
Python爬取OPGG上英雄联盟英雄胜率及选取率信息的操作
本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics”

由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单
现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码)。通过查找“53.84%”快速定位Garen所在位置

由代码可看出,英雄名、胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tbody标签。
对tbody标签进行查找

代码中共有5个tbody标签(tbody标签开头结尾均有”tbody”,故共有10个”tbody”),对字段内容分析,分别为上单、打野、中单、ADC、辅助信息


以上单这部分英雄为例,我们需要首先找到tbody标签,然后从中找到tr标签(每一条tr标签就是一个英雄的信息),再从子标签td标签中获取英雄的详细信息
二、爬取步骤
爬取网站内容->提取所需信息->输出英雄数据
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
getHTMLText(url)函数是返回url链接中的html内容
fillHeroInformation(hlist,html)函数是将html中所需信息提取出存入hlist列表中
printHeroInformation(hlist)函数是输出hlist列表中的英雄信息
三、代码实现
1、getHTMLText(url)函数
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
2、fillHeroInformation(hlist,html)函数

以一个tr标签为例,tr标签内有7个td标签,第4个td标签内属性值为"champion-index-table__name"的div标签内容为英雄名,第5个td标签内容为胜率,第6个td标签内容为选取率,将这些信息存入hlist列表中
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
3、printHeroInformation(hlist)函数
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
4、main()函数
网站地址赋值给url,新建一个hlist列表,调用getHTMLText(url)函数获得html文档信息,使用fillHeroInformation(hlist,html)函数将英雄信息存入hlist列表,再使用printHeroInformation(hlist)函数输出信息
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
四、结果演示
1、网站界面信息


