
python读取pdf格式文档的实现代码
更新时间:2021年04月01日 16:14:47 作者:十年如梦>
这篇文章主要给大家介绍了关于python读取pdf格式文档的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
python读取pdf文档
一、 准备工作
安装对应的库 pip install pdfminer3k pip install pdfminer.six
二、部分变量的含义
PDFDocument(pdf文档对象)
PDFPageInterpreter(解释器)
PDFParser(pdf文档分析器)
PDFResourceManager(资源管理器)
PDFPageAggregator(聚合器)
LAParams(参数分析器)
三、PDFMiner类之间的关系
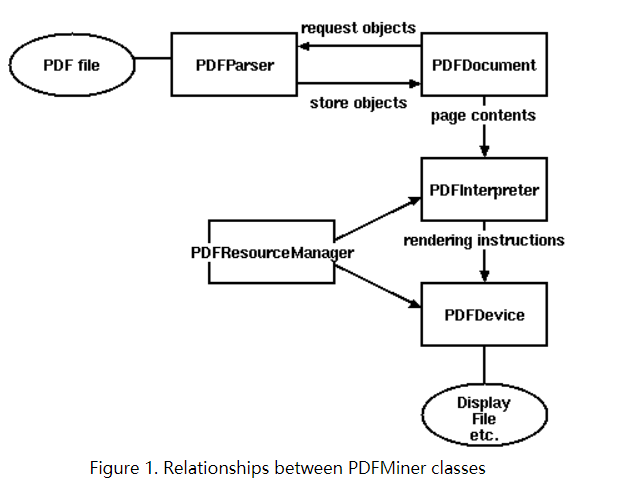
四、代码实现
#!/usr/bin/env python # -*- coding:utf-8 -*- # datetime:2021/3/17 12:12 # software: PyCharm # version: python 3.9.2 def changePdfToText(filePath): """ 解析pdf 文本,保存到同名txt文件中 param: filePath: 需要读取的pdf文档的目录 introduced module: from pdfminer.pdfpage import PDFPage from pdfminer.pdfparser import PDFParser from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LAParams from pdfminer.pdfdocument import PDFDocument, PDFTextExtractionNotAllowed import os.path """ file = open(filePath, 'rb') # 以二进制读模式打开 # 用文件对象来创建一个pdf文档分析器 praser = PDFParser(file) # 创建一个PDF文档 doc = PDFDocument(praser, '') # praser :上面创建的pdf文档分析器 ,第二个参数是密码,设置为空就好了 # 连接分析器 与文档对象 praser.set_document(doc) # 检测文档是否提供txt转换,不提供就忽略 if not doc.is_extractable: raise PDFTextExtractionNotAllowed # 创建PDf 资源管理器 来管理共享资源 rsrcmgr = PDFResourceManager() # 创建一个PDF设备对象 laparams = LAParams() device = PDFPageAggregator(rsrcmgr, laparams=laparams) # 创建一个PDF解释器对象 interpreter = PDFPageInterpreter(rsrcmgr, device) result = [] # 内容列表 # 循环遍历列表,每次处理一个page的内容 for page in PDFPage.create_pages(doc): interpreter.process_page(page) # 接受该页面的LTPage对象 layout = device.get_result() for x in layout: if hasattr(x, "get_text"): result.append(x.get_text()) fileNames = os.path.splitext(filePath) # 分割 # 以追加的方式打开文件 with open(fileNames[0] + '.txt', 'a', encoding="utf-8") as f: results = x.get_text() # print(results) 这个句可以取消注释就可以在控制台将所有内容输出了 f.write(results) # 写入文件 # 调用示例 : # path = u'E:\\1.pdf' # changePdfToText(path)
利用PyPDF2实现了对pdf文字内容的提取
from PyPDF2 import PdfFileReader
# 定义获取pdf内容的方法
def getPdfContent(filename):
# 获取PdfFileReader对象
pdf = PdfFileReader(open(filename, "rb"))
content = "" #content是输出文本
for i in range(0,pdf.getNumPages()): #遍历每一页
pageObj = pdf.getPage(i)
try:
extractedText = pageObj.extractText()#导出每一页的内容,如果当前页有图片的话就跳过
content += extractedText + "\n"
except BaseException:
pass
return content.encode("ascii", "ignore")
