
python urllib库的使用详解
相关:urllib是python内置的http请求库,本文介绍urllib三个模块:请求模块urllib.request、异常处理模块urllib.error、url解析模块urllib.parse。
1、请求模块:urllib.request
python2
import urllib2
response = urllib2.urlopen('http://httpbin.org/robots.txt')
python3
import urllib.request
res = urllib.request.urlopen('http://httpbin.org/robots.txt')
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen()方法中的url参数可以是字符串,也可以是一个Request对象
#url可以是字符串
import urllib.request
resp = urllib.request.urlopen('http://www.baidu.com')
print(resp.read().decode('utf-8')) # read()获取响应体的内容,内容是bytes字节流,需要转换成字符串
##url可以也是Request对象
import urllib.request
request = urllib.request.Request('http://httpbin.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
data参数:post请求
# coding:utf8
import urllib.request, urllib.parse
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
resp = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(resp.read())
urlopen()中的参数timeout:设置请求超时时间:
# coding:utf8
#设置请求超时时间
import urllib.request
resp = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
print(resp.read().decode('utf-8'))
响应类型:
# coding:utf8
#响应类型
import urllib.request
resp = urllib.request.urlopen('http://httpbin.org/get')
print(type(resp))
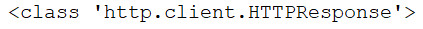
响应的状态码、响应头:
# coding:utf8
#响应的状态码、响应头
import urllib.request
resp = urllib.request.urlopen('http://www.baidu.com')
print(resp.status)
print(resp.getheaders()) # 数组(元组列表)
print(resp.getheader('Server')) # "Server"大小写不区分
200
[('Bdpagetype', '1'), ('Bdqid', '0xa6d873bb003836ce'), ('Cache-Control', 'private'), ('Content-Type', 'text/html'), ('Cxy_all', 'baidu+b8704ff7c06fb8466a83df26d7f0ad23'), ('Date', 'Sun, 21 Apr 2019 15:18:24 GMT'), ('Expires', 'Sun, 21 Apr 2019 15:18:03 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=8C61C3A67C1281B5952199E456EEC61E:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=8C61C3A67C1281B5952199E456EEC61E; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1555859904; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'delPer=0; path=/; domain=.baidu.com'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=0; path=/'), ('Set-Cookie', 'H_PS_PSSID=1452_28777_21078_28775_28722_28557_28838_28584_28604; path=/; domain=.baidu.com'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]
BWS/1.1
使用代理:urllib.request.ProxyHandler():
# coding:utf8
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
# This time, rather than install the OpenerDirector, we use it directly:
resp = opener.open('http://www.example.com/login.html')
print(resp.read())
2、异常处理模块:urllib.error
异常处理实例1:
# coding:utf8
from urllib import error, request
try:
resp = request.urlopen('http://www.blueflags.cn')
except error.URLError as e:
print(e.reason)
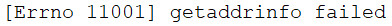
异常处理实例2:
# coding:utf8
from urllib import error, request
try:
resp = request.urlopen('http://www.baidu.com')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('request successfully')
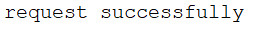
异常处理实例3:
# coding:utf8
import socket, urllib.request, urllib.error
try:
resp = urllib.request.urlopen('http://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason,socket.timeout):
print('time out')

3、url解析模块:urllib.parse
parse.urlencode
# coding:utf8
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'Host': 'httpbin.org',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
dict = {'name': 'Germey'}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "Thanlon"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "12",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
},
"json": null,
"origin": "117.136.78.194, 117.136.78.194",
"url": "https://httpbin.org/post"
}
add_header方法添加请求头:
# coding:utf8
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {'name': 'Thanlon'}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
parse.urlparse:
# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment')
print(type(result))
print(result)
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=1#comment', scheme='https')
print(type(result))
print(result)
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html', params='user', query='id=1', fragment='comment')
# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment', scheme='https')
print(result)
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
# coding:utf8
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment',allow_fragments=False)
print(result)
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
parse.urlunparse:
# coding:utf8 from urllib.parse import urlunparse data = ['http', 'www.baidu.com', 'index.html', 'user', 'name=Thanlon', 'comment'] print(urlunparse(data))