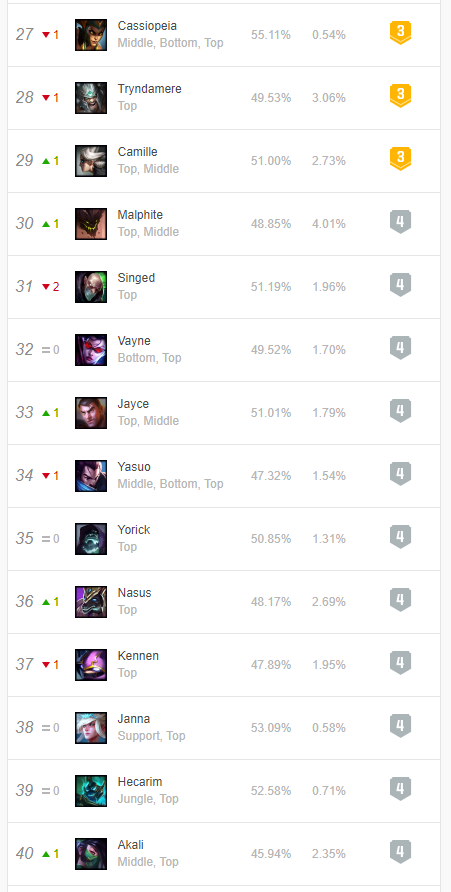

2、爬取结果


五、完整代码
import requests #导入requests库
import bs4 #导入bs4库
from bs4 import BeautifulSoup #导入BeautifulSoup库
def getHTMLText(url): #返回html文档信息
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #返回html内容
except:
return ""
def fillHeroInformation(hlist,html): #将英雄信息存入hlist列表
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍历上单tbody标签的儿子标签
if isinstance(tr,bs4.element.Tag): #判断tr是否为标签类型,去除空行
tds = tr('td') #查找tr标签下的td标签
heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
winRate = tds[4].string #胜率
pickRate = tds[5].string #选取率
hlist.append([heroName,winRate,pickRate]) #将英雄信息添加到hlist列表中
def printHeroInformation(hlist): #输出hlist列表信息
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","胜率","选取率","位置"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上单"))
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #获得html文档信息
fillHeroInformation(hlist,html) #将英雄信息写入hlist列表
printHeroInformation(hlist) #输出信息
main()
如果需要爬取打野、中单、ADC或者辅助信息,只需要修改
fillHeroInformation(hlist,html)
函数中的
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children语句
将attrs属性值修改为
"tabItem champion-trend-tier-JUNGLE"
"tabItem champion-trend-tier-MID"
"tabItem champion-trend-tier-ADC"
"tabItem champion-trend-tier-SUPPORT"
等即可!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
相关文章
 这篇文章主要介绍了关于Python中的排列组合生成器详解,在Python的内置模块 functools中,提供了高阶类 product() ,用于实现多个可迭代对象中元素的组合,返回可迭代对象中元素组合的笛卡尔积,效果相当于嵌套的循环,需要的朋友可以参考下2023-07-07
这篇文章主要介绍了关于Python中的排列组合生成器详解,在Python的内置模块 functools中,提供了高阶类 product() ,用于实现多个可迭代对象中元素的组合,返回可迭代对象中元素组合的笛卡尔积,效果相当于嵌套的循环,需要的朋友可以参考下2023-07-07 这篇文章主要介绍了python将图片文件转换成base64编码的方法,涉及Python操作base64编码的技巧,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了python将图片文件转换成base64编码的方法,涉及Python操作base64编码的技巧,需要的朋友可以参考下2015-03-03
使用keras实现densenet和Xception的模型融合
这篇文章主要介绍了使用keras实现densenet和Xception的模型融合,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
使用PyTorch/TensorFlow搭建简单全连接神经网络
在本篇博客中,我们将介绍如何使用两大深度学习框架——PyTorch 和 TensorFlow,构建一个简单的全连接神经网络,该网络包含输入层、一个隐藏层和输出层,适合初学者理解神经网络的基本构建模块及训练流程,需要的朋友可以参考下2025-02-02 这篇文章主要介绍了如何在浏览器前端运行Python程序的相关资料,在前端运行Python代码的多种方式,包括Pyodide、Brython、Transcrypt等,每种方式都有其特点和适用场景,文中通过代码介绍的非常详细,需要的朋友可以参考下2025-01-01
这篇文章主要介绍了如何在浏览器前端运行Python程序的相关资料,在前端运行Python代码的多种方式,包括Pyodide、Brython、Transcrypt等,每种方式都有其特点和适用场景,文中通过代码介绍的非常详细,需要的朋友可以参考下2025-01-01 本文给大家介绍了Python如何按要求从多个txt文本中提取指定数据,遍历文件夹并从中找到文件名称符合我们需求的多个.txt格式文本文件,文中有相关的代码示例供大家参考,具有一定的参考价值,需要的朋友可以参考下2023-12-12
本文给大家介绍了Python如何按要求从多个txt文本中提取指定数据,遍历文件夹并从中找到文件名称符合我们需求的多个.txt格式文本文件,文中有相关的代码示例供大家参考,具有一定的参考价值,需要的朋友可以参考下2023-12-12 这篇文章主要给大家介绍了关于Python 3.7新功能之dataclass装饰器的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2018-04-04
这篇文章主要给大家介绍了关于Python 3.7新功能之dataclass装饰器的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧。2018-04-04 这篇文章主要介绍了解决Windows下python和pip命令无法使用的问题,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了解决Windows下python和pip命令无法使用的问题,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08 这篇文章主要介绍了Pytorch实现图像识别之数字识别(附详细注释),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-05-05
这篇文章主要介绍了Pytorch实现图像识别之数字识别(附详细注释),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-05-05 感觉好久没和大家一起写小游戏玩了,今天恰巧有空.这次我们来用Python做个2048小游戏吧.废话不多说,文中有非常详细的代码示例,需要的朋友可以参考下2021-06-06
感觉好久没和大家一起写小游戏玩了,今天恰巧有空.这次我们来用Python做个2048小游戏吧.废话不多说,文中有非常详细的代码示例,需要的朋友可以参考下2021-06-06










最新评论