# 将获取的内容写入txt文件
with open("test.txt","w") as f:
count=0 #count的作用是限制每一行的文字个数,本人设置的是十行
#将获取的文本变成字符串并用空白隔开
for item in str(getPdfContent("test.pdf")).split(" "):
# 如果当前文字以句号结尾就换行
if item[-1]==".":
f.write(item+"\n")
count=0
else:
f.write(item+" ")
count +=1
# 如果写了十个字就换行
if count==10:
f.write("\n")
# 重置count
count = 0
总结
到此这篇关于python读取pdf格式文档的文章就介绍到这了,更多相关python读取pdf文档内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python中装饰器的理解与使用详解,装饰器本质上是一个闭包函数,其作用在于可以为其他函数增加额外功能,装饰器的返回值是一个函数对象,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了python中装饰器的理解与使用详解,装饰器本质上是一个闭包函数,其作用在于可以为其他函数增加额外功能,装饰器的返回值是一个函数对象,需要的朋友可以参考下2023-07-07 经常会看到以下划线或者双下划线开头的方法或者属性,到底它们有什么作用,又有什么样的区别呢?今天我们来总结一下,感兴趣的小伙伴们可以参考一下2019-04-04
经常会看到以下划线或者双下划线开头的方法或者属性,到底它们有什么作用,又有什么样的区别呢?今天我们来总结一下,感兴趣的小伙伴们可以参考一下2019-04-04 Inplace运算符的行为与普通运算符相似,只是在可变目标和不可变目标的情况下它们以不同的方式起作用。本文将通过示例带大家了解Inplace运算符的使用,需要的可以参考一下2022-09-09
Inplace运算符的行为与普通运算符相似,只是在可变目标和不可变目标的情况下它们以不同的方式起作用。本文将通过示例带大家了解Inplace运算符的使用,需要的可以参考一下2022-09-09 这篇文章主要为大家详细介绍了python实现flappy bird游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12
这篇文章主要为大家详细介绍了python实现flappy bird游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-12-12 循环器(iterator)是对象的容器,包含有多个对象。这篇文章主要介绍了python itertools用法,需要的朋友可以参考下2020-02-02
循环器(iterator)是对象的容器,包含有多个对象。这篇文章主要介绍了python itertools用法,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了Python借助with语句实现代码段只执行有限次,首先要定义一个能够在with语句中使用的类实现enter和exit,下文详细介绍需要的小伙伴可以参考一下2022-03-03
这篇文章主要介绍了Python借助with语句实现代码段只执行有限次,首先要定义一个能够在with语句中使用的类实现enter和exit,下文详细介绍需要的小伙伴可以参考一下2022-03-03 递归函数是直接调用自己或通过一系列语句间接调用自己的函数。递归在程序设计有着举足轻重的作用,在很多情况下,借助递归可以优雅的解决问题。本文主要介绍了如何利用可视化方式来了解递归函数的执行步骤,需要的可以参考一下2022-04-04
递归函数是直接调用自己或通过一系列语句间接调用自己的函数。递归在程序设计有着举足轻重的作用,在很多情况下,借助递归可以优雅的解决问题。本文主要介绍了如何利用可视化方式来了解递归函数的执行步骤,需要的可以参考一下2022-04-04
Python3.x+pycharm+Anaconda中缩小打包的.exe体积的问题
这篇文章主要介绍了Python3.x+pycharm+Anaconda中缩小打包的.exe体积的问题,本文通过图文实例相结合给大家分享解决方案,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了python从sqlite读取并显示数据的方法,涉及Python操作SQLite数据库的读取及显示相关技巧,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了python从sqlite读取并显示数据的方法,涉及Python操作SQLite数据库的读取及显示相关技巧,需要的朋友可以参考下2015-05-05 今天小编就为大家分享一篇使用NumPy和pandas对CSV文件进行写操作的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇使用NumPy和pandas对CSV文件进行写操作的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06










最新评论