code”:200,“resultMessage”:"",“data”:2}
$.data 表示取data这个对象若响应结构为:[{},{},{}]
$[1或者**] 1,2,3表示取数组第几个元素,*表示取所有若响应结构为:{“属性”:[{“sx”:1},{},{}]}
$.属性[0].sx
3,Match no
-1表示匹配所有
0表示随机取值
1表示匹配第一个,2表示匹配第二个
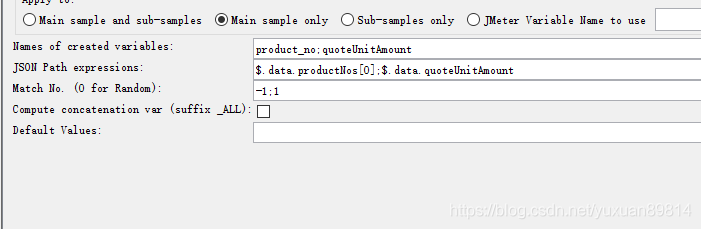
设置变量数量与match no个数要匹配得上,多个提取之间使用;分割
设置为-1时
会提取多个变量,单个变量的引用带具体数值,数字表示提取到的第几个变量。使用方式:${变量名_序列} 序列为1,2,3。。。。
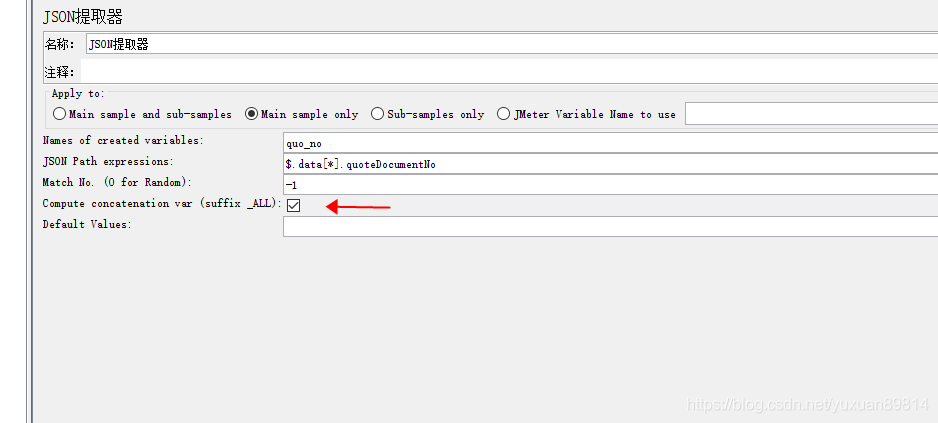
设置为-1时,生成其他相关变量
变量名_matchNr
意思是取到的符合条件的数字个数。可以像使用普通变量一样使用这个_matchNr变量。
变量名_ALL
若是勾选了 计算串联变量(Compute concatenation var(suffix _ALL))则还会生成以_ALL结尾的变量,表示所有变量组合的变量,以分号分割
设置为0或1,2,3等具体数值
取的是单个值,变量的使用是${变量名},不用加序列号
4,默认值
没有匹配上的默认值,取多个值时,可设置多个默认值,多个默认值之间分号分割
提取变量的后续操作
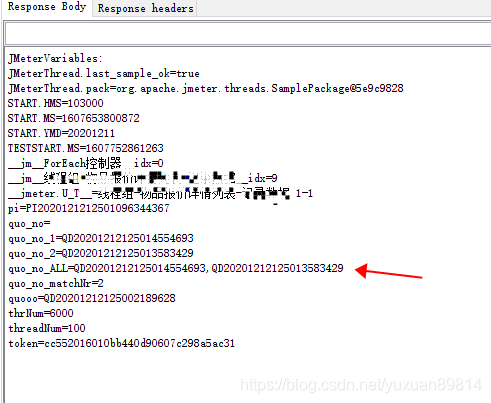
调试器样本查看变量取值情况
查看json提取的数据取值情况
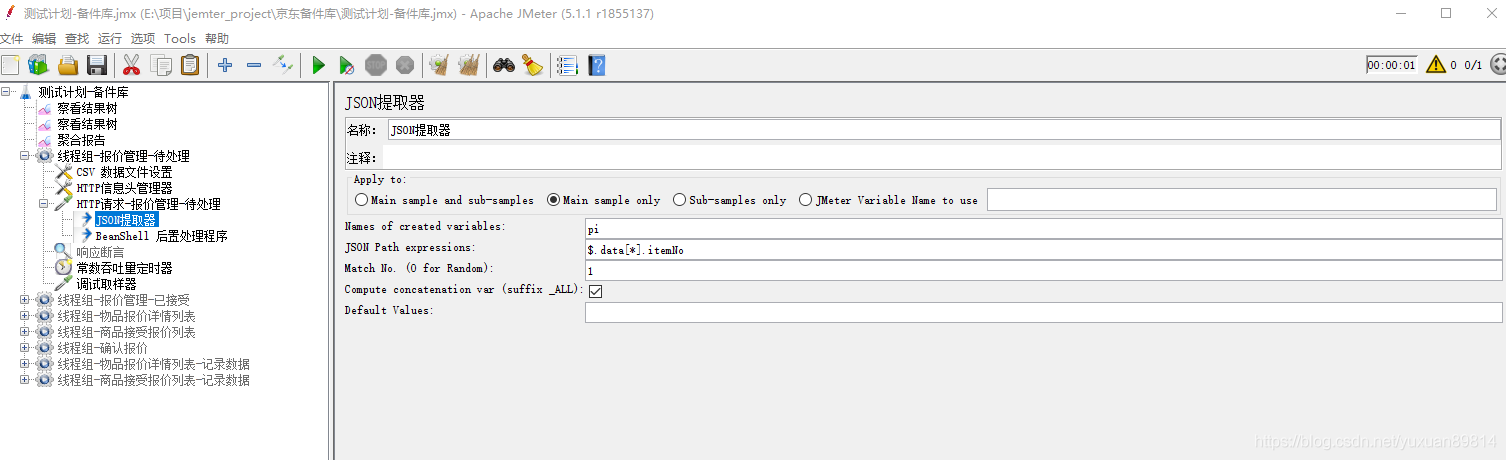