parse.urljoin:
# coding:utf8
from urllib.parse import urljoin
print(urljoin('http://www.bai.com', 'index.html'))
print(urljoin('http://www.baicu.com', 'https://www.thanlon.cn/index.html'))#以后面为基准

urlencode将字典对象转换成get请求的参数:
# coding:utf8
from urllib.parse import urlencode
params = {
'name': 'Thanlon',
'age': 22
}
baseUrl = 'http://www.thanlon.cn?'
url = baseUrl + urlencode(params)
print(url)
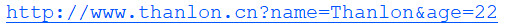
4、Cookie
cookie的获取(保持登录会话信息):
# coding:utf8
#cookie的获取(保持登录会话信息)
import urllib.request, http.cookiejar
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name + '=' + item.value)

MozillaCookieJar(filename)形式保存cookie
# coding:utf8
#将cookie保存为cookie.txt
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
LWPCookieJar(filename)形式保存cookie:
# coding:utf8
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
res = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
读取cookie请求,获取登陆后的信息
# coding:utf8
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
resp = opener.open('http://www.baidu.com')
print(resp.read().decode('utf-8'))
以上就是python urllib库的使用详解的详细内容,更多关于python urllib库的资料请关注脚本之家其它相关文章!
相关文章
 今天小编就为大家分享一篇查看端口并杀进程python脚本代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12
今天小编就为大家分享一篇查看端口并杀进程python脚本代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 本文主要介绍了Numpy数组的切片索引操作,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-06-06
本文主要介绍了Numpy数组的切片索引操作,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-06-06 将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。这篇文章主要介绍了Python使用Numpy实现Kmeans算法,需要的朋友可以参考下2021-11-11
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。这篇文章主要介绍了Python使用Numpy实现Kmeans算法,需要的朋友可以参考下2021-11-11 这篇文章主要介绍了Django 自定义404 500等错误页面的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-03-03
这篇文章主要介绍了Django 自定义404 500等错误页面的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-03-03 在Python开发中,文件路径的拼接是一个常见而且重要的任务,正确的路径拼接可以确保程序在不同平台上都能正常运行,本文将介绍Python中文件路径拼接的几种方式,包括使用os.path.join、os.path.join、pathlib库以及os.path.join2023-12-12
在Python开发中,文件路径的拼接是一个常见而且重要的任务,正确的路径拼接可以确保程序在不同平台上都能正常运行,本文将介绍Python中文件路径拼接的几种方式,包括使用os.path.join、os.path.join、pathlib库以及os.path.join2023-12-12 Python中Cryptography库给你的文件加把安全锁,本文主要介绍了Python中Cryptography库实现加密解密,具有一定的参考价值,感兴趣的可以了解一下2024-02-02
Python中Cryptography库给你的文件加把安全锁,本文主要介绍了Python中Cryptography库实现加密解密,具有一定的参考价值,感兴趣的可以了解一下2024-02-02 这篇文章主要介绍了Python使用pyh生成HTML文档的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-03-03
这篇文章主要介绍了Python使用pyh生成HTML文档的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-03-03 这篇文章主要为大家详细介绍了使用Python进行批量分割PDF文件的相关方法,我们将从架构设计入手,逐步讲解代码实现的过程,希望对大家有所帮助2023-11-11
这篇文章主要为大家详细介绍了使用Python进行批量分割PDF文件的相关方法,我们将从架构设计入手,逐步讲解代码实现的过程,希望对大家有所帮助2023-11-11 这篇文章主要介绍了pytorch多GPU并行运算的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09
这篇文章主要介绍了pytorch多GPU并行运算的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-09-09 这篇文章主要介绍了Python处理Excel表中单元格带有换行的数据问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06
这篇文章主要介绍了Python处理Excel表中单元格带有换行的数据问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06










最新评论