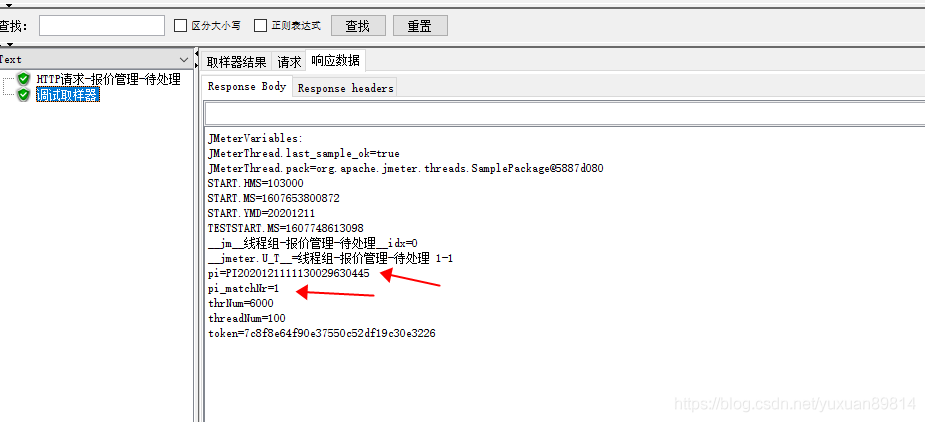
这里debug样本器提取了变量pi 还会生成pi_matchNr变量,表示这个变量提取了多少匹配的值。
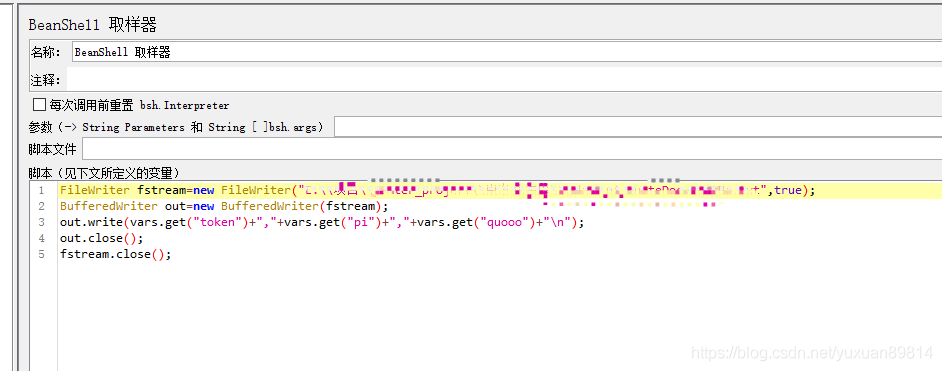
Beanshell写变量到文件
beanshell后置处理程序
若是请求之后,提取变量,写文件使用的是beanshell后置处理程序
beanshell取样器
非请求之后写入使用的是beanshell取样器
两种beanshell元件,其中代码暂时没有发现不同
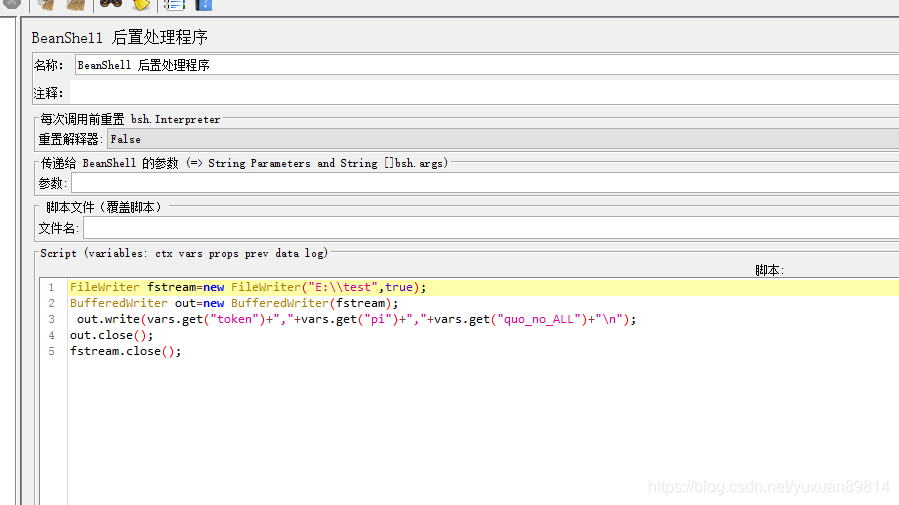
这是使用beanshell写入获取的quo_no的ALL变量quo_no_ALL ,写入文件后取值直接也是带分号的。
遍历提取到的值
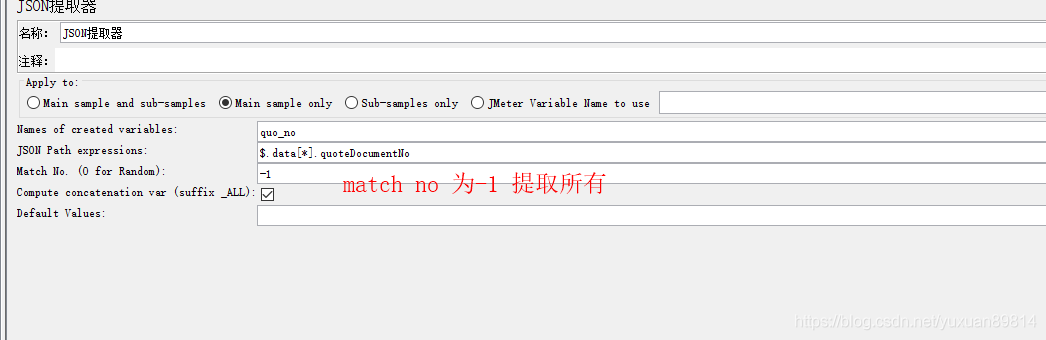
变量名为quo_no
match no为-1提取数组对象所有符合值
使用ForEach遍历器遍历获取的所有quo_no
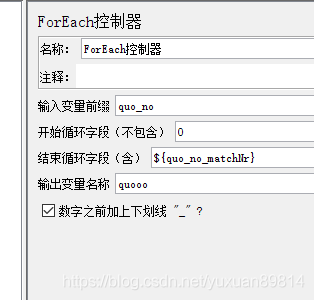
ForEach控制器,从0开始(不包括0),停止循环为 q u o n o m a t c h N r 输 出 变 量 名 设 置 好 q u o o o , 该 控 制 下 调 用 变 量 名 {quo_no_matchNr} 输出变量名设置好quooo,该控制下调用变量名 quonomatchNr输出变量名设置好quooo,该控制下调用变量名{quooo}
比如,本脚本是使用beanshell采样器去写文件
除了写文件还可以做其他处理,比如带上提取到的变量继续请求。
到此这篇关于Jmeter 使用Json提取请求数据的文章就介绍到这了,更多相关Jmeter Json提取请求数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 对于正则表达式,相信很多人都知道,但是很多人的第一感觉就是难学,因为看第一眼时,觉得完全没有规律可寻,其实也没有你想象的那么难,今天小编就通过本文带领大家一起去学习正则表达式知识2016-11-11
对于正则表达式,相信很多人都知道,但是很多人的第一感觉就是难学,因为看第一眼时,觉得完全没有规律可寻,其实也没有你想象的那么难,今天小编就通过本文带领大家一起去学习正则表达式知识2016-11-11 日常编程经常会用到正则表达式,躲不开这个陷阱,本文主要介绍了浅谈正则表达式回溯陷阱,具有一定的参考价值,感兴趣的可以了解一下2023-11-11
日常编程经常会用到正则表达式,躲不开这个陷阱,本文主要介绍了浅谈正则表达式回溯陷阱,具有一定的参考价值,感兴趣的可以了解一下2023-11-11 首先需要说明的一点,无论是Winform,还是Webform,都有很成熟的日历控件,无论从易用性还是可扩展性上看,日期的选择和校验还是用日历控件来实现比较好。</P><P>2009-07-07
首先需要说明的一点,无论是Winform,还是Webform,都有很成熟的日历控件,无论从易用性还是可扩展性上看,日期的选择和校验还是用日历控件来实现比较好。</P><P>2009-07-07 以下关于正则表达式的内容来自 MSDN 和维基百科,仅供自己查阅方便2012-06-06
以下关于正则表达式的内容来自 MSDN 和维基百科,仅供自己查阅方便2012-06-06 正则表达式,只匹配一次下化线!...2006-12-12
正则表达式,只匹配一次下化线!...2006-12-12 这篇文章主要介绍了正则表达式爬取京东商品信息并打包成.exe可执行程序的方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了正则表达式爬取京东商品信息并打包成.exe可执行程序的方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-08-08 正则表达式就是一个字符串,但和普通的字符串不同的是,正则表达式是对一组相似字符串的抽象。本文将给大家介绍java中使用正则表达式处理文本数据的相关的资料,感兴趣的朋友一起看看吧2015-10-10
正则表达式就是一个字符串,但和普通的字符串不同的是,正则表达式是对一组相似字符串的抽象。本文将给大家介绍java中使用正则表达式处理文本数据的相关的资料,感兴趣的朋友一起看看吧2015-10-10 呵呵,刚学习正则表达式,今天帮一个美女解决了个问题。感到很高兴。先贴下今天都学了什么吧。不然忘记了。2010-05-05
呵呵,刚学习正则表达式,今天帮一个美女解决了个问题。感到很高兴。先贴下今天都学了什么吧。不然忘记了。2010-05-05 这篇文章主要介绍了VS里的正则表达式的替换技巧,需要的朋友可以参考下2016-05-05
这篇文章主要介绍了VS里的正则表达式的替换技巧,需要的朋友可以参考下2016-05-05 正则表达式判断所填入号码的运营商js代码修改版,需要的朋友可以参考下2012-10-10
正则表达式判断所填入号码的运营商js代码修改版,需要的朋友可以参考下2012-10-10










最新评论